


Java 21 Features
(mit Beispielen)
Am 19. September 2023 wurde mit großen Launch-Events die Veröffentlichung von Java 21, der neuesten Long-Term-Support-Version (nach Java 17), gefeiert. Oracle stellt für Oracle JDK 21 kostenlose Updates unter der No-Fee-Terms-and-Conditions-Lizenz bis September 2026 bereit. Mit einem kostenpflichtigen Java-SE-Abo gibt es darüber hinaus Premier Support bis September 2028 und Extended Support bis September 2031.
Die Highlights von Java 21:
- Mit Virtuellen Threads wird eine der bedeutendsten Neuerungen der Java-Geschichte finalisiert.
- Ebenfalls finalisiert werden zwei neue Java-Sprachfeatures aus Project Amber: Record Patterns und Pattern Matching for switch.
- Ein neues, äußerst praktisches Interface, SequencedCollection, ermöglicht den direkten Zugriff auf das erste und letzte Element einer geordneten Collection.
- Zwei lang ersehnte Features, die andere Sprachen seit langem bieten, gibt es nun endlich auch in Java (vorerst als Preview-Feature): String Templates und Unnamed Patterns and Variables.
Wie immer verwende ich ausschließlich die englischen Bezeichnungen der JEPs.
Virtual Threads – JEP 444
Bei der Skalierung von Server-Anwendungen stellen Threads oft einen Engpass dar. Ihre Anzahl ist begrenzt, und sie müssen häufig auf Ereignisse warten, wie beispielsweise die Antwort einer Datenbankabfrage oder eines Remote-Aufrufs, oder sie werden durch Locks blockiert.
Bisherige Lösungsansätze wie CompletableFuture oder reaktive Frameworks führen zu extrem schwer les- und wartbarem Code.
Mehrere Jahre lang wurde in Project Loom an einer besseren Lösung gearbeitet. In Java 19 war es dann endlich so weit: Virtuelle Threads wurden erstmals als Preview-Feature vorgestellt.
In Java 21 werden virtuelle Threads durch JDK Enhancement Proposal 444 finalisiert und sind somit reif für den Einsatz in Produktion.
Was sind virtuelle Threads?
Im Gegensatz zu reaktivem Code ermöglichen virtuelle Threads die Programmierung im vertrauten, sequentiellen Thread-pro-Request-Stil.
Sequentieller Code ist nicht nur einfacher zu schreiben und zu lesen, sondern auch leichter zu debuggen, da der Programmablauf in einem Debugger Schritt für Schritt nachverfolgt werden kann und Stacktraces den erwarteten Aufrufstack widerspiegeln. Wer schon einmal versucht hat, eine reaktive Anwendung zu debuggen, wird verstehen, was gemeint ist.
Ermöglicht wird das dadurch, dass sich viele virtuelle Threads einen Plattform-Thread (so werden die herkömmlichen, vom Betriebssystem bereitgestellten Threads genannt) teilen. Sobald ein virtueller Thread warten muss oder blockiert wird, wird der Plattform-Thread einen anderen virtuellen Thread ausführen.
Dadurch können wir mit wenigen Betriebssystem-Threads mehrere Millionen (!) virtuelle Threads ausführen.
Das Beste daran ist, dass wir den bestehenden Java-Code nicht einmal ändern müssen. Wir müssen lediglich unserem Application Framework mitteilen, dass es nicht mehr Plattform-Threads, sondern virtuelle Threads einsetzen soll.
Wie virtuelle Threads genau funktionieren, welche Einschränkungen sie haben und was hinter den Kulissen passiert, kannst du im Hauptartikel über virtuelle Threads nachlesen.
Änderungen gegenüber der Preview-Version
In den Preview-Versionen war es möglich, einen virtuellen Thread so zu konfigurieren, dass dieser keine ThreadLocal-Variablen haben kann (da die sehr teuer sein können, sollen virtuelle Threads stattdessen die in Java 21 als Preview enthaltenen Scoped Values verwenden). Diese Möglichkeit wurde wieder entfernt, damit so viel existierender Code wie möglich ohne Änderungen auch in virtuellen Threads laufen kann.
Sequenced Collections – JEP 431
Was ist der einfachste Weg, um auf das letzte Element einer Liste zuzugreifen? Sofern man keine zusätzlichen Libraries oder Hilfsmethoden verwendet, ist es in Java – bisher – der folgende:
var last = list.get(list.size() - 1);Code-Sprache: Java (java)In Java 21 können wir dieses Ungetüm endlich durch einen kurzen und prägnanten Aufruf ersetzen:
var last = list.getLast();Code-Sprache: Java (java)Vielleicht musstest du auch schon einmal auf das erste Element eines LinkedHashSet zugreifen? Das erforderte bisher den folgenden Umweg:
var first = linkedHashSet.iterator().next();Code-Sprache: Java (java)In Java 21 geht auch das einfacher:
var first = linkedHashSet.getFirst();Code-Sprache: Java (java)Um auf das letzte Element eines LinkedHashSet zuzugreifen, musste man sogar über das komplette Set iterieren! Auch das geht jetzt ganz einfach mit getLast().
Steigen wir ein wenig in die Details ein...
SequencedCollection Interface
Um neue, einheitliche Methoden zum Zugriff auf die Elemente einer Collection mit stabiler Iterationsreihenfolge zu ermöglichen, wurde in Java 21 das Interface SequencedCollection eingeführt. Dieses definiert unter anderem die zwei oben vorgestellten Methoden getFirst() und getLast() und wird von denjenigen Interfaces geerbt bzw. Klassen implementiert, deren Elemente die o. g. stabile Iterationsreihenfolge haben:
List(z. B.ArrayList,LinkedList)SortedSetund dessen ErweiterungNavigableSet(z. B.TreeSet)LinkedHashSet
Neben den oben genannten Methoden definiert SequencedCollection<E> noch folgende Methoden:
void addFirst(E)– fügt ein Element am Anfang der Collection einvoid addLast(E)– hängt ein Element an das Ende der Collection anE removeFirst()– entfernt das erste Element und gibt es zurückE removeLast()– entfernt das letzte Element und gibt es zurück
Alle vier Methoden werfen bei unveränderlichen Collections eine UnsupportedOperationException.
Eine weitere Methode ist:
SequencedCollection reversed();
Diese liefert eine View auf die Collection in umgekehrter Reihenfolge. Diese kann verwendet werden, um rückwärts über die Collection zu iterieren. „View“ bedeutet, dass Änderungen an der ursprünglichen Collection auch in der View sichtbar sind und umgekehrt.
SequencedSet Interface
Das neue Interface SequencedSet erbt von Set und SequencedCollection. Es bietet keine zusätzlichen Methoden, überschreibt allerdings die reversed()-Methode, um den Rückgabetyp SequencedCollection durch SequencedSet zu ersetzen.
Darüber hinaus haben addFirst(E) und addLast(E) im SequencedSet eine besondere Bedeutung: Wenn das hinzuzufügende Element bereits im Set enthalten ist, wird es an den Anfang bzw. an das Ende des Sets verschoben.
