


Hexagonale Architektur – Was ist das? Was sind ihre Vorteile?
In diesem Artikel erfährst du:
- Was ist hexagonale Architektur (bzw. „Ports & Adapters“, wie diese Architektur offiziell heißt)?
- Was sind die Vorteile der hexagonalen Architektur gegenüber der klassischen Schichtenarchitektur?
- Was unterscheidet die hexagonale Architektur von „Clean Architecture“ und „Onion Architecture“?
- Wie stehen hexagonale Architektur, Microservices und Domain Driven Design im Zusammenhang?
Wie man eine hexagonale Software-Architektur mit Java implementiert – einmal ohne Application Framework, einmal mit Quarkus und einmal mit Spring Boot – und wie man sicherstellt, dass die Architekturgrenzen nicht verletzt werden, zeige ich dir in vier weiteren Teilen dieser Artikelserie.
Bevor ich auf die Details der hexagonalen Architektur eingehe, erkläre ich kurz den Zweck einer Softwarearchitektur und warum das am weitesten verbreitete Architekturmuster, die Schichtenarchitektur, nicht für größere Projekte geeignet ist.
Was ist das Ziel einer Softwarearchitektur?
Unter Architektur verstehen wir die Aufteilung eines Systems in Komponenten, die Anordnung und Eigenschaften dieser Komponenten und die Art und Weise, wie diese Komponenten miteinander kommunizieren.
Laut Robert C. Martins Buch „Clean Architecture“ erlaubt eine gute Architektur, Software während ihrer Lebensdauer mit möglichst geringem, gleichbleibendem Aufwand (und entsprechend planbaren Kosten für den Auftraggeber) zu ändern.
Änderungen könnten sein:
- Umsetzung von Kundenwünschen;
- Anpassungen an geänderte gesetzliche Vorgaben;
- Einsatz modernerer Technologien (z. B. Austausch einer SOAP-API durch eine REST-API);
- Upgrade von Infrastruktur-Komponenten (z. B. Upgrade des Datenbank-Servers oder der ORM-Library auf eine neue Version);
- Austausch von Drittsystemen (z. B. des externen Billing- oder Newsletter-Versandsystems);
- und sogar ein Austausch des Application Servers (z. B. Quarkus statt Glassfish).
Wie entwickelt man eine gute Software-Architektur?
Um eine Software „soft“ zu halten, sollte die Anwendung in gut isolierte, unabhängig voneinander entwickelbare und testbare Komponenten aufgeteilt werden (ein automatisiertes Deployment gehört auch dazu, ist aber nicht Thema dieses Artikels).
In den meisten Geschäftsanwendungen wird versucht, dieses Ziel durch die klassische Schichtenarchitektur zu erreichen:
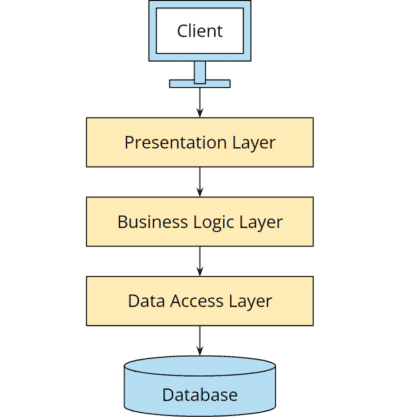
Die Praxis hat allerdings gezeigt, dass die Schichtenarchitektur für große Projekte nicht gut geeignet ist. Warum das so ist, erfährst du im nächsten Abschnitt.
Nachteile der Schichtenarchitektur
Die Schichtenarchitektur führt zu einer unnötigen Kopplung mit negativen Folgen:
Die Geschäftslogik hat eine direkte Abhängigkeit zur Datenbank, die Präsentationsschicht hat eine transitive Abhängigkeit. So sind beispielsweise alle Entities, Repositories und ORM-Libraries (wie z. B. Hibernate oder EclipseLink in der Java-Welt) auch in der Präsentationsschicht verfügbar. Dies verführt Entwickler – vor allem wenn sie unter Zeitdruck stehen – dazu, die Grenzen zwischen den Schichten aufweichen zu lassen.
