


Selection Sort – Algorithmus, Quellcode, Zeitkomplexität
Dieser Artikel ist Teil der Serie „Sortieralgorithmen: Ultimate Guide“ und…
- beschreibt wie Selection Sort funktioniert,
- zeigt den Java-Quellcode für Selection Sort,
- leitet die Zeitkomplexität her (ohne komplizierte Mathematik)
- und überprüft, ob die Performance der Java-Implementierung mit dem erwarteten Laufzeitverhalten übereinstimmt.
Die Quellcodes der gesamten Artikelserie findest du in meinem GitHub-Repository.
Beispiel: Sortieren von Spielkarten
Das Einsortieren von Spielkarten auf die Hand ist eigentlich das klassische Beispiel für Insertion Sort.
Selection Sort kann man im Grunde genommen auch mit Spielkarten darstellen. Ich kenne zwar niemanden, der seine Karten so aufnimmt, aber als Beispiel eignet es sich ganz gut ;-)
Hier legst du zunächst alle deine Karten offen vor dich auf den Tisch. Dann suchst du die kleinste Karte und nimmst sie nach links auf die Hand, danach die nächst größere und setzt sie rechts daneben, usw. bis du zuletzt die größte Karte aufnimmst und ganz rechts einsortierst.

Unterschied zu Insertion Sort
Bei Insertion Sort hatten wir die jeweils nächste unsortierte Karte genommen und dann in den sortierten Karten an der richtigen Stelle eingefügt ("inserted").
Selection Sort funktioniert gewissermaßen anders herum: Wir wählen ("select") die jeweils kleinste Karte aus den unsortierten Karten, um diese dann – eine nach der anderen – an die bereits sortierten Karten anzuhängen.
Selection Sort Algorithmus
Der Algorithmus lässt sich am einfachsten an einem Beispiel erklären. Im folgenden zeige ich, wie man das Array [6, 2, 4, 9, 3, 7] mit Selection Sort sortiert:
Schritt 1
Wir teilen das Array gedanklich in einen linken, sortierten Teil und einen rechten, unsortierten Teil. Der sortierte Bereich ist zu Beginn leer:

Schritt 2
Wir suchen im rechten, unsortierten Teil nach dem kleinsten Element. Dazu merken wir uns zunächst das erste Element, die 6. Wir gehen zum nächsten Feld, dort finden wir mit der 2 ein noch kleineres Element. Wir wandern über den Rest des Arrays auf der Suche nach einem noch kleineren Element. Da wir keines finden, bleibt es bei der 2. Diese setzen wir an die korrekte Position, indem wir sie mit dem Element auf dem ersten Platz tauschen. Im Anschluss schieben wir die Grenze zwischen den Array-Bereichen um eine Position nach rechts:

Schritt 3
Wir suchen erneut im rechten, unsortierten Teil nach dem kleinsten Element. Dieses mal ist es die 3; wir tauschen sie mit dem Element an der zweiten Position:

Schritt 4
Erneut suchen wir nach dem kleinsten Element im rechten Bereich. Es ist die 4. Diese befindet sich bereits an der richtigen Position, so dass hier keine Tauschoperation stattfinden muss und wir lediglich die Bereichsgrenze verschieben:

Schritt 5
Als kleinstes Element finden wir die 6 und tauschen sie mit dem Element am Anfang des rechten Teils, der 9:

Schritt 6
Von den verbleibenden zwei Elementen ist die 7 am kleinsten, wir vertauschen sie mit der 9:

Algorithmus beendet
Das letzte Element ist automatisch das größte und damit an der richtigen Position. Der Algorithmus ist beendet, und die Elemente sind fertig sortiert:

