


Binärer Suchbaum
(mit Java-Code)
Es gibt nur eine Datenstruktur, mit der man schnell sowohl Elemente anhand ihres Schlüssels finden kann – als auch über die Elemente in Schlüsselreihenfolge iterieren kann: den binären Suchbaum!
In diesem Artikel erfährst du:
- Was ist ein binärer Suchbaum?
- Wie fügt man neue Elemente ein, wie sucht man sie, und wie löscht man sie wieder?
- Wie iteriert man über alle Elemente des binären Suchbaums?
- Wie implementiert man einen binären Suchbaum in Java?
- Welche Zeitkomplexität haben die Operationen des binären Suchbaums?
- Was unterscheidet den binären Suchbaum von ähnlichen Datenstrukturen?
Den Quellcode zum Artikel findest du in diesem GitHub-Repository.
Binärer Suchbaum Definiton
Ein binärer Suchbaum (englisch: binary search tree, abgekürzt: BST) ist ein Binärbaum, dessen Knoten einen Schlüssel (englisch: key) enthalten und in dem der linke Teilbaum eines Knotens nur Schlüssel enthält, die kleiner (oder gleich) als der Schlüssel des Elternknotens sind, und der rechte Teilbaum nur Schlüssel die größer (oder gleich) als der Schlüssel des Elternknotens sind.
Die Datenstruktur des binären Suchbaums ermöglicht es schnell¹ Schlüssel einzufügen, nachzuschlagen und zu entfernen (wie in einem Set in Java).
Um einen Knoten zu finden, muss man – bei der Wurzel beginnend – den Such-Schlüssel mit dem Knoten-Schlüssel vergleichen. Folgende drei Fälle können dabei eintreten:
- Der Such-Schlüssel ist gleich dem Knoten-Schlüssel: Der Zielknoten ist erreicht.
- Der Such-Schlüssel ist kleiner als der Knoten-Schlüssel: Die Suche muss im linken Teilbaum forgesetzt werden.
- Der Such-Schlüssel ist größer als der Knoten-Schlüssel: Die Suche muss im rechten Teilbaum forgesetzt werden.
Die Knoten können neben dem Schlüssel auch einen Wert (englisch: value) enthalten. Dann kann man nicht nur prüfen, ob der Binäre Suchbaum einen Schlüssel enthält, sondern dem Schlüssel auch einen Wert zuordnen und diesen über den Schlüssel wieder auslesen (entsprechend einer Map).
Die Anordnung der Knoten im Binären Suchbaum ermöglicht es außerdem sehr effizient über die Schlüssel und deren Werte in Schlüssel-Reihenfolge zu iterieren.
¹ "Schnell" heißt, dass im besten Fall die Zeitkomplexität O(log n) erreicht wird. Mehr dazu in den Abschnitten Balancierter Binärer Suchbaum und Zeitkomplexität.
Binärer Suchbaum Beispiel
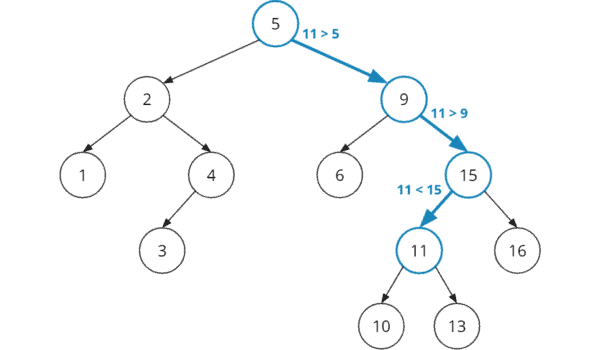
Hier siehst du ein Beispiel eines binären Suchbaums:

Um in diesem Beispiel die 11 zu finden, würde man wie folgt vorgehen:
- Schritt 1: Vergleich des Such-Schlüssels 11 mit dem Wurzel-Schlüssel 5. Die 11 ist größer, die Suche muss somit im rechten Teilbaum fortgesetzt werden.
- Schritt 2: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 9 (rechtes Kind der 5). Die 11 ist größer, die Suche muss im rechten Teilbaum unter der 9 fortgesetzt werden.
- Schritt 3: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 15 (rechtes Kind der 9). Die 11 ist kleiner, die Suche muss im linken Teilbaum unter der 15 fortgesetzt werden.
- Schritt 4: Vergleich des Such-Schlüssels 11 mit Knoten-Schlüssel 11 (linkes Kind der 15). Der gesuchte Knoten ist gefunden.
Im folgenden Diagramm sind die vier Schritte mit blau markierten Knoten und Kanten hervorgehoben:
Eigenschaften von binären Suchbäumen
Die wichtigste Eigenschaft eines Binären Suchbaums ist der schnelle Zugriff auf einen Knoten über dessen Schlüssel. Der Aufwand hierfür hängt von der Struktur des Baumes ab: Knoten, die nahe der Wurzel liegen, werden nach weniger Vergleichen gefunden als Knoten, die weit von der Wurzel entfernt sind.
Je nach Einsatzzweck des binären Suchbaums ergeben sich unterschiedliche Anforderungen an dessen Form. Für bestimmte Einsatzformen soll die Höhe des binären Suchbaums möglichst gering sein (s. Abschnitt Balancierter binärer Suchbaum).
Für andere Einsatzformen ist es wichtiger, dass häufig nachgeschlagene Schlüssel nahe an der Wurzel liegen, während die Tiefe von Knoten, auf die seltener zugegriffen wird, weniger ins Gewicht fällt (s. Abschnitt Optimaler binärer Suchbaum).
Balancierter binärer Suchbaum
Ein balancierter binärer Suchbaum ist ein binärer Suchbaum, in dem sich die linken und rechten Teilbäume eines jeden Knotens in der Höhe um maximal eins unterscheiden.
