


Virtuelle Threads in Java – Deep Dive mit Beispielen
Virtuelle Threads („virtual threads") sind eine der wichtigsten Neuerungen in Java seit langem. Sie wurden in Project Loom entwickelt und sind seit Java 19 als Preview-Feature im JDK enthalten und seit Java 21 in ihrer finalen Version (JEP 444).
In diesem Artikel erfährst du:
- Warum brauchen wir virtuelle Threads?
- Was sind virtuelle Threads, und wie funktionieren sie?
- Wie setzt man virtuelle Threads ein?
- Wie erzeugt man virtuelle Threads, und wie viele virtuelle Threads lassen sich starten?
- Wie verwendet man virtuelle Threads in Spring und Jakarta EE?
- Was sind die Vorteile von virtuellen Threads?
- Was sind virtuelle Threads nicht, und welche Einschränkungen weisen sie auf?
Beginnen wir bei der Herausforderung, die zur Entwicklung virtueller Threads geführt hat.
Warum brauchen wir virtuelle Threads?
Wer jemals eine Backend-Anwendung unter hoher Last betreut hat, weiß: Threads sind oft das Bottleneck. Denn für jeden eingehenden Request wird ein Thread benötigt, der den Request abarbeitet. Ein Java-Thread entspricht einem Betriebssystem-Thread, und diese sind ressourcenhungrig:
- Ein Betriebssystem-Thread reserviert 1 MB für den Stack im Voraus und committet 32 oder 64 KB davon, je nach Betriebssystem.
- Es dauert etwa 1 ms, um einen Betriebssystem-Thread zu starten.
- Context-Switches finden im Kernel-Space statt und sind recht CPU-intensiv.
Mehr als ein paar Tausend sollte man also nicht starten, sonst riskiert man die Stabilität des gesamten Systems.
Ein paar Tausend reichen jedoch nicht immer – insbesondere dann nicht, wenn die Bearbeitung eines Requests länger dauert, weil auf blockierende Datenstrukturen, wie z. B. Queues, Locks, oder externe Dienste wie Datenbanken, Microservices oder Cloud-APIs gewartet werden muss.
Wenn ein Request beispielsweise zwei Sekunden dauert und wir den Thread-Pool auf 1.000 Threads limitieren, dann könnten maximal 500 Anfragen pro Sekunde beantwortet werden. Die CPU wäre aber bei weitem nicht ausgelastet, da sie die meiste Zeit auf die Antworten der externen Dienste warten würde, selbst wenn pro CPU-Core mehrere Threads bedient werden.
Bislang konnten wir dieses Problem nur mit asynchroner Programmierung bewältigen – z. B. mit CompletableFuture oder reaktiven Frameworks wie RxJava und Project Reactor.
Wer allerdings schon einmal Code wie den folgenden warten musste, weiß, dass asynchroner Code um ein Vielfaches komplexer ist als sequentieller Code – und absolut keinen Spaß macht.
public CompletionStage<Response> getProduct(String productId) {
return productService
.getProductAsync(productId)
.thenCompose(
product -> {
if (product.isEmpty()) {
return CompletableFuture.completedFuture(
Response.status(Status.NOT_FOUND).build());
}
return warehouseService
.isAvailableAsync(productId)
.thenCompose(
available ->
available
? CompletableFuture.completedFuture(0)
: supplierService.getDeliveryTimeAsync(
product.get().supplier(), productId))
.thenApply(
daysUntilShippable ->
Response.ok(
new ProductPageResponse(
product.get(), daysUntilShippable))
.build());
});
}Code-Sprache: Java (java)Nicht nur, dass dieser Code kaum lesbar ist, er ist auch extrem schwer zu debuggen. Beispielsweise würde es hier keinen Sinn machen einen Breakpoint zu setzen, denn der Code definiert nur den asynchronen Flow, führt ihn aber nicht aus. Ausgeführt wird der eigentliche Business Code erst zu einem späteren Zeitpunkt in einem dafür vorgesehenen Thread-Pool.