Selection Sort Java Quellcode
In diesem Abschnitt findest du eine einfache Java-Implementierung von Selection Sort.
Die äußere Schleife iteriert über die einzusortierenden Elemente und endet nach dem vorletzten Element. Wenn dieses sortiert ist, ist automatisch auch das letzte Element sortiert. Die Schleifenvariable i zeigt immer auf das erste Element des rechten, unsortierten Teils.
Als kleinstes Element min wird in jedem Schleifendurchlauf zunächst das erste Element des rechten Teils angenommen; dessen Position wird in minPos gespeichert.
Die innere Schleife iteriert dann vom zweiten Element des rechten Teils bis zu dessen Ende und weist min und minPos immer dann neu zu, wenn ein noch kleineres Element gefunden wird.
Nach dem Durchlauf der inneren Schleife werden die Elemente der Positionen i (Anfang des rechten Teils) und minPos ausgetauscht (es sei denn, es handelt sich um dasselbe Element).
public class SelectionSort {
public static void sort(int[] elements) {
int length = elements.length;
for (int i = 0; i < length - 1; i++) {
// Search the smallest element in the remaining array
int minPos = i;
int min = elements[minPos];
for (int j = i + 1; j < length; j++) {
if (elements[j] < min) {
minPos = j;
min = elements[minPos];
}
}
// Swap min with element at pos i
if (minPos != i) {
elements[minPos] = elements[i];
elements[i] = min;
}
}
}
}Code-Sprache: Java (java)Der abgebildete Code unterscheidet sich insofern von der Klasse SelectionSort im GitHub-Repository, als dass diese das Interface SortAlgorithm implementiert, um innerhalb des Testframeworks einfach austauschbar zu sein.
Selection Sort Zeitkomplexität
Wir bezeichnen die Anzahl der Elemente mit n, in unserem Beispiel ist n = 6.
Die zwei ineinander verschachtelten Schleifen sind ein Indiz dafür, dass wir es mit einer Zeitkomplexität* von O(n²) zu tun haben. Das wäre dann der Fall, wenn beide Schleifen bis zu einem Wert iterieren, der linear mit n steigt.
Bei der äußeren Schleife ist das offensichtlich der Fall: diese zählt bis n-1.
Wie sieht es mit der inneren Schleife aus?
Dies soll die folgende Grafik zeigen:

In jedem Schritt wird jeweils ein Vergleich weniger ausgeführt als es unsortierte Elemente gibt. In Summe sind es 15 Vergleiche – und zwar unabhängig davon, ob das Array vorab sortiert ist oder nicht.
Das lässt sich auch wie folgt berechnen:
Sechs Elemente mal fünf Schritte; geteilt durch zwei, da im Durchschnitt über alle Schritte die Hälfte der Elemente noch unsortiert ist:
6 × 5 × ½ = 30 × ½ = 15
Ersetzen wir 6 durch n, erhalten wir:
n × (n – 1) × ½
Ausmultipliziert ergibt das:
½ n² – ½ n
Die höchste Potenz von n in diesem Term ist n². Die Zeitkomplexität für das Suchen des kleinsten Elements beträgt somit O(n²) – auch „quadratischer Aufwand“ genannt.
Betrachten wir nun das Vertauschen der Elemente: In jedem Schritt (bis auf den letzten) wird entweder ein Element vertauscht oder keines, je nachdem, ob sich das jeweils kleinste Element bereits an der richtigen Position befindet oder nicht. Damit haben wir in Summe maximal n-1 Tauschopertionen, also eine Zeitkomplexität von O(n) – auch "linearer Aufwand" genannt.
Für die Gesamtkomplexität zählt nur die höchste Komplexitätsklasse, daher gilt:
Die Zeitkomplexität von Selection Sort beträgt im average, best und worst case: O(n²)
* Die Begriffe „Zeitkomplexität“ und „O-Notation“ werden in diesem Artikel anhand von Beispielen und Diagrammen erklärt.
Laufzeit des Java Selection Sort-Beispiels
Genug der Theorie! Ich habe ein Testprogramm geschrieben, das die Laufzeit von Selection Sort (und aller anderen in dieser Serie behandelten Sortieralgorithmen) wie folgt misst:
- Die Anzahl der zu sortierenden Elemente verdoppelt sich nach jeder Iteration von anfänglich 1.024 Elementen auf 536.870.912 (= 229) Elemente. Ein doppelt so großes Array lässt sich in Java nicht erstellen.
- Wenn ein Test länger als 20 Sekunden dauert, wird das Array nicht weiter vergrößert.
- Alle Tests werden mit unsortierten, sowie aufsteigend und absteigend vorsortierten Elementen durchgeführt.
- Dem HotSpot-Compiler wird zwei WarmUp-Runden Zeit gelassen den Code zu optimieren, danach werden die Tests so lange wiederholt, bis der Prozess abgebrochen wird.
Nach jeder Wiederholung gibt das Programm den Median aller bisherigen Messergebnisse aus.
Hier ist das Ergebnis für Selection Sort nach 50 Wiederholungen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
| n | unsortiert | aufsteigend | absteigend |
|---|---|---|---|
| ... | ... | ... | ... |
| 16.384 | 27,9 ms | 26,8 ms | 65,6 ms |
| 32.768 | 108,0 ms | 105,4 ms | 265,4 ms |
| 65.536 | 434,0 ms | 424,3 ms | 1.052,2 ms |
| 131.072 | 1.729,8 ms | 1.714,1 ms | 4.209,9 ms |
| 262.144 | 6.913,4 ms | 6.880,2 ms | 16.863,7 ms |
| 524.288 | 27.649,8 ms | 27.568,7 ms | 67.537,8 ms |
Hier die Messwerte noch einmal als Diagramm (wobei ich "unsortiert" und "aufsteigend" aufgrund der fast identischen Werte als eine Kurve dargestellt habe):
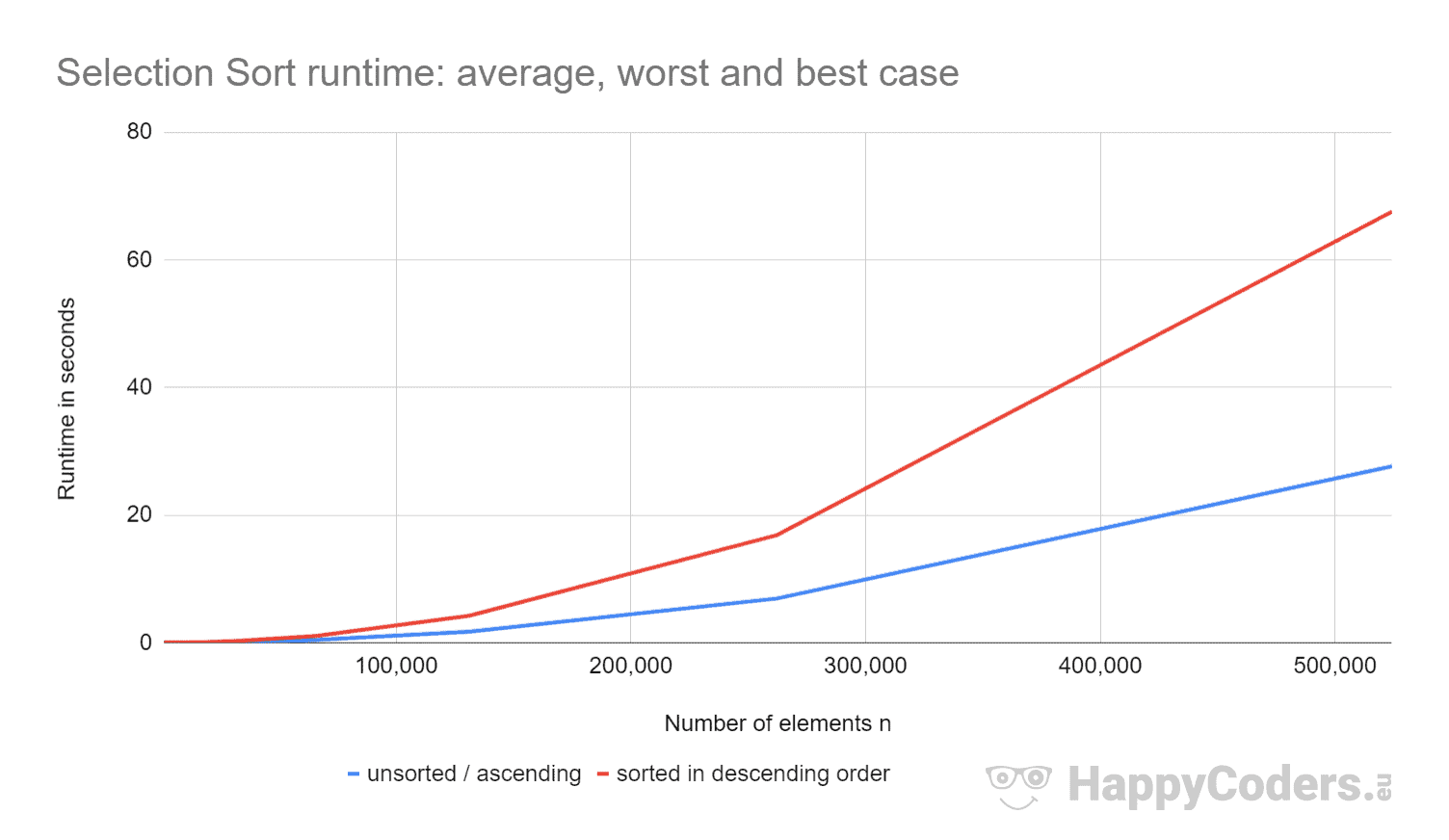
Es lässt sich sehr gut erkennen,
- dass sich die Laufzeit bei Verdoppelung der Anzahl der Elemente in etwa vervierfacht – und zwar unabhängig davon, ob die Elemente vorsortiert sind oder nicht. Dies entspricht der erwarteten Zeitkomplexität O(n²).
- dass die Laufzeit bei aufsteigend sortierten Elementen minimal besser ist als bei unsortierten Elementen. Dies liegt daran, dass hier die Tauschoperationen wegfallen, welche – wie zuvor analysiert – kaum ins Gewicht fallen.
- dass die Laufzeit bei absteigend sortierten Elementen deutlich schlechter ist als bei unsortierten Elementen.
Wieso ist das so?
Analyse der worst case-Laufzeit
Das Suchen des jeweils kleinsten Elements sollte doch theoretisch – unabhängig von der Ausgangslage – immer gleich lang dauern; und die Tauschoperationen sollten bei absteigend sortierten Elementen nur minimal mehr sein (bei absteigend sortierten Elementen müsste jedes getauscht werden; bei unsortierten geschätzt fast jedes).
Mit dem Programm CountOperations aus meinem GitHub-Repository können wir uns die Anzahl der verschiedenen Operationen anzeigen lassen. Hier die Ergebnisse für unsortierte und absteigend sortierte Elemente in einer Tabelle zusammengefasst:
| n | Vergleiche | Tauschen unsortiert | Tauschen absteigend | minPos/min unsortiert | minPos/min absteigend |
|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... |
| 512 | 130.816 | 504 | 256 | 2.866 | 66.047 |
| 1.024 | 523.776 | 1.017 | 512 | 6.439 | 263.167 |
| 2.048 | 2.096.128 | 2.042 | 1.024 | 14.727 | 1.050.623 |
| 4.096 | 8.386.560 | 4.084 | 2.048 | 30.758 | 4.198.399 |
| 8.192 | 33.550.336 | 8.181 | 4.096 | 69.378 | 16.785.407 |
Aus den Messwerten lässt sich erkennen:
- Bei absteigend sortierten Elementen haben wir – wie erwartet – genauso viele Vergleichsoperationen wie bei unsortierten Elementen – nämlich n × (n-1) / 2.
- Bei unsortierten Elementen haben wir – wie vermutet – beinahe so viele Tauschoperationen wie Elemente: bei 4.096 unsortierten Elementen sind es beispielsweise 4.084 Tauschoperationen. Diese Zahlen ändern sich zufallsbedingt leicht von Test zu Test.
- Bei absteigend sortierten Elementen haben wir allerdings nur halb so viele Tauschoperationen wie Elemente! Dies liegt daran, dass wir beim Vertauschen nicht nur jeweils das kleinste Element an die richtige Stelle setzen, sondern auch den jeweiligen Tauschpartner.
Bei acht Elementen haben wir beispielsweise vier Tauschoperationen. In den ersten vier Iterationen jeweils eine und in den Iterationen fünf bis acht keine mehr (dennoch läuft der Algorithmus bis zum Ende weiter):