Die folgende Grafik zeigt, wie SequencedCollection und SequencedSet in die bestehende Klassenhierarchie eingefügt wurden (der Übersichtlichkeit halber wird nur eine Auswahl¹ an Klassen angezeigt):

SequencedCollection und SequencedSet in der Java-21-Klassenhierarchie¹ Die Auswahl beschränkt sich auf diejenigen Klassen, die im JDK-Quellcode mindestens 100 Mal verwendet werden.
SequencedMap Interface
In Java stellen Collections (z. B. Listen, Sets) und Maps (z. B. HashMap) zwei separate Klassenhierarchien dar. Für geordnete Maps (also solche, deren Elemente eine definierte Reihenfolge haben) wird ebenfalls ein neues Interface, SequencedMap, bereitgestellt, das einfachen Zugriff auf das erste und letzte Element einer solchen Map bietet.
SequencedMap bietet analog zu SequencedCollection die folgenden Methoden:
Entry<K, V> firstEntry()– gibt das erste Key-Value-Paar der Map zurückEntry<K, V> lastEntry()– gibt das letzte Key-Value-Paar der Map zurückEntry<K, V> pollFirstEntry()– entfernt das erste Key-Value-Paar und gibt es zurückEntry<K, V> pollLastEntry()– entfernt das letzte Key-Value-Paar und gibt es zurückV putFirst(K, V)– fügt ein Key-Value-Paar am Anfang der Map einV putLast(K, V)– hängt ein Key-Value-Paar am Ende der Map anSequencedMap<K, V> reversed()– liefert eine View auf die Map in umgekehrter Reihenfolge
Sollte zu einem Key bereits ein Eintrag existieren, wird dieser von putFirst() und putLast() überschrieben und an den Anfang bzw. ans Ende der Map verschoben.
Darüber hinaus gibt es drei weitere Methoden:
SequencedSet sequencedKeySet()– liefert die Keys der MapSequencedCollection<V> sequencedValues()– liefert die Values der MapSequencedSet<Entry<K,V>> sequencedEntrySet()– liefert alle Einträge der Map
Hier siehst du, wie das neue Interface in die bestehende Klassenhierarchie eingefügt wurde (dieses Mal mit allen implementierenden Klassen):

SequencedMap in der Java-21-KlassenhierarchieSequencedCollection, SequencedSet und SequencedMap werden in JDK Enhancement Proposal 431 definiert.
Neue Collections-Methoden
Die Collections-Utility-Klasse wurde um einige statische Hilfsmethoden, speziell für Sequenced Collections, erweitert:
newSequencedSetFromMap(SequencedMap map)– analog zuCollections.setFromMap(…)liefert diese Methode einSequencedSetmit den Eigenschaften der zugrunde liegenden Map.unmodifiableSequencedCollection(SequencedCollection c)– gibt analog zuCollections.unmodifiableCollection(…)eine unveränderliche Sicht auf die zugrunde liegendeSequencedCollectionzurück.- Unveränderlich bedeutet, dass Aufrufe von ändernden Methoden, wie z. B.
add(…)oderremove(…), eineUnsupportedOperationExceptionwerfen. - Sicht bedeutet, dass Änderungen an der zugrunde liegenden Collection in der von
unmodifiableSequencedCollection(…)zurückgegebenen Collection sichtbar sind.
- Unveränderlich bedeutet, dass Aufrufe von ändernden Methoden, wie z. B.
Collections.unmodifiableSequencedMap(SequencedMap m)– gibt analog zuCollections.unmodifiableMap(…)eine unveränderliche Sicht auf die zugrunde liegendeSequencedMapzurück.Collections.unmodifiableSequencedSet(SequencedSet s)– gibt analog zuCollections.unmodifiableSet(…)eine unveränderliche Sicht auf das zugrunde liegendeSequencedSetzurück.
Record Patterns – JEP 440
„Record Patterns“ wurde erstmals in Java 19 als Preview-Feature vorgestellt. Sie können in Kombination mit Pattern Matching for instanceof und Pattern Matching for switch verwendet werden, um ohne explizite Casts und ohne Verwendung von Zugriffsmethoden auf die Felder eines Records zuzugreifen.
Das hört sich komplizierter an als es ist. Am besten erkläre ich Record Patterns an einem Beispiel:
Wir beginnen mit einem einfachen Record (falls du mit Records noch nicht vertraut bist, findest du hier eine Einführung in Java-Records).
public record Position(int x, int y) {}Code-Sprache: Java (java)Nun nehmen wir an, wir haben ein beliebiges Objekt und wollen damit – abhängig von dessen Klasse – eine bestimmte Aktion durchführen, z. B. etwas auf der Konsole ausgeben.
Record Patterns und Pattern Matching for instanceof
Das könnten wir mit dem in Java 16 eingeführten Pattern Matching for instanceof z. B. wie folgt machen:
public void print(Object o) {
if (o instanceof Position p) {
System.out.printf("o is a position: %d/%d%n", p.x(), p.y());
} else if (o instanceof String s) {
System.out.printf("o is a string: %s%n", s);
} else {
System.out.printf("o is something else: %s%n", o);
}
}Code-Sprache: Java (java)Anstatt auf das Pattern Position p können wir nun auch auf ein sogenanntes Record Pattern matchen – nämlich Position(int x, int y) – und dann im nachfolgenden Code anstatt auf p.x() und p.y() direkt auf die Variablen x und y zugreifen:
public void print(Object o) {
if (o instanceof Position(int x, int y)) {
System.out.printf("o is a position: %d/%d%n", x, y);
} else if (o instanceof String s) {
System.out.printf("o is a string: %s%n", s);
} else {
System.out.printf("o is something else: %s%n", o);
}
}Code-Sprache: Java (java)Record Patterns und Pattern Matching for switch
Das erste Beispiel (ohne Record Pattern) können wir auch mit dem ebenfalls in Java 21 finalisierten Pattern Matching for switch schreiben:
public void print(Object o) {
switch (o) {
case Position p -> System.out.printf("o is a position: %d/%d%n", p.x(), p.y());
case String s -> System.out.printf("o is a string: %s%n", s);
default -> System.out.printf("o is something else: %s%n", o);
}
}
Code-Sprache: Java (java)Auch das Switch-Statement können wir mit einem Record Pattern kombinieren:
public void print(Object o) {
switch (o) {
case Position(int x, int y) -> System.out.printf("o is a position: %d/%d%n", x, y);
case String s -> System.out.printf("o is a string: %s%n", s);
default -> System.out.printf("o is something else: %s%n", o);
}
}
Code-Sprache: Java (java)Verschachtelte Record Patterns
Wir können nicht nur auf ein Record matchen, dessen Felder Objekte oder Primitive sind. Wir können ebenso auf ein Record matchen, dessen Felder ebenfalls Records sind.