Darüber hinaus müssen die eingesetzten Datenbanktreiber und Treiber für andere externe Dienste das asynchrone, nicht-blockierende Modell ebenso unterstützen.
Was sind virtuelle Threads?
Virtuelle Threads lösen das Problem auf eine Art und Weise, die es uns wieder erlaubt, leicht lesbaren und wartbaren Code zu schreiben. Virtuelle Threads fühlen sich aus Sicht des Java-Codes wie ganz normale Threads an, werden aber nicht 1:1 auf Betriebssystem-Threads gemappt.
Stattdessen gibt es einen Pool sogenannter Träger-Threads (Carrier Threads), auf die ein virtueller Thread vorübergehend gemappt wird (englisch: „mounted“). Sobald der virtuelle Thread auf eine blockierende Operation stößt, wird der virtuelle Thread vom Träger-Thread genommen (englisch: „unmounted“), und der Träger-Thread kann einen anderen virtuellen Thread (einen neuen oder einen zuvor blockierten) ausführen.
Die folgende Grafik stellt diese M:N-Zuordnung von virtuellen Threads zu Träger-Threads und damit zu Betriebssystem-Threads dar:
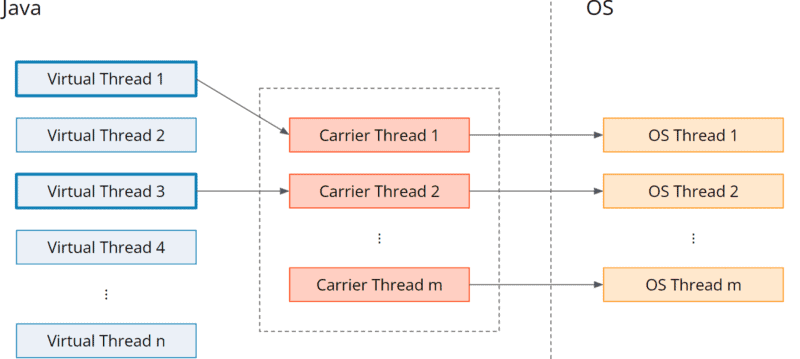
Beim Träger-Thread-Pool handelt es sich um einen ForkJoinPool – also einen Pool, bei dem jeder Thread seine eigene Queue hat und Tasks von den Queues anderer Threads „stiehlt“, sollte seine eigene Queue leer sein. Seine Größe wird standardmäßig auf Runtime.getRuntime().availableProcessors() gesetzt und kann mit der VM-Option jdk.virtualThreadScheduler.parallelism angepasst werden.
Im zeitlichen Verlauf könnte beispielsweise die CPU-Aktivität von drei Tasks, die jeweils viermal Code ausführen und dazwischen dreimal verhältnismäßig lange blockieren, wie folgt auf einen einzigen Carrier-Thread gemappt werden:

Blockierende Operationen blockieren somit den ausführenden Träger-Thread nicht, und wir können mit einem kleinen Pool von Träger-Threads eine Vielzahl von Requests parallel bearbeiten.
Den Beispiel-Use-Case von oben könnte man dann ganz einfach mit sequentiellem, blockierenden Code wie folgt implementieren:
public ProductPageResponse getProduct(String productId) {
Product product = productService.getProduct(productId)
.orElseThrow(NotFoundException::new);
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}Code-Sprache: Java (java)Dieser Code ist nicht nur einfacher zu schreiben und zu lesen, sondern auch – wie jeder sequentielle Code – mit herkömmlichen Mitteln zu debuggen.
Falls dein Code bereits so aussieht – du also nie auf asynchrone Programmierung umgestellt hast, dann habe ich gute Nachrichten: du kannst deinen Code unverändert mit virtuellen Threads weiterverwenden.