Der oben gezeigte Beispielbaum ist nicht balanciert. Der linke Teilbaum des Knotens "9" hat die Höhe eins und der rechte Teilbaum die Höhe drei. Die Höhendifferenz also größer als eins.
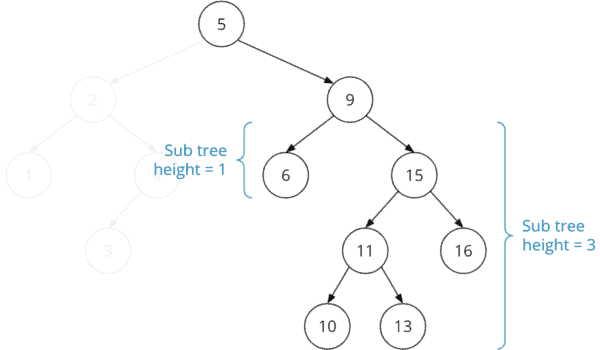
Wir können berechnen, wie viele Vergleiche wir in diesem Baum im Durchschnitt benötigen, um einen Schlüssel zu finden. Dazu multiplizieren wir auf jeder Knotenebene die Anzahl der Knoten mit der Anzahl der Vergleiche, die wir benötigen, um einen Knoten auf der entsprechenden Ebene zu erreichen:
| Anzahl Vergleiche (= Knotentiefe + 1) | Anzahl Knoten auf dieser Ebene | Anzahl Vergleiche auf dieser Ebene |
|---|---|---|
| 1 (Wurzel) | 1 (5) | 1 × 1 = 1 |
| 2 | 2 (2, 9) | 2 × 2 = 4 |
| 3 | 4 (1, 4, 6, 15) | 3 × 4 = 12 |
| 4 | 3 (3, 11, 16) | 4 × 3 = 12 |
| 5 | 2 (10, 13) | 5 × 2 = 10 |
| Summen: | 12 | 39 |
Wenn wir jeden Knoten genau einmal suchen würden, bräuchten wir in Summe 39 Vergleiche. 39 Vergleiche geteilt durch 12 Knoten = 3,25 Vergleiche pro Knoten. Im Durchschnitt brauchen wir also 3,25 Vergleiche, um einen Knoten zu finden.
Der folgende Beispielbaum enthält die gleichen Schlüssel, ist jedoch balanciert:

Wir führen die gleiche Berechnung für den balancierten Suchbaum durch:
| Anzahl Vergleiche (= Knotentiefe + 1) | Anzahl Knoten auf dieser Ebene | Anzahl Vergleiche auf dieser Ebene |
|---|---|---|
| 1 (Wurzel) | 1 (5) | 1 × 1 = 1 |
| 2 | 2 (2, 11) | 2 × 2 = 4 |
| 3 | 4 (1, 4, 9, 15) | 3 × 4 = 12 |
| 4 | 5 (3, 6, 10, 13, 16) | 4 × 5 = 20 |
| Summen: | 12 | 37 |
Im balancierten Baum benötigen wir nur noch 37 Vergleiche für 12 Knoten, das sind 3,08 Vergleiche pro Knoten.
Degenerierter Binärbaum
Die Struktur des binären Suchbaumes ergibt sich in erster Linie aus der Reihenfolge, in der die Knoten eingefügt und gelöscht werden. Im Extremfall – wenn die Knoten in auf- oder absteigender Reihenfolge eingefügt werden – könnte ein Baum wie der folgende entstehen:

Wenn – wie in diesem Beispiel – jeder innere Knoten genau ein Kind hat, eine Baumstruktur also gar nicht mehr erkennbar ist, spricht man von einem degenerierten Baum.
Wenn wir in diesem Baum jeden Knoten einmal suchen würden, kämen wir auf
1×1 (für die 1)
+ 1×2 (für die 2)
+ 1×3 (für die 3)
...
+ 1×10 (für die 13)
+ 1×11 (für die 15)
+ 1×12 (für die 16)
= 78 Vergleiche
... für 12 Knoten. Im Durchschnitt bräuchten wir also 78 / 12 = 6,5 Vergleiche, um einen beliebigen Schlüssel zu finden – also deutlich mehr als im zufällig angeordneten und im balancierten Suchbaum.
Selbstbalancierender binärer Suchbaum
Ein selbstbalancierender (auch höhen-balancierter) binärer Suchbaum kann beim Einfügen und Löschen von Schlüsseln den Baum so transformieren, dass die Höhe des Baumes möglichst klein gehalten wird.
"Möglichst klein" ist dabei nicht näher spezifiziert. Ein selbstbalancierender binärer Suchbaum muss also nicht zwingenderweise die Eigenschaften eines balancierten binären Suchbaums erreichen. (Die Höhendifferenz des linken und rechten Teilbaum eines Knotens darf also auch größer als eins sein.)
Da die Reorganisation des Baumes mit einem gewissen Zeit- und Platz-Overhead verbunden ist, gilt es eine Balance zwischen Aufwand und Ergebnis zu finden.
Es gibt zahlreiche Implementierungen von selbstbalancierenden binären Suchbäumen. Zu den bekanntesten gehören der AVL-Baum und der Rot-Schwarz-Baum.
Optimaler binärer Suchbaum
Im oben beschriebenen balancierten binären Suchbaum werden die durchschnittlichen Kosten für den Zugriff auf beliebige Knoten minimiert. Das ist dann sinnvoll, wenn die Suche nach allen Schlüsseln annähernd gleichverteilt (oder unbekannt) ist.