Als Beispiel nehmen wir den folgenden Record, Path, mit einer Start- und einer Endposition hinzu:
public record Path(Position from, Position to) {}Code-Sprache: Java (java)Die print()-Methode aus den vorigen Beispielen soll nun auch einen Path ausgeben können – hier zunächst die Implementierung ohne Record Pattern:
public void print(Object o) {
switch (o) {
case Path p ->
System.out.printf("o is a path: %d/%d -> %d/%d%n",
p.from().x(), p.from().y(), p.to().x(), p.to().y());
// other cases
}
}Code-Sprache: Java (java)Mit einem Record Pattern könnten wir zum einen auf Path(Position from, Position to) matchen:
public void print(Object o) {
switch (o) {
case Path(Position from, Position to) ->
System.out.printf("o is a path: %d/%d -> %d/%d%n",
from.x(), from.y(), to.x(), to.y());
// other cases
}
}Code-Sprache: Java (java)Wir können aber auch ein verschachteltes Record Pattern verwenden, und zwar wie folgt:
public void print(Object o) {
switch (o) {
case Path(Position(int x1, int y1), Position(int x2, int y2)) ->
System.out.printf("o is a path: %d/%d -> %d/%d%n", x1, y1, x2, y2);
// other cases
}
}Code-Sprache: Java (java)In den bisherigen Beispielen bringt die Schreibweise mit Record Patterns keinen allzu großen Vorteil. Ihre wahre Stärke können Record Patterns dann zeigen, wenn sie mit Records verwendet werden, deren Elemente verschiedene Typen haben können.
Die wahre Stärke von Record Patterns
Wir ändern unsere Records etwas ab. Position wird zu einem Interface, welches von Position2D und Position3D implementiert wird. Und Path wird so angepasst, dass beide Parameter vom gleichen Typ sein müssen:
public sealed interface Position permits Position2D, Position3D {}
public record Position2D(int x, int y) implements Position {}
public record Position3D(int x, int y, int z) implements Position {}
public record Path<P extends Position>(P from, P to) {}
Code-Sprache: Java (java)Die print()-Methode ändern wir so ab, dass sie für einen 3D-Pfad etwas anderes anzeigt als für einen 2D-Pfad. Das ist ziemlich einfach zu bewerkstelligen:
public void print(Object o) {
switch (o) {
case Path(Position2D from, Position2D to) ->
System.out.printf("o is a 2D path: %d/%d -> %d/%d%n",
from.x(), from.y(), to.x(), to.y());
case Path(Position3D from, Position3D to) ->
System.out.printf("o is a 3D path: %d/%d/%d -> %d/%d/%d%n",
from.x(), from.y(), from.z(), to.x(), to.y(), to.z());
// other cases
}
}Code-Sprache: Java (java)So einfach war es allerdings nur, da wir mit der Variante mit Record Patterns begonnen haben!
Ohne Record Patterns müssten wir folgenden Code schreiben:
public void print(Object o) {
switch (o) {
case Path p when p.from() instanceof Position2D from
&& p.to() instanceof Position2D to ->
System.out.printf("o is a 2D path: %d/%d -> %d/%d%n",
from.x(), from.y(), to.x(), to.y());
case Path p when p.from() instanceof Position3D from
&& p.to() instanceof Position3D to ->
System.out.printf("o is a 3D path: %d/%d/%d -> %d/%d/%d%n",
from.x(), from.y(), from.z(), to.x(), to.y(), to.z());
// other cases
}
}Code-Sprache: Java (java)Dieses Mal ist die Variante mit Record Patterns deutlich prägnanter! Und je tiefer die Verschachtelung, desto größer der Vorteil, der sich durch Record Patterns ergibt.
Record Patterns wurden mit JDK Enhancement Proposal 440 finalisiert – mit einer Änderung gegenüber der letzten Preview-Version:
In Java 20 wurde die Möglichkeit eingeführt, Record Patterns auch in for-Schleifen zu verwenden, so wie in folgendem Beispiel:
List<Position> positions = ...
for (Position(int x, int y) : positions) {
System.out.printf("(%d, %d)%n", x, y);
}Code-Sprache: Java (java)Diese Option wurde in der finalen Version des Features gestrichen, mit der Aussicht, sie in einer zukünftigen Java-Version erneut einzuführen.
Pattern Matching for switch – JEP 441
„Pattern Matching for switch“ wurde erstmals in Java 17 als Preview-Feature vorgestellt und ermöglicht in Kombination mit Record Patterns, Switch-Statements (und -Ausdrücke) über ein beliebiges Objekt zu formulieren. Hier ein Beispiel:
Object obj = getObject();
switch (obj) {
case String s when s.length() > 5 -> System.out.println(s.toUpperCase());
case String s -> System.out.println(s.toLowerCase());
case Integer i -> System.out.println(i * i);
case Position(int x, int y) -> System.out.println(x + "/" + y);
default -> {}
}Code-Sprache: Java (java)Ohne Pattern Matching for switch müssten wir stattdessen folgenden, weniger ausdrucksstarken Code schreiben (dank des in Java 16 eingeführten Pattern Matching for instanceof ist er ohne explizite Cast dennoch einigermaßen gut lesbar):
Object obj = getObject();
if (obj instanceof String s && s.length() > 5) System.out.println(s.toUpperCase());
else if (obj instanceof String s) System.out.println(s.toLowerCase());
else if (obj instanceof Integer i) System.out.println(i * i);
else if (obj instanceof Position(int x, int y)) System.out.println(x + "/" + y);Code-Sprache: Java (java)Darüber hinaus führt der Compiler bei Pattern Matching for switch eine Vollständigkeitsanalyse (englisch: „analysis of exhaustiveness“) durch, d. h. das Switch-Statement oder der Switch-Ausdruck muss alle möglichen Fälle abdecken – oder einen default-Branch enthalten. Da die Object-Klasse im Beispiel oben beliebig erweiterbar ist, ist ein default-Branch zwingend erforderlich.
Nicht nötig ist ein default-Branch hingegen, wenn bei einer versiegelten Klassenhierarchie alle Möglichkeiten abgedeckt sind, wie in folgendem Beispiel:
public sealed interface Shape permits Rectangle, Circle {}
public record Rectangle(Position topLeft, Position bottomRight) implements Shape {}
public record Circle(Position center, int radius) implements Shape {}
public class ShapeDebugger {
public static void debug(Shape shape) {
switch (shape) {
case Rectangle r -> System.out.printf(
"Rectangle: top left = %s; bottom right = %s%n", r.topLeft(), r.bottomRight());
case Circle c -> System.out.printf(
"Circle: center = %s; radius = %s%n", c.center(), c.radius());
}
}
}Code-Sprache: Java (java)Da durch die Versiegelung sichergestellt ist, dass es nur zwei Shape-Implementierungen – nämlich Rectangle und Circle – gibt, wäre hier ein default-Zweig überflüssig (aber nicht verboten, s. u.).