Virtuelle Threads – Beispiel
Die Mächtigkeit virtueller Threads können wir auch ohne Backend-Framework demonstrieren. Dazu simulieren wir ein Szenario, das dem oben beschriebenen ähnelt: wir starten 1.000 Tasks, die jeweils eine Sekunde warten (um den Zugriff auf eine externe API zu simulieren) und dann ein Ergebnis (im Beispiel eine Zufallszahl) zurückliefern.
Als erstes implementieren wir den Task:
public class Task implements Callable<Integer> {
private final int number;
public Task(int number) {
this.number = number;
}
@Override
public Integer call() {
System.out.printf("Thread %s - Task %d waiting...%n",
Thread.currentThread().getName(), number);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.printf("Thread %s - Task %d canceled.%n",
Thread.currentThread().getName(), number);
return -1;
}
System.out.printf("Thread %s - Task %d finished.%n",
Thread.currentThread().getName(), number);
return ThreadLocalRandom.current().nextInt(100);
}
}Code-Sprache: Java (java)Nun messen wir, wie lange es mit einem Pool von 100 Plattform-Threads (so werden nicht virtuelle Threads bezeichnet) dauert, alle 1.000 Tasks abzuarbeiten:
try (ExecutorService executor = Executors.newFixedThreadPool(100)) {
List<Task> tasks = new ArrayList<>();
for (int i = 0; i < 1_000; i++) {
tasks.add(new Task(i));
}
long time = System.currentTimeMillis();
List<Future<Integer>> futures = executor.invokeAll(tasks);
long sum = 0;
for (Future<Integer> future : futures) {
sum += future.get();
}
time = System.currentTimeMillis() - time;
System.out.println("sum = " + sum + "; time = " + time + " ms");
}Code-Sprache: Java (java)Das Programm läuft etwas über 10 Sekunden. Das war zu erwarten:
1.000 Tasks geteilt durch 100 Threads = 10 Tasks pro Thread
Jeder Plattform-Thread musste 10 Tasks, die jeweils etwa 1 Sekunde dauerten, sequentiell abarbeiten.
Als nächstes testen wir das ganze mit virtuellen Threads. Dazu müssen wir lediglich den Ausdruck
Executors.newFixedThreadPool(100)Code-Sprache: Java (java)ersetzen durch:
Executors.newVirtualThreadPerTaskExecutor()Code-Sprache: Java (java)Dieser Executor verwendet keinen Thread-Pool, sondern legt für jeden Task einen neuen virtuellen Thread an.
Danach benötigt das Programm keine 10 Sekunden mehr, sondern nur noch knapp über eine Sekunde. Schneller geht es auch kaum, da ja jeder Task eine Sekunde wartet.
Beeindruckend: selbst 10.000 Tasks kann unser kleines Programm in etwas über einer Sekunde abarbeiten.
Erst bei 100.000 Tasks lässt der Durchsatz spürbar nach: hierfür benötigt mein Laptop etwa vier Sekunden – was aber immer noch rasend schnell ist im Vergleich zum Thread-Pool, der dafür knapp 17 Minuten brauchen würde.
Wie erzeugt man virtuelle Threads?
Eine Möglichkeit zur Erzeugung virtueller Threads haben wir bereits kennengelernt: Ein Executor Service, den wir mit Executors.newVirtualThreadPerTaskExecutor() erzeugen, erstellt pro Task einen neuen virtuellen Thread.
Mittels Thread.startVirtualThread() oder Thread.ofVirtual().start() können wir virtuelle Threads auch explizit starten:
Thread.startVirtualThread(() -> {
// code to run in thread
});
Thread.ofVirtual().start(() -> {
// code to run in thread
});Code-Sprache: Java (java)Bei der zweiten Variante liefert Thread.ofVirtual() einen Thread.Builder.OfVirtual zurück, dessen start()-Methode einen virtuellen Thread startet. Die alternative Methode Thread.ofPlatform() liefert einen Thread.Builder.OfPlatform zurück, über den ein Plattform-Thread gestartet werden kann.