Es gibt auch Einsatzzwecke, in denen bekannt ist, dass auf bestimmte Knoten öfter zugegriffen wird als auf andere. Ein Beispiel wäre ein Wörterbuch, das zur Rechtschreibkontrolle verwendet wird. Auf die Knoten der häufig genutzten Wörter wird dabei öfter zugegriffen als auf die Knoten der selten genutzten Wörter.
Um die Suchkosten – also die Anzahl der Vergleiche – insgesamt zu minimieren, würde es also Sinn machen, Knoten mit häufig benutzten Wörtern näher an der Wurzel zu platzieren als Knoten mit selten genutzten Wörtern.
Wenn wir im Voraus wissen, wie oft (oder mit welcher Wahrscheinlichkeit) jeder Schlüssel des binären Suchbaums gesucht wird, können wir den Baum derart konstruieren, dass die Suchkosten für die Gesamtheit der Suchaufrufe minimal sind. Einen solchen Baum bezeichnet man als optimalen binären Suchbaum.
Optimaler binärer Suchbaum – Beispiel
Das folgende Beispiel zeigt an einem Wörterbuch mit ein paar Wörtern und deren Häufigkeiten in einem Textkorpus (Quelle: WaCky), wie sich die Gesamtkosten zwischen balanciertem und optimalen binären Suchbaum unterscheiden.
| Wort | Häufigkeit im Textkorpus |
|---|---|
| der | 41.943.869 |
| die | 38.527.491 |
| das | 11.839.666 |
| an | 5.932.812 |
| mehr | 2.332.783 |
| zeit | 1.163.141 |
| euro | 568.080 |
| eltern | 290.303 |
| nacht | 156.069 |
| sehr | 85.970 |
| plan | 59.900 |
| los | 26.990 |
Ein balancierter binärer Suchbaum mit den aufgelisteten Wörten könnte z. B. folgende Struktur haben:

Da wir wissen, wie oft die einzelnen Wörter nachgeschlagen werden, können wir die durchschnittlichen Kosten pro Aufruf berechnen:
| Anzahl Vergleiche (Knotentiefe + 1) | Worthäufigkeiten auf dieser Tiefe | Summe der Worthäufigkeiten auf dieser Tiefe | Anzahl Vergleiche × Summe der Worthäufigkeiten |
|---|---|---|---|
| 1 (Wurzel) | 568.080 (euro) | 568.080 | 1 × 568.080 = 568.080 |
| 2 | 41.943.869 (der) + 156.069 (nacht) | 42.099.938 | 2 × 42.099.938 = 84.199.876 |
| 3 | 11.839.666 (das) + 290.303 (eltern) + 2.332.783 (mehr) + 85.970 (sehr) | 14.548.722 | 3 × 14.548.722 = 43.646.166 |
| 4 | 5.932.812 (an) + 38.527.491 (die) + 26.990 (los) + 59.900 (plan) + 1.163.141 (zeit) | 45.710.334 | 4 × 45.710.334 = 182.841.336 |
| Summen: | 102.927.074 | 311.255.458 |
In diesem balancierten Baum benötigen wir durchschnittlich
311.255.458 / 102.927.074 = 3,02 Vergleiche pro Suche.
Es fällt auf, dass an der Baumwurzel das relativ selten benutzte Wort "euro" liegt. Häufig verwendete Wörter wie "die" und "das" hingegen liegen relativ weit unten im Baum.
Wenn wir den Baum dahingenend optimieren, dass häufig verwendete Wörter näher an der Wurzel liegen, erreichen wir folgende Struktur:

Dass dieser Baum nicht mehr balanciert ist, sieht man auf den ersten Blick. Dafür liegen die am häufigsten verwendeten Wörter "der", "die", "das" in den ersten zwei Ebenen des Baumes. Und die am seltensten benutzten Wörter "sehr", "plan" und "los" befinden sich sehr weit unten.
Berechnen wir noch einmal die durchschnittlichen Kosten:
| Anzahl Vergleiche (Knotentiefe + 1) | Worthäufigkeiten auf dieser Tiefe | Summe der Worthäufigkeiten auf dieser Tiefe | Anzahl Vergleiche × Summe der Worthäufigkeiten |
|---|---|---|---|
| 1 (Wurzel) | 41.943.869 (der) | 41.943.869 | 1 × 41.943.869 = 41.943.869 |
| 2 | 11.839.666 (das) + 38.527.491 (die) | 50.367.157 | 2×50.367.157 = 100.734.314 |
| 3 | 5.932.812 (an) + 2.332.783 (mehr) | 8.265.595 | 3 × 8.265.595 = 24.796.785 |
| 4 | 568.080 (euro) + 1.163.141 (zeit) | 1.731.221 | 4 × 1.731.221 = 6.924.884 |
| 5 | 290.303 (eltern) + 26.990 (los) + 156.069 (nacht) | 473.362 | 5 × 473.362 = 2.366.810 |
| 6 | 85.970 (sehr) | 85.970 | 6 × 85.970 = 515.820 |
| 7 | 59.900 (plan) | 59.900 | 7 × 59.900 = 419.300 |
| Summen: | 102.927.074 | 177.701.782 |
Im optimalen binären Suchbaum benötigen wir durchschnittlich
177.701.782 / 102.927.074 = 1,73 Vergleiche pro Suche.
Die Suche ist also fast doppelt so schnell wie im balancierten Baum.
Wie ein optimaler binären Suchbaum konstruiert wird, kannst du z. B. auf Techie Delight nachlesen.
Binärer Suchbaum in Java
Für die Implementierung des binären Suchbaums in Java verwenden wir die gleiche grundlegende Datenstruktur wie bei der Java-Implementierung des Binärbaums.