Würden wir irgendwann Shape erweitern, z. B. um einen dritten Record Oval, dann würde der Compiler den Switch-Ausdruck als unvollständig erkennen und dies mit der Fehlermeldung 'switch' statement does not cover all possible input values quittieren:

Auf diese Weise können wir im Voraus sicherstellen, dass wir bei einer Erweiterung des Interfaces auch alle Switch-Ausdrücke anpassen müssen. Alternativ könnten wir vorab einen default-Zweig einbauen. Dann würde das switch-Statement weiterhin kompilieren und den default-Branch für Oval ausführen.
Mit dem JDK Enhancement Proposal 441 wurde Pattern Matching for switch mit zwei Änderungen gegenüber der letzten Preview-Version finalisiert:
„Parenthesized Patterns“ wurden entfernt
Bis Java 20 war es noch möglich, Patterns in Klammern zu setzen, z. B. so:
Object obj = getObject();
switch (obj) {
case (String s) when s.length() > 5 -> System.out.println(s.toUpperCase());
case (String s) -> System.out.println(s.toLowerCase());
case (Integer i) -> System.out.println(i * i);
case (Position(int x, int y)) -> System.out.println(x + "/" + y);
default -> {}
}Code-Sprache: Java (java)Da die Klammern keinen Zweck erfüllten, wurde diese Option in der finalen Version von „Pattern Matching for switch“ entfernt.
Qualifizierte Enum-Konstanten
Ein Switch-Ausdruck über Enum-Konstanten ließ sich bisher ausschließlich mit einem „Guarded Pattern“ – also einem Pattern kombiniert mit when – implementieren.
Was das bedeutet, zeige ich dir an einem Beispiel. Hier zunächst zwei Enums, die ein versiegeltes Interface implementieren:
public sealed interface Direction permits CompassDirection, VerticalDirection {}
public enum CompassDirection implements Direction { NORTH, SOUTH, EAST, WEST }
public enum VerticalDirection implements Direction { UP, DOWN }Code-Sprache: Java (java)Ein switch über alle möglichen Richtungen musste bis Java 20 wie folgt implementiert werden:
void flyJava20(Direction direction) {
switch (direction) {
case CompassDirection d when d == CompassDirection.NORTH -> System.out.println("Flying north");
case CompassDirection d when d == CompassDirection.SOUTH -> System.out.println("Flying south");
case CompassDirection d when d == CompassDirection.EAST -> System.out.println("Flying east");
case CompassDirection d when d == CompassDirection.WEST -> System.out.println("Flying west");
case VerticalDirection d when d == VerticalDirection.UP -> System.out.println("Gaining altitude");
case VerticalDirection d when d == VerticalDirection.DOWN -> System.out.println("Losing altitude");
default -> throw new IllegalArgumentException("Unknown direction: " + direction);
}
}Code-Sprache: Java (java)Bei dieser Schreibweise griff auch nicht die Vollständigkeitsanalyse, d. h. obwohl wir alle möglichen Fälle implementiert haben, ist dennoch ein default-Zweig notwendig. Andernfalls kommt es zu einem Compiler-Fehler.
In Java 21 können wir dieselbe Logik jetzt deutlich prägnanter formulieren, indem wir direkt die qualifizierten Enum-Konstanten angeben („qualifiziert“ heißt: inklusive Klassenname):
void flyJava21(Direction direction) {
switch (direction) {
case CompassDirection.NORTH -> System.out.println("Flying north");
case CompassDirection.SOUTH -> System.out.println("Flying south");
case CompassDirection.EAST -> System.out.println("Flying east");
case CompassDirection.WEST -> System.out.println("Flying west");
case VerticalDirection.UP -> System.out.println("Gaining altitude");
case VerticalDirection.DOWN -> System.out.println("Losing altitude");
}
}Code-Sprache: Java (java)Jetzt erkennt der Compiler auch, dass alle Fälle abgedeckt sind und fordert keinen default-Zweig mehr.
Neue Methoden in String, StringBuilder, StringBuffer, Character und Math
Nicht alle Änderungen findet man in den JEPs oder Release Notes. So findet man z. B. einige neue Methoden in String, StringBuilder, StringBuffer, Character und Math nur in der API-Dokumentation. Praktischerweise gibt es den Java Version Almanac, mit dem man verschiedene API-Versionen komfortabel vergleichen kann.
Neue String-Methoden
Die String-Klasse wurde um folgende Methoden erweitert:
String.indexOf(String str, int beginIndex, int endIndex)– sucht den angegebenen Substring in einem Teilbereich des Strings.String.indexOf(char ch, int beginIndex, int endIndex)– sucht das angegebene Zeichen in einem Teilbereich des Strings.String.splitWithDelimiters(String regex, int limit)– teilt den String an Teilzeichenfolgen, auf die der reguläre Ausdruck passt, und gibt ein Array aller Teile und teilenden Zeichenfolgen zurück. Es wird dabei maximallimit-1Mal geteilt, d. h. das letzte Element des Arrays kann ggf. weiter teilbar sein.
Hier ist ein Beispiel für splitWithDelimiters(…):
String string = "the red brown fox jumps over the lazy dog";
String[] parts = string.splitWithDelimiters(" ", 5);
System.out.println(Arrays.stream(parts).collect(Collectors.joining("', '", "'", "'")));Code-Sprache: Java (java)Diese Codezeilen geben Folgendes aus:
'the', ' ', 'red', ' ', 'brown', ' ', 'fox', ' ', 'jumps over the lazy dog'
Code-Sprache: Klartext (plaintext)Neue StringBuilder- und StringBuffer-Methoden
Sowohl StringBuilder als auch StringBuffer wurden um die folgenden zwei Methoden erweitert:
repeat(CharSequence cs, int count)– hängt an denStringBuilderoderStringBufferdie Zeichenkettecsan – und zwarcountMal.repeat(int codePoint, int count)– hängt an denStringBuilderoderStringBufferden angegebenen Unicode-Codepoint an – und zwarcountMal. Als codePoint kann auch eine Variable oder Konstante vom Typcharübergeben werden.
Hier ein Beispiel, das repeat(…) einmal mit einer Zeichenkette aufruft, einmal mit einem Codepoint und einmal mit einem Character:
StringBuilder sb = new StringBuilder();
sb.repeat("Hello ", 2);
sb.repeat(0x1f600, 5);
sb.repeat('!', 3);
System.out.println(sb);Code-Sprache: Java (java)Dieser Code gibt Folgendes aus:

Neue Character-Methoden
Wo wir schon bei Emojis sind... folgende neue Methoden bietet die Character-Klasse:
isEmoji(int)isEmojiComponent(int)isEmojiModifier(int)isEmojiModifierBase(int)isEmojiPresentation(int)isExtendedPictographic(int)
Diese Methoden prüfen, ob der übergebene Unicode-Codepoint für ein Emoji oder eine Variante davon steht. Was diese Varianten genau bedeuten, kannst du in Anhang A der Unicode-Emoji-Spezifikation nachlesen.