Beide sind Subinterfaces von Thread.Builder. Das ermöglicht uns flexiblen Code zu schreiben, bei dem erst zur Laufzeit entschieden wird, ob dieser in einem virtuellen oder in einem Plattform-Thread laufen soll:
Thread.Builder threadBuilder = createThreadBuilder();
threadBuilder.start(() -> {
// code to run in thread
});Code-Sprache: Java (java)Herauszufinden, ob Code in einem virtuellen Thread läuft, kannst du übrigens mit Thread.currentThread().isVirtual().
Wie viele virtuelle Threads können gestartet werden?
In diesem GitHub-Repository findest du zahlreiche Demo-Programme, die die Fähigkeiten von virtuellen Threads demonstrieren.
Mit der Klasse HowManyVirtualThreadsDoingSomething kannst du testen, wie viele virtuelle Threads du auf deinem System laufen lassen kannst. Die Anwendung startet mehr und mehr Threads und führt in diesen Threads Thread.sleep()-Operationen in einer Endlosschleife durch, um das Warten auf die Antwort von einer Datenbank oder einer externen API zu simulieren. Versuche dem Programm mit der VM-Option -Xmx so viel Heap-Speicher wie möglich zur Verfügung zu stellen.
Auf meinem 64-GB-Rechner ließen sich problemlos 20.000.000 virtuelle Threads starten – und mit etwas Geduld auch 30.000.000. Ab dann versuchte der Garbage Collector pausenlos Full GCs durchzuführen – denn der Stack von virtuellen Threads wird auf dem Heap, in sogenannten StackChunk-Objekten „geparkt“, sobald ein virtueller Thread blockiert. Kurz darauf beendete sich die Anwendung mit einem OutOfMemoryError.
Mit der Klasse HowManyPlatformThreadsDoingSomething kannst du außerdem testen, wie viele Plattform-Threads dein System unterstützt. Doch sei gewarnt: Meistens endet das Programm irgendwann mit einem OutOfMemoryError (bei mir zwischen 80.000 und 90.000 Threads) – es kann aber auch deinen Rechner zum Absturz bringen.
Wie verwendet man virtuelle Threads mit Jakarta EE?
In einer Jakarta-EE-Anwendung erzeugst du Threads nicht selbst – das überlässt du dem Container. Seit Jakarta EE 11 (Jakarta Concurrency 3.1) kannst du anfordern, dass ein managed Executor oder eine managed Thread-Factory virtuelle Threads verwendet. Dazu setzt du das Attribut virtual = true, z. B. an einer @ManagedExecutorDefinition:
@ManagedExecutorDefinition(
name = "java:app/concurrent/virtualExecutor",
virtual = true)Code-Sprache: Java (java)Das gleiche Attribut gibt es auch bei @ManagedScheduledExecutorDefinition und @ManagedThreadFactoryDefinition. Den so definierten Executor injizierst du anschließend und führst deine Tasks darüber aus. Standardmäßig ist virtual auf false gesetzt – der Container erzeugt also weiterhin Plattform-Threads, solange du virtuelle Threads nicht explizit aktivierst.
Einen einzelnen REST-Endpoint kannst du im Standard von Jakarta EE (Stand Jakarta EE 11) allerdings nicht per Annotation direkt auf einen virtuellen Thread legen. Genau das bietet aber das Quarkus-/SmallRye-Ökosystem mit der Annotation @RunOnVirtualThread – dazu mehr im nächsten Abschnitt.
Wie verwendet man virtuelle Threads mit Quarkus?
Quarkus bietet die Annotation @RunOnVirtualThread an. Sie stammt aus SmallRye Common (io.smallrye.common.annotation.RunOnVirtualThread) und ist – Stand heute – kein Teil der Jakarta-EE-Spezifikation. Mit ihr legst du einen einzelnen Endpoint auf einen virtuellen Thread:
@GET
@Path("/product/{productId}")
@RunOnVirtualThread
public ProductPageResponse getProduct(@PathParam("productId") String productId) {
Product product = productService.getProduct(productId)
.orElseThrow(NotFoundException::new);
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}Code-Sprache: Java (java)Am Methodenkörper musst du nicht ein einziges Zeichen ändern. Quarkus unterstützt @RunOnVirtualThread bereits seit Version 2.10 – also seit Juni 2022.