Knoten werden in der Klasse Node definiert. Den Schlüssel speichern wir im Feld data. Der Einfachheit halber verwenden wir int-Primitive anstatt konkreter oder generischer Klassen.
public class Node {
int data;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
}Code-Sprache: Java (java)Da wir in diesem Artikel – und im weiteren Verlauf der Tutorial-Serie – verschiedene Arten von binären Suchbäumen implementieren werden, definieren wir ein Interface BinarySearchTree. Dieses erweitert das im ersten Teil der Serie angelegte Interface BinaryTree (welches lediglich die Methode getRoot() bereitstellt):
public interface BinaryTree {
Node getRoot();
}
public interface BinarySearchTree extends BinaryTree {
// operations will be added soon...
}Code-Sprache: Java (java)Im Verlauf dieses Artikels wird das BinarySearchTree-Interface von folgenden zwei Klassen implementiert werden:
BinarySearchTreeIterative– eine iterative Implementierung des binären SuchbaumsBinarySearchTreeRecursive– eine rekursive Implementierung des binären Suchbaums
Beide Klassen erweitern BaseBinaryTree, eine Minimal-Implementierung des Binärbaums, die nur die Referenz auf den Wurzelknoten enthält:
public class BaseBinaryTree implements BinaryTree {
protected Node root;
@Override
public Node getRoot() {
return root;
}
}
public class BinarySearchTreeIterative extends BaseBinaryTree
implements BinarySearchTree {
// operations will be added soon...
}
public class BinarySearchTreeRecursive extends BaseBinaryTree
implements BinarySearchTree {
// operations will be added soon...
}Code-Sprache: Java (java)Das folgende UML-Klassendiagramm zeigt die angelegten Interfaces und Klassen für die Binäre-Suchbaum-Datenstruktur:

Wundere dich nicht, dass das BinarySearchTree-Interface und die implementierenden Klassen noch leer sind – das wird nicht lange so bleiben. In den folgenden Abschnitten werde ich die verschiedenen Operationen auf binären Suchbäumen vorstellen und schrittweise dem Code hinzufügen.
Operationen auf binären Suchbäumen
Binäre Suchbäume bieten Operationen zum Einfügen, Löschen und Suchen von Schlüsseln (und ggf. damit verknüpften Werten) an, sowie zum Traversieren über alle Elemente.
Suche im binären Suchbaum
Wie die Suche funktioniert, habe ich in der Einführung und anhand eines Beispiels detailliert gezeigt. Zusammengefasst: wir vergleichen den Such-Schlüssel mit den Knoten-Schlüsseln beginnend an der Wurzel und folgen wiederholt dem linken oder rechten Kindknoten, je nachdem, ob der Such-Schlüssel kleiner oder größer als der jeweilige Knoten-Schlüssel ist – solange bis wir den Knoten mit dem gesuchten Schlüssel gefunden haben.
Suche im binären Suchbaum – Java-Quellcode (rekursiv)
Der Java-Code für die Suche im BST (Abkürzung für "binary search tree") kann rekursiv und iterativ implementiert werden. Beide Varianten sind unkompliziert. Die rekursive Variante findest du in der Klasse BinarySearchTreeRecursive ab Zeile 10:
public Node searchNode(int key) {
return searchNode(key, root);
}
private Node searchNode(int key, Node node) {
if (node == null) {
return null;
}
if (key == node.data) {
return node;
} else if (key < node.data) {
return searchNode(key, node.left);
} else {
return searchNode(key, node.right);
}
}Code-Sprache: Java (java)Der Code sollte selbsterklärend sein.
Suche im binären Suchbaum – Java-Quellcode (iterativ)
Ebenso einfach ist die iterative Variante (BinarySearchTreeIterative ab Zeile 10). Anstatt die Suche rekursiv auf den Teilbäumen aufzurufen, wandert die node-Referenz entlang der betrachteten Knoten, bis derjenige mit dem gesuchten Schlüssel gefunden und zurückgegeben wird.
public Node searchNode(int key) {
Node node = root;
while (node != null) {
if (key == node.data) {
return node;
} else if (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
return null;
}Code-Sprache: Java (java)Einfügen im binären Suchbaum
Beim Einfügen eines Schlüssels in den binären Suchbaum muss sichergestellt werden, dass die Reihenfolge der Schlüssel erhalten bleibt. Wie genau das erreicht wird, hängt von der konkreten Implementierung ab. Selbstbalancierende binäre Suchbäume setzen hier komplexe Algorithmen ein, auf die ich in späteren Artikeln der Serie eingehen werde.
Wir implementieren zunächst einen nicht selbstbalancierenden Suchbaum, der keine Duplikate zulässt. Das Einfügen neuer Schlüssel funktioniert wie folgt:
Genau wie bei der Suche folgen wir den Knoten – beginnend bei der Wurzel – nach links, wenn der einzufügende Schlüssel kleiner als der Knoten-Schlüssel ist, und nach rechts, wenn der einzufügende Schlüssel größer als der Knoten-Schlüssel ist. Irgendwann erreichen wir einen Blatt-Knoten. Ist der einzufügende Schlüssel kleiner als der Blatt-Schlüssel, fügen wir einen neuen Knoten als linkes Kind des Blatts ein; ist der einzufügende Schlüssel größer als der Blatt-Schlüssel, fügen wir den neuen Knoten als rechtes Kind ein.
(Sollten wir bei diesem Prozess einen Knoten finden, dessen Schlüssel der gleiche ist wie der einzufügende Schlüssel, dann quittieren wir den Einfügeversuch mit einer Fehlermeldung. Denn Duplikate sind nicht erlaubt.)
Das folgende Diagramm zeigt, wie wir in den Beispielbaum vom Beginn des Artikels den Schlüssel 8 einfügen:

Die Einfüge-Operation geht dabei wie folgt vor:
- Sie vergleicht die 8 mit dem Wurzel-Schlüssel 5. Die 8 ist größer, sie fährt daher beim rechten Kind der Wurzel, also der 9, fort.