Neue Math-Methoden
Wie oft schon haben wir folgendes Stück Code geschrieben, um sicherzustellen, dass eine Zahl in einem vorgegebenen Wertebereich liegt, oder andernfalls hineingeschoben wird:
if (value < min) {
value = min;
} else if (value > max) {
value = max;
}
Code-Sprache: Java (java)Ab sofort können wir dafür die Math.clamp(-Methode verwenden, die es in folgenden vier Varianten gibt:…)
int clamp(long value, int min, int max)long clamp(long value, long min, long max)double clamp(double value, double min, double max)float clamp(float value, float min, float max)
Diese Methoden prüfen, ob value im Bereich min bis max liegt. Ist value kleiner als min, wird min zurückgegeben; ist value größer als max, wird max zurückgegeben.
Preview- und Incubator-Features
Auch wenn Java 21 eine Long-Term-Support-Version ist, enthält sie neue sowie wiedervorgelegte Preview-Features. Preview-Features müssen explizit mit der VM-Option --enable-preview aktiviert werden und werden in der Regel in folgenden Java-Versionen noch leicht überarbeitet.
Du kannst dich in den folgenden Abschnitten auf ein paar äußerst spannende neue Features freuen!
String Templates (Preview) – JEP 430
String Templates bieten eine dynamische Möglichkeit, Strings zu generieren, indem zur Laufzeit Platzhalter durch Variablenwerte und berechnete Ergebnisse ersetzt werden. Dieser als String-Interpolation bezeichnete Prozess ermöglicht es, komplexe Strings effizient zusammenzustellen:
int a = ...;
int b = ...;
String result = STR."\{a} times \{b} = \{Math.multiplyExact(a, b)}";Code-Sprache: Java (java)Während der Ausführung werden folgende Ersetzungen durchgeführt:
\{a}wird dynamisch durch den aktuellen Wert vonaersetzt.\{b}wird durch den Wert vonbersetzt.\{Math.multiplyExact(a, b)}wird durch das Ergebnis des MethodenaufrufsMath.multiplyExact(a, b)ersetzt.
String Templates wurden in Java 21 durch JDK Enhancement Proposal 430 als Preview-Feature eingeführt. Eine ausführlichere Beschreibung findest du im Hauptartikel über String Templates.
Unnamed Patterns and Variables (Preview) – JEP 443
Häufig müssen wir Variablen deklarieren, die letztendlich ungenutzt bleiben. Typische Beispiele hierfür sind Exceptions, Lambda-Parameter und Pattern-Variablen.
Betrachten wir ein Beispiel, in dem die Exception-Variable e ungenutzt bleibt:
try {
int number = Integer.parseInt(string);
} catch (NumberFormatException e) {
System.err.println("Not a number");
}Code-Sprache: Java (java)In diesem Fall bleibt der Lambda-Parameter k ungenutzt:
map.computeIfAbsent(key, k -> new ArrayList<>()).add(value);Code-Sprache: Java (java)Und in diesem Record-Pattern bleibt die Pattern-Variable position2 ungenutzt:
if (object instanceof Path(Position(int x1, int y1), Position position2)) {
System.out.printf("object is a path starting at x = %d, y = %d%n", x1, y1);
}Code-Sprache: Java (java)In Java 21 bieten unbenannte Variablen und Patterns – zunächst als Preview-Feature – eine elegantere Lösung, indem sie es ermöglichen, die Namen von ungenutzten Variablen oder sogar das gesamte Pattern durch einen Unterstrich (_) zu ersetzen:
Anstatt der Exception-Variable e können wir _ verwenden:
try {
int number = Integer.parseInt(string);
} catch (NumberFormatException _) {
System.err.println("Not a number");
}Code-Sprache: Java (java)Auch statt des Lambda-Parameters k verwenden wir _:
map.computeIfAbsent(key, _ -> new ArrayList<>()).add(value);Code-Sprache: Java (java)Und das vollständige Teil-Pattern Position position2 kann ebenfalls durch _ ersetzt werden:
if (object instanceof Path(Position(int x1, int y1), _)) {
System.out.printf("object is a path starting at x = %d, y = %d%n", x1, y1);
}Code-Sprache: Java (java)Unnamed Patterns and Variables werden in JDK Enhancement Proposal 443 definiert. Weitere Details und eine tiefergehende Betrachtung dieses Features findest du im Hauptartikel über unbenannte Variablen und Patterns.
Unnamed Classes and Instance Main Methods (Preview) – JEP 445
Wenn Programmieranfänger:innen ihr erstes Java-Programm schreiben, sieht das in der Regel so aus:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Code-Sprache: Java (java)Und das auch nur, wenn die Klasse im „unbenannten Paket“ liegt. Ansonsten kommt auch noch eine package-Deklaration hinzu.
Erfahrene Java-Entwickler:innen erkennen die Elemente dieses Programms auf den ersten Blick. Doch Anfänger:innen werden überwältigt von Visibility-Modifiern, komplexen Konzepten wie Klassen und statischen Methoden, unbenutzten Methoden-Argumenten und einem System.out.
Wäre es nicht schön, wenn man das meiste davon streichen könnte? Zum Beispiel so:

Genau das ist in Java 21 dank JDK Enhancement Proposal 445 jetzt möglich! Der folgende Code ist ab sofort ein gültiges, vollständiges Java-Programm:
void main() {
System.out.println("Hello world!");
}Code-Sprache: Java (java)Da sich das Feature noch im Preview-Stadium befindet, musst du den Code wie folgt kompilieren und starten:
$ javac --enable-preview --source 21 HelloWorld.java
$ java --enable-preview HelloWorld
Hello world!Code-Sprache: Klartext (plaintext)Alternativ kannst du das Programm auch ohne explizites Kompilieren starten:
$ java --enable-preview --source 21 HelloWorld.java
Hello world!Code-Sprache: Klartext (plaintext)Den neuesten Stand dieses Features findest du im Abschnitt Compact Source Files and Instance Main Methods (so wird das Feature ab Java 25 heißen) des Artikels über die Java-main()-Methode.
Die „unbenannte Klasse“
Die main()-Methode liegt übrigens nach wie vor in einer Klasse: der sogenannten „unbenannten Klasse“. Das ist kein gänzlich neues Konzept. So gab es bisher schon das „unbenannte Paket“ (eine Klasse ohne package-Deklaration) und das „unbenannte Modul“ (ein Java-Quellcodeverzeichnis ohne module-info.java-Datei).
Genau wie benannte Module nicht auf Code im unbenannten Modul zugreifen können und so wie Code aus benannten Packages nicht auf unbenannte Packages zugreifen kann, kann auch Code aus benannten Klassen nicht auf unbenannte Klassen zugreifen.
Die unbenannte Klasse darf übrigens auch Felder und weitere Methoden haben. Auch das folgende ist ein gültiges und vollständiges Java-Programm:
final String HELLO_TEMPLATE = "Hello %s!";
void main() {
System.out.println(hello("world"));
}
String hello(String name) {
return HELLO_TEMPLATE.formatted(name);
}Code-Sprache: Java (java)Launch-Protokoll
Die main()-Methode darf natürlich auch weiterhin als public static markiert sein und das String[]-Argument enthalten. Sie darf auch nur public oder nur static sein. Oder auch protected. Theoretisch kann eine Klasse auch zwei main()-Methoden enthalten – beispielsweise wäre auch Folgendes erlaubt:
protected static void main() {
// ...