In diesem GitHub-Repository findest du eine Beispiel-Quarkus-Anwendung mit dem oben gezeigten Controller – einmal mit Plattform-Threads, einmal mit virtuellen Threads und außerdem eine asynchrone Variante mit CompletableFuture. Die README erklärt, wie du die Anwendung startest und wie du die drei Controller aufrufst.
Wie verwendet man virtuelle Threads mit Spring?
In Spring würde der Controller wie folgt aussehen:
@GetMapping("/stage1-seq/product/{productId}")
public ProductPageResponse getProduct(@PathVariable("productId") String productId) {
Product product = productService
.getProduct(productId)
.orElseThrow(() -> new ResponseStatusException(NOT_FOUND));
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}Code-Sprache: Java (java)Seit Spring Boot 3.2 genügt eine einzige Property in der application.properties, um alle Request-Handler auf virtuellen Threads laufen zu lassen:
spring.threads.virtual.enabled=trueCode-Sprache: Properties (properties)Spring Boot konfiguriert daraufhin u. a. den Webserver (Tomcat/Jetty) und den Task-Executor so, dass jeder Request in einem eigenen virtuellen Thread bearbeitet wird.
Beachte: Damit laufen alle Controller auf virtuellen Threads. Für die meisten Anwendungsfälle ist das in Ordnung – nicht jedoch bei CPU-lastigen Aufgaben, die weiterhin auf Plattform-Threads laufen sollten.
In diesem GitHub-Repository findest du eine Beispiel-Spring-Anwendung mit dem oben gezeigten Controller. Die README erklärt, wie du die Anwendung startest und wie du den Controller von Plattform-Threads auf virtuelle Threads umschaltest.
Vorteile von virtuellen Threads
Virtuelle Threads bieten beeindruckende Vorteile:
Erstens, sie sind günstig:
- Sie können deutlich schneller erzeugt werden als Plattform-Threads: die Erzeugung eines Plattform-Threads dauert etwa 1 ms, die Erzeugung eines virtuellen Threads weniger als 1 µs.
- Sie benötigen weniger Speicher: ein Plattform-Thread reserviert 1 MB für den Stack und committet, je nach Betriebssystem, 32 bis 64 KB im Voraus. Ein virtueller Thread beginnt mit etwa einem KB. Das gilt jedoch nur für flache Call-Stacks. Ein Call-Stack von der Größe eines halben Megabytes benötigt dieses halbe Megabyte in beiden Thread-Varianten.
- Virtuelle Threads zu blockieren ist billig, da ein blockierter virtueller Thread keinen Betriebssystem-Thread blockiert. Umsonst ist es jedoch nicht, da der Stack des virtuellen Threads auf den Heap kopiert werden muss.
- Context Switches sind schnell, da sie im User Space, nicht im Kernel Space durchgeführt werden und in der JVM zahlreiche Optimierungen vorgenommen wurden, um sie schneller zu machen.
Zweitens, wir können virtuelle Threads auf vertraute Weise einsetzen:
- An den
Thread- undExecutorService-APIs wurden nur minimale Änderungen vorgenommen. - Anstatt asynchronen Code mit Callbacks zu schreiben, können wir Code im traditionellen blockierenden Thread-pro-Request-Stil schreiben.
- Wir können virtuelle Threads mit existierenden Tools debuggen, beobachten und profilen.
Was sind virtuelle Threads nicht?