- Sie vergleicht die 8 mit der 9. Die 8 ist kleiner, die Operation wandert daher zum linken Kind der 9, also der 6.
- Sie vergleicht die 8 mit der 6. Die 8 ist größer. Die 6 hat kein rechtes Kind. Die Operation hängt daher einen neuen Knoten mit dem einzufügenden Schlüssel 8 als rechtes Kind an die 6 an.
Einfügen im binären Suchbaum – Java-Quellcode (iterativ)
Auch das Einfügen können wir sowohl rekursiv als auch iterativ implementieren. Ich beginne mit der iterativen Implementierung. Diese ist zwar etwas länger, dafür einfacher zu verstehen als die rekursive Variante. Die iterative Einfüge-Operation findest du in BinarySearchTreeIterative ab Zeile 26:
public void insertNode(int key) {
Node newNode = new Node(key);
if (root == null) {
root = newNode;
return;
}
Node node = root;
while (true) {
// Traverse the tree to the left or right depending on the key
if (key < node.data) {
if (node.left != null) {
// Left sub-tree exists --> follow
node = node.left;
} else {
// Left sub-tree does not exist --> insert new node as left child
node.left = newNode;
return;
}
} else if (key > node.data) {
if (node.right != null) {
// Right sub-tree exists --> follow
node = node.right;
} else {
// Right sub-tree does not exist --> insert new node as right child
node.right = newNode;
return;
}
} else {
throw new IllegalArgumentException("BST already contains a node with key " + key);
}
}
}Code-Sprache: Java (java)Wir beginnen mit dem Erstellen des neuen Knotens. Wenn der Wurzelknoten noch nicht gesetzt ist, setzen wir diesen auf den neuen Knoten.
Andernfalls folgen wir in der while-Schleife den Knoten von der Wurzel beginnend, bis wir denjenigen Knoten finden, unter dem der neue Knoten als linkes oder rechtes Kind einzufügen ist. Das eigentliche Einfügen erledigen wir gleich mit in der Schleife, da wir an der entsprechenden Stelle noch wissen, ob der neue Knoten als linkes oder rechtes Kind eingefügt werden soll.
Einfügen im binären Suchbaum – Java-Quellcode (rekursiv)
Die deutlich kürzere, rekursive Lösung findest du in BinarySearchTreeRecursive ab Zeile 29:
public void insertNode(int key) {
root = insertNode(key, root);
}
Node insertNode(int key, Node node) {
// No node at current position --> store new node at current position
if (node == null) {
node = new Node(key);
}
// Otherwise, traverse the tree to the left or right depending on the key
else if (key < node.data) {
node.left = insertNode(key, node.left);
} else if (key > node.data) {
node.right = insertNode(key, node.right);
} else {
throw new IllegalArgumentException("BST already contains a node with key " + key);
}
return node;
}Code-Sprache: Java (java)Bei dieser Variante suchen wir die Einfügeposition rekursiv. Die rekursive Methode liefert den neuen Knoten zurück, wenn die Methode auf einer null-Referenz aufgerufen wurde. Der Aufrufer setzt dann die Referenz node.left oder node.right auf den zurückgegebenen Knoten.
Wird die rekursive Methode hingegen auf einem existierenden Knoten aufgerufen, wird (nach weiterem Abstieg in und Aufstieg aus der Rekursion) genau dieser wieder zurückgegeben. Die Zuweisung zu node.left bzw. node.right hat in diesem Fall keine Änderung zur Folge.
Löschen im binären Suchbaum
Genau wie beim Einfügen von Knoten hängt auch beim Löschen die konkrete Vorgehensweise von der Implementation ab. Selbstbalancierende Suchbäume verwenden komplexe Algorithmen, um die Balance aufrechtzuerhalten. Wir implementieren zunächst eine einfache Lösung. Dabei müssen wir – wie auch bei Binärbäumen im Allgemeinen – drei Fälle unterscheiden:
Fall A: Knoten ohne Kinder (Blatt) löschen
Liegt der zu löschende Schlüssel auf einem Blatt, dann können wir dieses einfach aus dem Baum entfernen. Die Reihenfolge der restlichen Knoten ändert sich dadurch nicht. Dazu setzen wir die left- oder right-Referenz des Elternknotens, die auf den zu löschenden Knoten zeigt, auf null.
Im folgenden Beispiel entfernen wir die den Knoten mit dem Schlüssel 10 aus dem Beispielbaum dieses Artikels. Das Diagramm zeigt der Übersicht halber nur den rechten Teilbaum an:

Fall B: Knoten mit einem Kind (Halbblatt) löschen
Wollen wir einen Knoten im binären Suchbaum löschen, der genau ein Kind hat, dann rückt das Kind an die gelöschte Position auf. Auch dabei bleibt die Reihenfolge aller anderen Knoten erhalten.
Das folgende Beispiel zeigt, wie wir nach dem Löschen der 10 im vorherigen Schritt nun auch den Knoten mit dem Schlüssel 11 löschen. Wir setzen die left- oder right-Referenz des Elternknotens (im Beispiel 15) auf das Kind des gelöschten Knotens (im Beispiel 13).
Die 13 rückt dadurch an die gelöschte Position auf:

Fall C: Knoten mit zwei Kindern löschen
Wenn wir einen Knoten aus einem binären Suchbaum löschen wollen, der zwei Kinder hat, wird es etwas komplizierter. Ein verbreiteter Ansatz ist der folgende:
- Wir ermitteln im rechten Teilbaum den Knoten mit dem kleinsten Schlüssel. Dies ist der sogenannte "In-order-Nachfolger" des zu löschenden Knotens.