}
public void main(String[] args) {
// ...
}Code-Sprache: Java (java)In so einem Fall entscheidet das sogenannte „Launch-Protokoll“, welche der main()-Methoden gestartet wird. Das Launch-Protokoll sucht in folgender Reihenfolge; der Visibility-Modifier ist dabei irrelevant (nur private ist nicht erlaubt):
static void main(String[] args)static void main()void main(String[] args)– diese Methode darf auch von einer Oberklasse geerbt sein (das funktioniert allerdings nur in einer benannten Klasse)void main()– auch diese Methode darf von einer Oberklasse geerbt sein
Im Beispiel oben würde also die statische Methode ohne Parameter (Launch-Priorität 2) ausgeführt werden.
Scoped Values (Preview) – JEP 446
Scoped Values sind eine moderne Alternative zu ThreadLocal-Variablen, die sich sehr gut im Kontext virtueller Threads einsetzen lassen.
Scoped Values haben gegenüber ThreadLocal-Variablen den Vorteil,
- dass sie nur für einen definierten Zeitraum („Scope“) gültig sind,
- dass sie immutable sind und
- dass sie deswegen vererbt werden können, ohne dabei kopiert werden zu müssen (wie es bei
InheritableThreadLocalder Fall ist).
Die ersten beiden Punkte führen zudem zu übersichtlicherem und damit weniger fehleranfälligem Programmcode.
Scoped Values wurden in Java 20 im Incubator-Stadium vorgestellt und werden in Java 21 durch JDK Enhancement Proposal 446 ohne weitere Änderungen ins Preview-Stadium überführt.
Wie Scoped Values genau funktionieren, erfährst du anhand eines Beispiels im Hauptartikel über Scoped Values.
Structured Concurrency (Preview) – JEP 453
Um eine Aufgabe in mehrere parallel abzuarbeitende Teilaufgaben aufzuteilen, stellt Java bisher zwei High-Level-Konstrukte zur Verfügung:
- Parallele Streams, um die gleiche Operation parallel auf mehreren Elementen auszuführen
ExecutorService, um unterschiedliche Aufgaben parallel zu erledigen
ExecutorService ist sehr mächtig, was den Implementierungsaufwand für einfache parallele Arbeiten schnell in die Höhe treibt. Zum Beispiel ist es ziemlich kompliziert (und damit fehleranfällig) zu erkennen, wenn eine Teilaufgabe eine Exception geworfen hat, um dann sofort alle anderen noch laufenden Teilaufgaben sauber abzubrechen.
Mit Structured Concurrency wird ein neuer, einfach zu implementierender Mechanismus zur Verfügung gestellt, um eine Aufgabe in parallel abzuarbeitende Teilaufgaben aufzuteilen, die Ergebnisse der Teilaufgaben zusammenzuführen und Teilaufgaben abzubrechen, sollte deren Ergebnis nicht mehr benötigt werden.
Wie das funktioniert, erfährst du im Hauptartikel über Structured Concurrency.
Structured Concurrency wurde erstmals in Java 19 im Incubator-Stadium vorgestellt und in Java 20 dahingehend erweitert, dass Subtasks die im vorherigen Abschnitt beschriebenen Scoped Values des Eltern-Threads erben.
In Java 21 wurde durch JDK Enhancement Proposal 453 der Rückgabetyp von StructuredTaskScope.fork(...) – also derjenigen Methode, die Subtasks startet – von Future in Subtask geändert. Das soll den Unterschied von Structured Concurrency und der ExecutorService-API deutlich machen.
Zum Beispiel wartet die Future.get()-Methode auf ein Ergebnis, während Subtask.get() erst dann aufgerufen werden darf, wenn ein Subtask beendet ist – andernfalls wirft die Methode eine IllegalStateException. Und Subtask.state() liefert einen Status zurück, der spezifisch für Structured Concurrency ist, während Future.isDone() und isCancelled() dies nicht ermöglichen.
Foreign Function & Memory API (Third Preview) – JEP 442
Wer bisher auf Code außerhalb der JVM (z. B. Funktionen in C-Bibliotheken) oder auf nicht von der JVM verwalteten Speicher zugreifen wollte, musste dazu das Java Native Interface (JNI) bemühen. Wer das schon einmal gemacht hat, weiß, wie umständlich, fehleranfällig und langsam JNI ist.
Bereits seit Java 14 wird – zunächst in Incubator-Projekten – an einem Ersatz für JNI gearbeitet. In Java 19 wurde dann die einheitliche „Foreign Function & Memory API“ in einer ersten Preview-Version vorgestellt.
Was diese API ermöglicht, demonstriere ich an einem einfachen Beispiel.
Der folgende Code zeigt, wie du ein Handle auf die strlen()-Methode der Standard-C-Library beziehst, die Zeichenkette „Happy Coding!“ im nativen Speicher (also außerhalb des Java-Heaps) ablegst und anschließend die strlen()-Methode auf diesem String ausführst:
public class FFMTest21 {
public static void main(String[] args) throws Throwable {
// 1. Get a lookup object for commonly used libraries
SymbolLookup stdlib = Linker.nativeLinker().defaultLookup();
// 2. Get a handle to the "strlen" function in the C standard library
MethodHandle strlen = Linker.nativeLinker().downcallHandle(
stdlib.find("strlen").orElseThrow(),
FunctionDescriptor.of(JAVA_LONG, ADDRESS));
// 3. Convert Java String to C string and store it in off-heap memory
try (Arena offHeap = Arena.ofConfined()) {
MemorySegment str = offHeap.allocateUtf8String("Happy Coding!");
// 4. Invoke the foreign function
long len = (long) strlen.invoke(str);
System.out.println("len = " + len);
}
// 5. Off-heap memory is deallocated at end of try-with-resources
}
}Code-Sprache: Java (java)Der Code unterscheidet sich von der Java-20-Variante nur in einem Detail: Die Arena.ofConfined()-Methode hieß zuvor openConfined().
Kompilieren und ausführen kannst du das kleine Beispiel-Programm wie folgt:
$ javac --enable-preview --source 21 FFMTest21.java
Note: FFMTest21.java uses preview features of Java SE 21.
Note: Recompile with -Xlint:preview for details.
$ java --enable-preview --enable-native-access=ALL-UNNAMED FFMTest21
len = 13Code-Sprache: Klartext (plaintext)Du kannst natürlich auch beide Schritte zu einem zusammenfassen:
$ java --enable-preview --source 21 --enable-native-access=ALL-UNNAMED FFMTest21.java
Note: FFMTest21.java uses preview features of Java SE 21.