Des weiteren lässt sich an den Messwerten ablesen:
- Den Grund, warum Selection Sort bei absteigend sortierten Elementen so deutlich langsamer ist, finden wir in der Anzahl der lokalen Variablenzuweisungen (
minPosundmin) bei der Suche nach dem kleinsten Element: Während wir bei 8.192 unsortierten Elementen 69.378 dieser Zuweisungen haben, sind es bei absteigend sortierten Elementen 16.785.407 Zuweisungen – das sind 242 mal so viele!
Warum dieser massive Unterschied?
Analyse der Laufzeit der Suche nach dem kleinsten Element
Für absteigend sortierte Elemente lässt sich die Größenordnung an der Grafik von soeben herleiten: Die Suche nach dem kleinsten Element beschränkt sich auf das Dreieck aus den orangenen und orange-blauen Kästchen. Im oberen, orangenen Teil werden die Zahlen in jedem Feld kleiner, im rechten orange-blauen Teil steigen die Zahlen wieder an.
Zuweisungsoperationen finden in jedem orangenen Kästchen statt sowie im jeweils ersten der orange-blauen. Die Anzahl der Zuweisungsoperationen für minPos und min ist also bildlich gesprochen in etwa "ein Viertel des Quadrats" – mathematisch und ganz exakt sind es: ¼ n² + n - 1.
Für unsortierte Elemente müssten wir deutlich tiefer in die Materie eindringen. Dies würde nicht nur den Rahmen dieses Artikels, sondern des gesamten Blogs, sprengen.
Ich beschränke meine Analyse daher auf ein kleines Demo-Programm, welches misst, wie viele minPos/min-Zuweisungen es bei der Suche nach dem kleinsten Element in einem unsortierten Array gibt. Hier die durchschnittlichen Werte nach 100 Iterationen (ein kleiner Auszug; die kompletten Ergebnisse findest Du hier):
| n | durchschnittliche Anzahl minPos/min-Zuweisungen |
|---|---|
| 1.024 | 7.08 |
| 4.096 | 8.61 |
| 16.385 | 8.94 |
| 65.536 | 11.81 |
| 262.144 | 12.22 |
| 1.048.576 | 14.26 |
| 4.194.304 | 14.71 |
| 16.777.216 | 16.44 |
| 67.108.864 | 17.92 |
| 268.435.456 | 20.27 |
Hier das ganze als Diagramm mit logarithmischer x-Achse:

Am Diagramm sieht man sehr schön, dass wir hier ein logarithisches Wachstum haben, d. h. mit jeder Verdoppelung der Anzahl der Elemente erhöht sich die Anzahl der Zuweisungen nur um einen konstanten Wert. Auf die mathematischen Hintergründe gehe ich, wie gesagt, hier nicht weiter ein.
Dies ist der Grund, warum diese minPos/min-Zuweisungen bei unsortierten Arrays kaum ins Gewicht fallen.
Weitere Eigenschaften von Selection Sort
Im folgenden werden die Platzkomplexität, Stabilität und Parallelisierbarkeit von Selection Sort behandelt.
Platzkomplexität von Selection Sort
Die Platzkomplexität von Selection Sort ist konstant, da wir außer den Schleifenvariablen i und j, sowie den Hilfsvariablen length, minPos und min keinen zusätzlichen Speicherplatz benötigen.
D. h. egal wie viele Elemente wir sortieren – zehn oder zehn Millionen – wir benötigen immer nur diese fünf zusätzlichen Variablen. Konstanten Aufwand notiert man als O(1).
Stabilität von Selection Sort
Selection Sort erscheint auf den ersten Blick stabil: Wenn im unsortierten Teil mehrere Elemente mit dem gleichen Key vorkommen, sollte das erste davon doch auch als erstes an den sortierten Teil angehängt werden.
Doch der Schein trügt. Denn durch das Tauschen zweier Elemente im zweiten Teilschritt des Algorithmus kann es passieren, dass bestimmte Elemente im unsortierten Teil nicht mehr die ursprüngliche Reihenfolge haben. Dies führt dann wiederum dazu, dass sie letztlich auch im sortierten Teil nicht mehr in der ursprünglichen Reihenfolge erscheinen.
Ein Beispiel kann sehr einfach konstruiert werden. Angenommen wir haben zwei unterschiedliche Elemente mit dem Key 2 und eines mit dem Key 1, die wie folgt angeordnet sind, und sortieren diese mit Selection Sort:

Im ersten Schritt werden das erste und letzte Element vertauscht. Damit landet das Element "TWO" hinter dem Element "two" – die Reihenfolge beider Elemente ist vertauscht.
Im zweiten Schritt vergleicht der Algorithmus die beiden hinteren Elemente. Beide haben den gleichen Key, 2. Es wird also kein Element vertauscht.
Im dritten Schritt verbleibt nur ein Element, dieses gilt automatisch als sortiert.
Die zwei Elemente mit dem Key 2 sind also gegenüber ihrer Ausgangsreihenfolge vertauscht worden – der Algorithmus ist unstabil.
Stabile Variante von Selection Sort
Selection Sort kann stabil gemacht werden, indem in Schritt zwei das kleinste Element nicht mit dem ersten vertauscht wird, sondern zwischen dem ersten und dem kleinsten Elemente alle Elemente um eine Position nach rechts geschoben werden und das kleinste Element an den Anfang gesetzt wird.
Auch wenn die Zeitkomplexität durch diese Änderung gleichbleiben wird, führen die zusätzlichen Verschiebungen zu einer deutlichen Verschlechterung der Performance, zumindest wenn wir ein Array sortieren.
Bei einer verketteten Liste könnte das Ausschneiden und Einfügen des einzusortierenden Elements ohne signifikanten Performanceverlust durchgeführt werden.
Parallelisierbarkeit von Selection Sort
Die äußere Schleife ist nicht parallelisierbar, da diese den Inhalt des Arrays in jedem Schritt ändert.
Die innere Schleife (Suche nach dem kleinsten Element) kann parallelisiert werden, in dem das Array aufgeteilt wird, in jedem Teilarray parallel das kleinste Element gesucht wird, und dann die Zwischenergebnisse zusammengeführt werden.
Selection Sort vs. Insertion Sort
Welcher Algorithmus ist schneller, Selection Sort oder Insertion Sort?
Im folgenden stelle ich die Messwerte aus meinen Java-Implementierungen gegenüber. Den best case lasse ich außen vor; dieser hat bei Insertion Sort eine Zeitkomplexität von O(n) und hat bis zu 524.288 Elementen weniger als eine Millisekunde gebraucht – ist also in jedem Fall um Größenordnungen schneller als Selection Sort.
| n | Selection Sort unsortiert | Insertion Sort unsortiert | Selection Sort absteigend | Insertion Sort absteigend |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 16.384 | 27,9 ms | 21,9 ms | 65,6 ms | 43,6 ms |
| 32.768 | 108,0 ms | 87,9 ms | 265,4 ms | 175,8 ms |
| 65.536 | 434,0 ms | 350,4 ms | 1.052,2 ms | 697,6 ms |
| 131.072 | 1.729,8 ms | 1.398,9 ms | 4.209,9 ms | 2.840,0 ms |
| 262.144 | 6.913,4 ms | 5.706,8 ms | 16.863,7 ms | 11.517,4 ms |
| 524.288 | 27.649,8 ms | 23.009,7 ms | 67.537,8 ms | 46.309,3 ms |
Und noch einmal als Diagramm:

Insertion Sort ist also nicht nur im best case, sondern auch im average und worst case schneller als Selection Sort.
Der Grund dafür ist, dass Insertion Sort mit durchschnittlich halb so vielen Vergleichen auskommt. Zur Erinnerung: bei Insertion Sort haben wir Vergleiche und Verschiebungen bis durchschnittlich zur Hälfte der sortierten Elemente; bei Selection Sort müssen wir in jedem Schritt in allen unsortierten Elementen das kleinste Element suchen.
Bei Selection Sort haben wir deutlich weniger Schreiboperationen, so dass Selection Sort schneller sein kann, wenn Schreiboperationen teuer sind. Beim sequentiellen Schreiben in Arrays ist das nicht der Fall, da dies größtenteils im CPU-Cache erfolgt.
In der Praxis wird daher so gut wie ausschließlich Insertion Sort angewendet.
Zusamenfassung
Selection Sort ist ein einfach zu implementierender, in der Standardimplementierung nicht stabiler Sortiergorithmus mit einer Zeitkomplexität von O(n²) im average, best und worst case.
Selection Sort ist langsamer als Insertion Sort, weshalb es in der Praxis nicht angewendet wird.
Weitere Sortieralgorithmen findest du in dieser Übersicht aller Sortieralgorithmen und ihrer Eigenschaften im ersten Teil der Artikelserie.