- Wir kopieren die Daten des In-order-Nachfolgers in den zu löschenden Knoten.
- Wir entfernen den In-order-Nachfolger aus dem rechten Teilbaum. Da dies der Knoten mit dem kleinsten Schlüssel des rechten Teilbaums ist, kann er kein linkes Kind haben. Er hat also entweder gar kein Kind oder nur ein rechtes. Entsprechend können wir den In-order-Nachfolger wie in Fall A oder B entfernen.
Im folgenden Beispiel löschen wir den Wurzelknoten 5, indem In-order-Nachfolger 6 dessen Position einnimmt:

Alternativ kann natürlich auch der In-order-Vorgänger des linken Teilbaums an die Stelle des gelöschten Knotens tretens. Eine intelligente Auswahl von In-order-Vorgänger oder -Nachfolger erhöht die Wahrscheinlichkeit, dass der Baum einigermaßen ausbalanciert wird (und bleibt).
Löschen im binären Suchbaum – Java-Quellcode (rekursiv)
Wie alle anderen Operationen, kann auch das Löschen aus dem binären Suchbaum rekursiv und iterativ implementiert werden. Wenn Du die rekusive Methode zum Einfügen verstanden hast, wird es einfacher sein, auch beim Löschen mit der rekursiven Methode zu beginnen. Du findest sie in BinarySearchTreeRecursive ab Zeile 52:
public void deleteNode(int key) {
root = deleteNode(key, root);
}
Node deleteNode(int key, Node node) {
// No node at current position --> go up the recursion
if (node == null) {
return null;
}
// Traverse the tree to the left or right depending on the key
if (key < node.data) {
node.left = deleteNode(key, node.left);
} else if (key > node.data) {
node.right = deleteNode(key, node.right);
}
// At this point, "node" is the node to be deleted
// Node has no children --> just delete it
else if (node.left == null && node.right == null) {
node = null;
}
// Node has only one child --> replace node by its single child
else if (node.left == null) {
node = node.right;
} else if (node.right == null) {
node = node.left;
}
// Node has two children
else {
deleteNodeWithTwoChildren(node);
}
return node;
}Code-Sprache: Java (java)In den ersten Zeilen (bis zum Kommentar "At this point...") suchen wir die Löschposition, indem wir die Löschmethode rekursiv aufrufen, wenn der zu löschende Schlüssel kleiner oder größer als der des gerade betrachteten Knotens ist.
Haben wir den zu löschenden Knoten gefunden und hat dieser keine Kinder, gibt die Methode null zurück. Der Aufrufer setzt dann die left- oder right-Referenz des Parent-Knotens entsprechend auf null.
Hat der zu löschende Knoten genau ein Kind, wird eben dieses Kind zurückgegeben. Der Aufrufer setzt die left- oder right-Referenz des Parent-Knotens auf das zurückgegebene Kind. Als Folge dessen ist der zu löschende Knoten aus dem Baum entfernt.
Hat der zu löschende Knoten zwei Kinder, wird die folgende Methode aufgerufen:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = findMinimum(node.right);
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor recursively
node.right = deleteNode(inOrderSuccessor.data, node.right);
}
private Node findMinimum(Node node) {
while (node.left != null) {
node = node.left;
}
return node;
}Code-Sprache: GLSL (glsl)Zuerst wird über die findMinimum()-Methode der In-order-Nachfolger gesucht. Dessen Daten werden in den zu löschenden Knoten kopiert. Danach wird der In-order-Nachfolger durch rekursiven Aufruf von deleteNode() aus dem rechten Teilbaum des zu löschenden Knoten entfernt.
Löschen im binären Suchbaum – Java-Quellcode (iterativ)
Die iterative Methode ist deutlich länger, da wir zum Löschen des In-order-Nachfolgers nicht einfach die Lösch-Methode rekursiv aufrufen können. Du findest die iterative Implementierung in BinarySearchTreeIterative ab Zeile 62:
public void deleteNode(int key) {
Node node = root;
Node parent = null;
// Find the node to be deleted
while (node != null && node.data != key) {
// Traverse the tree to the left or right depending on the key
parent = node;
if (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
// Node not found?
if (node == null) {
return;
}
// At this point, "node" is the node to be deleted
// Node has at most one child --> replace node by its single child
if (node.left == null || node.right == null) {
deleteNodeWithZeroOrOneChild(key, node, parent);
}
// Node has two children
else {
deleteNodeWithTwoChildren(node);
}
}Code-Sprache: Java (java)In der ersten Hälfte der Methode (bis zum Kommentar "At this point...") wird – genau wie beim iterativen Suchen und Einfügen – der zu löschende Knoten gesucht. Dabei merken wir uns dessen Elternknoten.
Ein Blatt oder Halbblatt wird dann mit der Methode deleteNodeWithZeroOrOneChild() entfernt:
private void deleteNodeWithZeroOrOneChild(int key, Node node, Node parent) {
Node singleChild = node.left != null ? node.left : node.right;
if (node == root) {
root = singleChild;
} else if (key < parent.data) {
parent.left = singleChild;
} else {
parent.right = singleChild;
}
}Code-Sprache: Java (java)Je nachdem, ob der zu löschende Knoten linkes oder rechtes Kind seines Parents ist, wird die left- oder right-Referenz des Parents auf das verbleibende Kind des zu löschenden Knotens gesetzt. Hat der zu löschende Knoten kein Kind, dann ist child gleich null, und entsprechend wird auch die left- oder right-Referenz des Parents auf null gesetzt.