Note: Recompile with -Xlint:preview for details.
len = 13Code-Sprache: Klartext (plaintext)Der Zugriff auf nativen Speicher und der Aufruf von nativem Code sind eher ein Spezialgebiet. Die wenigsten Programmierer:innen werden damit direkt in Berührung kommen. Daher werde ich an dieser Stelle nicht weiter ins Detail gehen. Einzelheiten über den aktuellen Stand der FFM-API findest du in JDK Enhancement Proposal 442.
Vector API (Sixth Incubator) – JEP 448
Die neue Vector API wird in Java 21 durch JDK Enhancement Proposal 448 zum sechsten Mal in Folge als Incubator-Version vorgelegt.
Die Vector API wird es ermöglichen, mathematische Vektor-Operationen effizient auszuführen. Eine Vektor-Operation ist z. B. eine Vektor-Addition, wie du sie vielleicht noch aus dem Mathematik-Unterricht kennst:
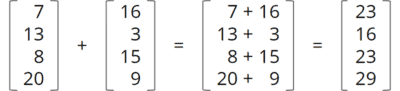
Moderne CPUs können solche Operationen bis zu einer bestimmten Vektorgröße in einem einzigen CPU-Zyklus ausführen. Die Vektor-API wird die JVM in die Lage versetzen, solche Operationen auf die effizientesten Instruktionen der zugrunde liegenden CPU-Architektur abzubilden.
Ich werde die Vektor-API im Detail vorstellen, sobald sie dem Incubator-Stadium entwachsen ist und in der ersten Preview-Version vorliegt.
Sonstige Änderungen in Java 21
Kommen wir zu den Änderungen, mit denen wir in der Regel nicht täglich konfrontiert sein werden. Zumindest nicht direkt. Es sei denn, wir sind beispielsweise für die Auswahl des Garbage Collectors und dessen Optimierung zuständig. Dann dürften die zwei folgenden JEPs interessant sein:
Generational ZGC – JEP 439
Der Z Garbage Collector – kurz ZGC – wurde in Java 11 als experimentelles Feature eingeführt und in Java 15 produktionsreif. Der ZGC verspricht Pausenzeiten von weniger als 10 Millisekunden – was um bis zu Faktor 10 unter den Pausenzeiten des Standard-Garbage-Collectors G1GC liegt.
Bisher machte ZGC keinen Unterschied zwischen „alten“ und „neuen“ Objekten. Genau dieser Unterschied kann aber laut der „Schwachen Generationshypothese“ (englisch: „Weak Generational Hypothesis“) großen Einfluss auf die Performance einer Anwendung haben.
Laut dieser Hypothese sterben die meisten Objekte kurz nach ihrer Erzeugung, wohingegen Objekte, die bereits einige GC-Zyklen überlebt haben, in der Regel noch eine Weile länger am Leben bleiben.
Das macht sich ein sogenannter „Generational Garbage Collector“ zunutze, indem er den Heap in zwei logische Bereiche aufteilt: eine „junge Generation“, in der neue Objekte angelegt werden, und eine „alte Generation“, in die Objekte verschoben werden, die ein gewisses Alter erreicht haben. Da Objekte in der alten Generation mit hoher Wahrscheinlichkeit noch älter werden, kann die Leistung einer Anwendung dadurch erhöht werden, dass der Garbage Collector die alte Generation seltener scannt.
Die Implementierung eines Garbage Collectors mit mehreren Generationen ist allerdings wegen der potentiellen Referenzen zwischen den Generationen deutlich aufwändiger als die Implementierung eines „Non-generational GCs“.
Daher mussten wir bis Java 21 warten, bis mit dem JDK Enhancement Proposal 439 der Z Garbage Collector zu einem „Generational Garbage Collector“ wurde.
Für eine Übergangsphase wird es beide Varianten des ZGC geben. Die VM-Option -XX:+UseZGC aktiviert nach wie vor die alte Variante ohne Generationen. Um die neue Variante mit Generationen zu aktivieren, müssen folgende VM-Optionen angegeben werden:
-XX:+UseZGC -XX:+ZGenerational
Wie genau der Generational ZGC funktioniert, kannst du in JEP 439 nachlesen.
Deprecate the Windows 32-bit x86 Port for Removal – JEP 449
Die 32-Bit-Version von Windows 10 wird kaum noch verwendet, der Support endet im Oktober 2025, und Windows 11 – seit Oktober 2021 auf dem Markt – wurde nie in einer 32-Bit-Version angeboten.
Entsprechend besteht auch kaum noch Bedarf an einer 32-Bit-Windows-Version des JDK.
Um die Entwicklung des JDK zu beschleunigen, wurden Virtuelle Threads bereits nicht mehr für 32-Bit-Windows implementiert. Wer auf 32-Bit-Windows einen virtuellen Thread starten will, bekommt einfach einen Plattform-Thread.
Durch JDK Enhancement Proposal 449 wird die 32-Bit-Windows-Portierung als „deprecated for removal“ markiert.
Prepare to Disallow the Dynamic Loading of Agents – JEP 451
Falls du schon einmal einen Java-Profiler verwendet hast, hast du die zu analysierende Anwendung wahrscheinlich mit einem Parameter wie -agentpath:<path-to-agent-library> gestartet. Dadurch wird ein sogenannter „Agent“ in die Anwendung geladen, der diese zur Laufzeit so modifiziert, dass die nötigen Messungen durchgeführt und die Ergebnisse entweder in eine Datei geschrieben oder an das Frontend des Profilers geschickt werden.
Falls die Anwendung ohne diesen Parameter gestartet wurde, kann der Agent auch nachträglich über die sogenannte „Attach API“ in die JVM „injiziert“ werden.
Dieses sogenannte „dynamische Laden“ ist standardmäßig aktiviert und stellt damit ein nicht unerhebliches Sicherheitsrisiko dar.
In einer zukünftigen Java-Version soll das dynamische Laden daher standardmäßig deaktiviert sein und nur explizit über die VM-Option -XX:+EnableDynamicAgentLoading aktivierbar sein.
Da so eine Änderung nicht von heute auf morgen erfolgen kann, ist das dynamische Laden in Java 21 nach wie vor erlaubt, kann aber mit -XX:-EnableDynamicAgentLoading explizit deaktiviert werden. Zudem werden nun Warnungen angezeigt, wenn ein Agent über die Attach API nachträglich geladen wird.
Diese Änderung ist in JDK Enhancement Proposal 451 definiert. Dort findest du auch eine detaillierte Auflistung der Sicherheitsrisiken.
Key Encapsulation Mechanism API – JEP 452
Key Encapsulation Mechanism (KEM) ist eine moderne Verschlüsselungstechnik, die den Austausch symmetrischer Schlüssel über ein asymmetrisches Verschlüsselungsverfahren ermöglicht. KEMs sind so sicher, dass sie sogar zukünftigen Quantenangriffen standhalten sollen.
Durch das JDK Enhancement Proposal 452 stellt das JDK eine API für die Nutzung von KEM bereit.
Die wenigsten von uns werden direkt mit der Implementierung von Ver- und Entschlüsselung konfrontiert. In der Regel nutzen wir sie nur indirekt, zum Beispiel durch die Verwendung von SSH oder den Zugriff auf eine HTTPS-Schnittstelle.