Virtuelle Threads haben natürlich nicht nur Vorteile. Schauen wir uns zunächst einmal an, was virtuelle Threads nicht sind, bzw. was wir mit ihnen nicht machen können oder sollten:
- Virtuelle Threads sind keine schnelleren Threads – sie können nicht mehr CPU-Befehle als ein Plattform-Thread in derselben Zeit ausführen. Sofern ein Task nicht blockiert, läuft er auf einem virtuellen Thread aufgrund des Overheads des Mountens/Unmountens sogar langsamer als auf einem bestehenden Plattform-Thread aus einem
ExecutorService. - Sie sind nicht präemptiv: Während ein virtueller Thread eine CPU-intensive Aufgabe ausführt, wird er nicht vom Carrier-Thread genommen. Wenn du also 20 Carrier-Threads und 20 virtuelle Threads hast, die die CPU beanspruchen, ohne zu blockieren, wird kein anderer virtueller Thread ausgeführt.
- Sie bieten keine höhere Abstraktion als Plattform-Threads. Du musst dir all der subtilen Dinge bewusst sein, die du auch bei der Verwendung regulärer Threads beachten musst. Das heißt, wenn ein virtueller Thread auf gemeinsam genutzte Daten zugreift, musst du dich um Sichtbarkeitsprobleme kümmern, du musst atomare Operationen synchronisieren usw.
Welche Einschränkungen weisen virtuelle Threads auf?
Über folgende Einschränkungen solltest du Bescheid wissen. Das Bild hat sich seit der Einführung in Java 21 allerdings deutlich entspannt – einige frühere Einschränkungen sind inzwischen aufgehoben.
1. Nicht unterstützte blockierende Operationen
Die überwiegende Mehrheit der blockierenden Operationen im JDK wurde so umgeschrieben, dass sie virtuelle Threads unterstützt. Eine relevante Ausnahme bleibt (Stand Java 26):
- File I/O
Hier blockiert ein blockierter virtueller Thread auch den Träger-Thread. Um das zu kompensieren, erhöht die JVM vorübergehend die Anzahl der Träger-Threads – bis zu einem Maximum von 256, das über die VM-Option jdk.virtualThreadScheduler.maxPoolSize angepasst werden kann. An einer Lösung (u. a. auf Basis von io_uring) wird gearbeitet.
2. Pinning
Pinning bedeutet, dass eine blockierende Operation, die normalerweise einen virtuellen Thread vom Träger-Thread nehmen würde, dies nicht tut, weil der virtuelle Thread an seinen Träger-Thread „gepinnt“ wurde – was bedeutet, dass er den Träger-Thread nicht wechseln darf.
Stand Java 26 tritt Pinning nur noch dann auf, wenn der Call-Stack Aufrufe nativen Codes enthält – denn was innerhalb von nativem Code passiert, können wir nicht kontrollieren. Innerhalb eines synchronized-Blocks pinnt ein virtueller Thread dagegen nicht mehr.
Erkennen von Pinning
Verbleibendes Pinning (z. B. durch nativen Code) erkennst du über das JDK-Flight-Recorder-Event jdk.VirtualThreadPinned, etwa in einer JFR-Aufzeichnung. Das Event wird aufgezeichnet, wenn ein virtueller Thread blockiert, während er gepinnt ist.
3. Keine Deadlock-Erkennung in Thread Dumps
Seit Java 25 enthalten die neuen Thread-Dumps (per jcmd <pid> Thread.dump_to_file, siehe nächster Abschnitt) auch Informationen über Locks, die von virtuellen Threads gehalten werden oder durch die sie blockiert werden – etwa den Objekt-Monitor, auf den ein Thread beim Eintritt wartet.
Was diese Thread-Dumps weiterhin nicht anzeigen, sind Deadlocks zwischen virtuellen Threads oder zwischen einem virtuellen und einem Plattform-Thread. Eine automatische Deadlock-Erkennung wie bei klassischen Thread-Dumps gibt es hier nicht – Deadlocks musst du anhand der Lock-Informationen selbst aufspüren.