Hat der zu löschende Knoten zwei Kinder, dann wird die Methode deleteNodeWithTwoChildren() aufgerufen:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = node.right;
Node inOrderSuccessorParent = node;
while (inOrderSuccessor.left != null) {
inOrderSuccessorParent = inOrderSuccessor;
inOrderSuccessor = inOrderSuccessor.left;
}
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor
// Case a) Inorder successor is the deleted node's right child
if (inOrderSuccessor == node.right) {
// --> Replace right child with inorder successor's right child
node.right = inOrderSuccessor.right;
}
// Case b) Inorder successor is further down, meaning, it's a left child
else {
// --> Replace inorder successor's parent's left child
// with inorder successor's right child
inOrderSuccessorParent.left = inOrderSuccessor.right;
}
}Code-Sprache: GLSL (glsl)Wie auch bei der rekursiven Variante wird zunächst der In-order-Nachfolger gesucht und dessen Daten in den zu löschenden Knoten kopiert.
Das Entfernen des In-order-Nachfolgers aus dem rechten Teilbaum ist in der iterativen Variante allerdings aufwändiger. Hier müssen zwei Fälle unterschieden werden:
- Der In-order-Nachfolger ist das rechte Kind des zu löschenden Knotens, also die Wurzel des rechten Teilbaums. In diesem Fall wird das rechte Kind des zu löschenden Knotens mit dem rechten Kind des In-order-Nachfolgers ersetzt.
- Der In-order-Nachfolger ist weiter unten im rechten Teilbaum. In diesem Fall ist er das linke Kind seines Eltern-Knotens und wird durch sein eigenes rechtes Kind ersetzt.
Traversierung des binären Suchbaums
Genau wie bei Binärbäumen im Allgemeinen können auch in einem binären Suchbaum Pre-order-, Post-order-, In-order-, Reverse-in-order- und Level-order-Traversierungen durchgeführt werden.
Was diese Traversierungsarten bedeuten und wie sie in Java implementiert werden, erfährst du im Abschnitt Binärbaum-Traversierung des Artikels über Binärbäume.
Während pre-, post- und level-order wenig sinnvoll sind, ist die In-order-Traversierung im binären Suchbaum äußerst hilfreich: sie iteriert über alle Knoten des Baumes in Sortierreihenfolge ihrer Schlüssel:

Die im vorangegangenen Artikel vorgestellten Traversierungsklassen DepthFirstTraversal, DepthFirstTraversalIterative und DepthFirstTraversalRecursive können unverändert auf Instanzen von BinarySearchTree angewendet werden, da dieser ja transitiv das Interface BinaryTree implementiert.
Binären Suchbaum validieren
Es gibt Situationen, in denen wir einen Binärbaum vorliegen haben und wir prüfen müssen, ob dieser ein valider binärer Suchbaum ist.
Die naheliegende Lösung – rekursiv zu prüfen, ob jeder Knoten größer als sein linkes Kind und kleiner als sein rechtes Kind ist – ist leider falsch. Denn diese Eigenschaft würde beispielsweise auch auf folgenden Binärbaum zutreffen:

Die 6 ist in diesem Beispiel kleiner als die 12 – so weit, so gut. Sie befindet sich allerdings im rechten Teilbaum unter der 8. Dieser Teilbaum darf nur Schlüssel enthalten, die größer als 8 sind. Da dies auf die 6 nicht zutrifft, sind die Anforderungen für einen validen BST nicht erfüllt.
Wir haben stattdessen zwei Möglichkeiten:
- Wir führen ein reguläres Pre-order-Traversal durch und prüfen dabei, ob die Schlüsselreihenfolge eingehalten wird, d. h. ob der Schlüssel eines Knotens größer (oder gleich) ist wie der Schlüssel des Vorgängerknotens.
- Wir prüfen – von der Wurzel beginnend – den linken und rechten Teilbaum eines jeden Knoten rekursiv und geben dabei einen Bereich von Schlüssel an, die in diesem Teilbaum vorkommen dürfen.
Binären Suchbaum validieren – Java-Quellcode
Die zweite Variante lässt sich am einfachsten durch Lesen des Quellcodes verstehen (Klasse BinarySearchTreeValidator). Die folgende Variante erlaubt keine Schlüssel-Duplikate:
public static boolean isBstWithoutDuplicates(BinaryTree tree) {
return isBstWithoutDuplicates(tree.root, Integer.MIN_VALUE, Integer.MAX_VALUE);
}
private static boolean isBstWithoutDuplicates(
Node node, int minAllowedKey, int maxAllowedKey) {
if (node == null) {
return true;
}
if (node.data < minAllowedKey || node.data > maxAllowedKey) {
return false;
}
return isBstWithoutDuplicates(node.left, minAllowedKey, node.data - 1)
&& isBstWithoutDuplicates(node.right, node.data + 1, maxAllowedKey);
}Code-Sprache: Java (java)Wir übergeben der rekursiven isBstWithoutDuplicates()-Methode zunächst den Wurzelknoten und den Zahlenbereich aller Integer-Werte. Die Methode prüft, ob der Schlüssel des übergebenen Knotens im erlaubten Zahlenbereich liegt. Wenn nicht, gibt die Methode false zurück.
Wenn ja, wird die Methode rekursiv auf dem linken und rechten Teilbaum aufgerufen. Dabei wird der erlaubte Zahlenbereich entsprechend der BST-Eigenschaften immer weiter eingeschränkt.
Eine zweite Variante der Methode, die auch Schlüssel-Duplikate erlaubt findest du in derselben Klasse ab Zeile 33.
Zeitkomplexität des binären Suchbaums
Der Aufwand für das Suchen, Einfügen, und Löschen steigt linear mit der Tiefe des jeweiligen Knotens, da für jede Ebene, die der Knoten von der Wurzel entfernt ist, ein Vergleich durchgeführt werden muss.