Aus diesem Grund werde ich nicht detaillierter auf diesen JEP eingehen.
Thread.sleep(millis, nanos) Is Now Able to Perform Sub-Millisecond Sleeps
Beim Aufruf von Thread.sleep(millis, nanos) wurde der nanos-Wert bisher quasi ignoriert. Es wurde lediglich, wenn nanos größer als 500.000 (also eine halbe Millisekunde) war, der millis-Wert um eins erhöht und dann Thread.sleep(millis) aufgerufen.
Ab Java 21 wird die Wartezeit – zumindest auf Linux und macOS – auf Nanosekunden-Granularität ans Betriebssystem weitergegeben (bzw. im Falle eines virtuellen Threads an den „Unparker“). Die tatsächliche Wartezeit ist nach wie vor von der Präzision der Systemuhr und des Schedulers abhängig.
(Für diese Änderung gibt es keinen JEP; sie ist im Bug Tracker unter JDK-8305092 beschrieben.)
Last Resort G1 Full GC Moves Humongous Objects
Beim G1-Garbage-Collector (G1GC) wird der zur Verfügung stehende Heap-Speicher in bis zu 2.048 Regionen aufgeteilt. Objekte, die größer als die Hälfte einer solchen Region sind, werden als „humongous objects“ (zu Deutsch: „riesige Objekte“) bezeichnet.
Humongous objects wurden bisher niemals im Speicher verschoben. So konnte es bei starker Fragmentierung des Heaps zu einem OutOfMemoryError kommen, selbst wenn insgesamt noch ausreichend Speicher zur Verfügung stand – nur eben nicht in einem zusammenhängenden Bereich.
Ab Java 21 werden nun auch riesige Objekte verschoben – allerdings erst dann, wenn nach einem Full GC nicht ausreichend zusammenhängender Speicher zur Verfügung steht. Dieser Vorgang kann je nach Größe des Heaps ziemlich lange (bis zu mehreren Sekunden) in Anspruch nehmen.
(Für diese Änderung gibt es keinen JEP; sie ist im Bug Tracker unter JDK-8191565 beschrieben.)
Implement Alternative Fast-Locking Scheme
Wenn ein Thread einen synchronized-Block auf einem Objekt betritt, muss die JVM diese Information irgendwo speichern, um zu verhindern, dass ein anderer Thread den kritischen Bereich betritt.
Dies geschieht bisher über einen Mechanismus, der sich „Stack Locking“ nennt. Dabei wird das Mark Word des Objekt Headers durch einen Pointer auf eine Datenstruktur auf dem Stack ersetzt, die dann wiederum das Mark Word und weitere Informationen über den Lock-Zustand enthält.
Dieser Mechanismus erschwert zum einen den Zugriff auf die eigentlichen Daten des Mark Words. Zum anderen ist der Pointer auf den Stack mit ein Grund für das sogenannte Pinning von virtuellen Threads.
In Java 21 wird ein alternativer Locking-Mechanismus angeboten, das sogenannte „Lightweight Locking“. Dabei werden lediglich die zwei „Tag Bits“ im Mark Word gesetzt; zusätzliche Lock-Datenstrukturen werden in einer Hashtable und einem Thread-lokalen Cache abgelegt. Auf das Mark Word kann so immer direkt zugegriffen werden.
Lightweight Locking kann über die im nächsten Abschnitt beschriebene VM-Option aktiviert werden.
(Für diese Änderung gibt es keinen JEP; sie ist im Bug Tracker unter JDK-8291555 beschrieben.)
Add Experimental -XX:LockingMode Flag
Locking erfolgt in der Regel in zwei Schritten:
- Sobald ein Thread einen kritischen Bereich betritt, wird zunächst nur im Monitor-Objekt (das Objekt, das hinter
synchronizedin Klammern angegeben wird) die Information gespeichert, dass der Bereich gelockt ist – weitere Informationen sind zu diesem Zeitpunkt nicht nötig. - Erst wenn ein weiterer Thread versucht, den kritischen Bereich zu betreten, muss u. a. eine Liste der wartenden Threads angelegt werden. Dafür wird dann eine zusätzliche Datenstruktur erzeugt, der sogenannte „schwergewichtige Monitor“.
Schritt 1 erfolgte bisher durch das sogenannte „Stack Locking“. Durch die VM-Option -XX:+UseHeavyMonitors konnte Schritt 1 übersprungen und direkt der „schwergewichtige Monitor“ erzeugt werden.
Um den im vorherigen Abschnitt beschriebenen neuen Locking-Mechanismus zu aktivieren, wird die VM-Option -XX:LockingMode eingeführt, mit den folgenden Optionen:
| VM-Option | Bezeichnung | Erläuterung |
|---|---|---|
-XX:LockingMode=0 | LM_MONITOR | Ausschließlich schwergewichtige Monitor-Objekte (Schritt 1 wird übersprungen); entspricht der bisherigen Option -XX:+UseHeavyMonitors |
-XX:LockingMode=1 | LM_LEGACY | Stack Locking + Monitor-Objekte bei Contention; entspricht dem bisherigen Standardverhalten |
-XX:LockingMode=2 | LM_LIGHTWEIGHT | Lightweight Locking + Monitor-Objekte bei Contention; dies ist der neue, im vorherigen Abschnitt beschriebene Modus. |
Da sich das Feature aktuell noch im experimentellen Stadium befindet, muss zusätzlich die VM-Option -XX:+UnlockExperimentalVMOptions angegeben werden.
(Für diese Änderung gibt es keinen JEP; sie ist im Bug Tracker unter JDK-8305999 beschrieben.)
Vollständige Liste aller Änderungen in Java 21
In diesem Artikel hast du alle Java Enhancement Proposals kennengelernt, die in Java 21 umgesetzt wurden. Weitere kleinere Änderungen findest du in den offiziellen Java 21 Release Notes.
Fazit
Das neue LTS-Release Java 21 bringt mit der Finalisierung von Virtuellen Threads eine der bedeutendsten Veränderungen der Java-Geschichte, die die Implementierung von hochskalierbaren Serveranwendungen deutlich vereinfachen wird.
Record Patterns, Pattern Matching for switch, Sequenced Collections, String Templates und Unnamed Patterns and Variables (die letzten zwei davon noch im Preview-Stadium) machen die Sprache ausdrucksstärker und robuster.
Unnamed Classes and Instance Main Methods (ebenfalls im Preview-Stadium) erleichtern Programmierer:innen den Einstieg in die Sprache, ohne gleich zu Beginn komplexe Konstrukte wie Klassen und statische Methoden verstehen zu müssen.
Diverse sonstige Änderungen runden wie immer das Release ab. Die aktuelle Java-21-Version kannst du hier (OpenJDK) und hier (Oracle) herunterladen.
Auf welches Java-21-Feature freust du dich am meisten? Welches Feature vermisst du? Lasse es mich gerne über die Kommentarfunktion wissen!