Thread Dumps mit virtuellen Threads
Die herkömmlichen Thread-Dumps, die per jcmd <pid> Thread.print ausgegeben werden, enthalten übrigens keine virtuellen Threads. Der Grund dafür ist, dass dieses Kommando die VM anhält, um einen Snapshot der laufenden Threads zu erstellen. Dies ist für einige hundert oder sogar einige tausend Threads machbar, aber nicht für Millionen von ihnen.
Daher wurde eine neue Variante von Thread-Dumps implementiert, bei der die VM nicht angehalten wird (entsprechend ist der Thread-Dump ggf. nicht in sich konsistent), die dafür aber virtuelle Threads mit einschließt. Dieser neue Thread-Dump kann mit einem der beiden folgenden Kommandos erzeugt werden:
jcmd <pid> Thread.dump_to_file -format=plain <file>jcmd <pid> Thread.dump_to_file -format=json <file>
Das erste Kommando generiert einen Thread-Dump ähnlich des bisherigen, mit Thread-Namen, -IDs und Stack-Traces. Das zweite Kommando generiert eine Datei im JSON-Format, die darüber hinaus Informationen über Thread-Container, Eltern-Container und Eigentümer-Threads enthält.
Wann sollten virtuelle Threads eingesetzt werden?
Virtuelle Threads solltest du einsetzen bei vielen nebenläufig abzuarbeitenden Tasks, die in erster Linie blockierende Operationen enthalten.
Dies gilt für die meisten Serveranwendungen. Wenn deine Serveranwendung allerdings CPU-intensive Aufgaben bearbeitet, solltest du dafür Plattform-Threads verwenden.
Was gilt es sonst noch zu beachten?
Hier ein paar Tipps zum Einsatz von und zum Umstieg auf virtuelle Threads:
- Auch wenn viele Artikel über virtuelle Threads uns das glauben machen wollen: sie verwenden nicht grundsätzlich weniger Speicher als ein Plattform-Thread. Dies ist nur dann der Fall, wenn der Call-Stack nicht sehr tief ist. Bei tiefen Call-Stacks verbrauchen beide Arten von Threads die gleiche Menge an Speicher.
- Virtuelle Threads müssen nicht gepoolt werden. Ein Pool wird verwendet, um teure Ressourcen zu teilen. Virtuelle Threads sind hingegen so billig, dass es besser ist, einen zu erstellen, wenn man ihn braucht, und ihn terminieren zu lassen, wenn man ihn nicht mehr braucht.
- Wenn du den Zugriff auf eine Ressource begrenzen musst, z. B. wie viele Threads gleichzeitig auf eine Datenbank oder eine API zugreifen dürfen, verwende statt einem Thread-Pool einen Semaphor.
- Ein Großteil des Codes für virtuelle Threads ist in Java geschrieben. Dementsprechend musst du die JVM aufwärmen, bevor du Performance-Tests durchführst, damit der gesamte Bytecode kompiliert und optimiert ist, bevor die Messung beginnt.
Fazit
Virtuelle Threads halten, was sie versprechen: Sie ermöglichen es uns lesbaren und wartbaren, sequentiellen Code zu schreiben, der Betriebssystem-Threads nicht blockiert, wenn auf Locks, blockierende Datenstrukturen oder Antworten vom Dateisystem oder externen Services gewartet werden muss.
Virtuelle Threads können in der Größenordnung von mehreren Millionen erzeugt werden.
Die gängigen Backend-Frameworks wie Spring und Quarkus können bereits mit virtuellen Threads umgehen. Dennoch solltest du Anwendungen intensiv testen, wenn du sie auf virtuelle Threads umstellst. Beachte, dass du auf ihnen keine CPU-intensiven Rechenaufgaben ausführst, dass sie nicht durch das Framework gepoolt werden und dass in ihnen keine ThreadLocals gespeichert werden (s. auch Scoped Values).
Ich hoffe, du bist ebenso begeistert wie ich und kannst es nicht abwarten virtuelle Threads in deinen Projekten einzusetzen!
Wenn du noch Fragen hast, stelle sie gerne über die Kommentar-Funktion.