In einem balancierten Binärbaum kann bei jedem Vergleich ungefähr die Hälfte des Baumes verworfen werden. Die Höhe eines balancierten Binärbaums mit n Knoten – und damit auch die Zeitkomplexität für die Such-, Einfüge- und Löschoperation – liegt also in der Größenordnung O(log n).
In einem degenerierten Binärbaum entspricht die Höhe der Anzahl der Knoten. Die Anzahl der Vergleiche – und damit auch die Zeitkomplexität für alle Operationen – liegt somit in der Größenordnung O(n).
Binärer Suchbaum im Vergleich
In den folgenden Abschnitten findest du die Vor- und Nachteile des Binären Suchbaums gegenüber anderen Datenstrukturen.
Binärbaum vs. binärer Suchbaum
Der Binäre Suchbaum ist eine Sonderform des Binärbaums, in dem die Binärbaum-Eigenschaften (s. Definiton) erfüllt sind.
Binärer Suchbaum vs. Heap
Im folgenden Vergleich von binärem Suchbaum und Heap gehe ich von einem balancierten binären Suchbaum aus. Bei einem degenerierten binären Suchbaum sind die angegebenen Zeitkomplexitäten entsprechend schlechter, nämlich O(n).
- In einem binären Suchbaum kann über die Schlüssel in Sortierreihenfolge iteriert werden. Das ist in einem Heap nicht direkt möglich.
- Einfügen und Löschen von Elementen ist in beiden Datenstrukturen mit logarithmischen Aufwand – O(log n) – möglich.
- Die Suche nach einem Element ist im binären Suchbaum mit logarithmischen Aufwand – O(log n) – verbunden. Da der Heap nicht sortiert ist, bleibt nur ein Durchsuchen aller Elemente – also linearer Aufwand, O(n).
- In einem Heap kann mit konstantem Aufwand – O(1) – auf das größte (Max-Heap) oder kleinste (Min-Heap) Element zugegriffen werden. In einem binären Suchbaum muss dazu entweder allen linken oder allen rechten Kindern gefolgt werden, was logarithmischen Aufwand – O(log n) – erfordert.
- Der Aufbau eines Heaps kann in linearer Zeit – O(n) erfolgen – der Aufbau eines BST hat einen Aufwand von O(n log n).
Wann sollte also welche Datenstruktur verwendet werden?
Möchte man nach Elementen suchen oder über alle Elemente in Sortierreihenfolge iterieren, eignet sich der binäre Suchbaum. Interessiert man sich hingegen nur für das größte oder kleinste Element, eignet sich der Heap besser.
Binärer Suchbaum vs. Hashtable
Ich gehe auch in diesem Vergleich von einem balancierten binären Suchbaum aus. Hashtable bezeichnet hier die abstrakte Datenstruktur. Der Vergleich gilt z. B. auch für die konkreten Java-Typen HashMap und HashSet.
- In einem binären Suchbaum kann über die Schlüssel in Sortierreihenfolge iteriert werden. Dies ist in einer Hashtable nicht möglich.
- In einem binären Suchbaum ist eine Bereichssuche möglich (also die Suche nach allen Elementen, die in einem vorgegebenen Wertebereich liegen). Da die Hashtable unsortiert ist, ist das bei ihr nicht möglich.
- In einer Hashtable können nur Elemente gespeichert werden, für die eine Hashfunktion definiert ist. In einem binären Suchbaum können nur Elemente gespeichert werden, für die eine Vergleichsfunktion definiert ist.
- In einer Hashtable kann es zu "Bucket Collisions" kommen. Diese müssen mit (mehr oder weniger) aufwändigen Algorithmen sowohl beim Einfügen als auch bei der Suche aufgelöst werden.
- Einfügen, Suchen und Löschen sind in einer Hashtable mit konstantem Aufwand – O(1) – möglich, sofern die Hashtable ausreichend dimensioniert ist und eine geeignete Hashfunktion verwendet wird. Beim binären Suchbaum ist die Zeitkomplexität für alle drei Operationen O(log n). Moderne Hashtables verwenden innerhalb ihrer Buckets ebenfalls binäre Suchbäume, sodass die Zeitkomplexität bei vielen Kollisionen ebenfalls Richtung O(log n) geht.
- Ein binärer Suchbaum ist effizienter bzgl. des Platzbedarfs, da er pro Element genau einen Knoten enthält. Eine Hashtable enthält in der Regel auch leere Buckets.
Wann sollte ein binärer Suchbaum eingesetzt werden und wann eine Hashtable?
Möchte man über alle Elemente in Sortierreihenfolge itererieren oder Bereichssuchen durchführen, eignet sich der binäre Suchbaum. Sollen lediglich Elemente eingefügt, gesucht und gelöscht werden, sollte die – bei diesen Operationen schnellere – Hashtable eingesetzt werden.
Binäre Suche vs. binärer Suchbaum
Und zu guter Letzt (da oft danach gefragt wird):
- Ein binärer Suchbaum ist eine Datenstruktur wie in diesem Artikel beschrieben.
- Die binäre Suche hingegen ist ein Algorithmus, mit der in einer sortierten Liste gesucht werden kann.
Fazit
Dieses Tutorial hat dir gezeigt, was ein binärer Suchbaum ist, und wie man in diesem schnell Elemente suchen, einfügen und löschen kann. Du hast beispielhafte Implementierungen in Java kennengelernt - eine rekursive und eine iterative. Und ich habe dir die Unterschiede des binären Suchbaums gegenüber anderen Datenstrukturen aufgelistet.
Im den nächsten Teilen der Serie werde ich dir die konkreten BST-Implementierungen AVL-Baum und Rot-Schwarz-Baum vorstellen.