Nicht selten kommt es zu Fehlern, weil z. B. in der Präsentationsschicht versucht wird, über eine nicht initialisierte One-To-Many-Collection einer JPA-Entity zu iterieren. Und so müssen wir uns im Business Layer – der eigentlich fachlichen Schicht – Gedanken über technische Belange wie Transaktionen, Lazy und Eager Loading machen.
Die Kopplung macht es zudem unnötig schwer, die Datenbank oder die Datenzugriffsschicht zu aktualisieren (z. B. auf eine neue Datenbank-Version oder eine neue Version des O/R-Mappers). Ich habe zahlreiche Geschäftsanwendungen gesehen, die mit veralteten (d. h. fehlerhaften und/oder unsicheren) Hibernate- oder EclipseLink-Versionen arbeiten, weil ein Update Anpassungen in allen Schichten der Anwendung erfordern würde und durch das Management herunterpriorisiert wurde.
Das betrifft übrigens nicht nur die Datenbank, sondern jegliche Art von Infrastruktur, auf die die Anwendung zugreift. So sind mir auch schon Zugriffe auf die Facebook Graph API aus der Präsentationsschicht begegnet.
Die Aufweichung der Schichtengrenzen macht darüberhinaus das isolierte Testen einzelner Komponenten – z. B. der Geschäftslogik ohne User Interface und Datenbank – unmöglich.
Was ist Hexagonale Architektur?
Die hexagonale Software-Architektur wurde 2005 von Alistair Cockburn in einem Blogartikel vorgestellt. Cockburn nennt folgende Ziele:
- Die Anwendung soll gleichermaßen von Benutzern, anderen Anwendungen oder automatisierten Tests gesteuert werden können. Für die Geschäftslogik macht es keinen Unterschied, ob sie von einem User Interface, einer REST-API oder einem Test-Framework aufgerufen wird.
- Die Geschäftslogik soll isoliert von der Datenbank, von sonstiger Infrastruktur und von Drittsystemen entwickelt und getestet werden können. Aus Sicht der Geschäftslogik macht es keinen Unterschied, ob Daten in einer relationalen Datenbank, einem NoSQL-System, in XML-Dateien oder in einem proprietären Binärformat gespeichert werden.
- Die Modernisierung von Infrastruktur (z. B. Aktualisierung des Datenbankservers, Anpassung an geänderte externe Schnittstellen, Aktualisierung unsicherer Libraries) soll ohne Anpassungen an der Geschäftslogik möglich sein.
Wie die hexagonale Architektur diese Ziele erreicht, erfährst du im nächsten Abschnitt.
Ports und Adapter
Erreicht wird die Isolierung von Geschäftslogik (in der hexagonalen Architektur mit „Application“ bezeichnet) zur Außenwelt über sogenannte „Ports“ und „Adapter“, wie in der folgenden Grafik dargestellt:
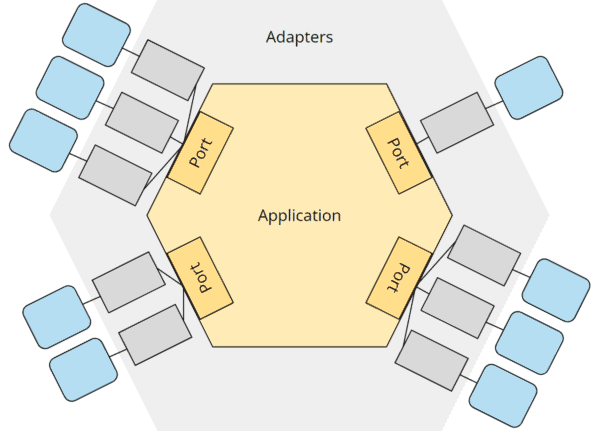
Die Geschäftslogik („Application“) befindet sich im Kern der Architektur und definiert Schnittstellen („Ports“), um mit der Außenwelt zu kommunizieren – und zwar sowohl um gesteuert zu werden (durch eine API, durch ein User Interface, durch andere Anwendungen) als auch um zu steuern (die Datenbank, externe Schnitstellen, sonstige Infrastruktur).
Die Geschäftslogik kennt ausschließlich diese Ports; all ihre Use Cases sind ausschließlich gegen die Spezifikationen der Ports implementiert. Für die Geschäftslogik ist es irrelevant, welche technischen Details sich möglicherweise hinter diesen Ports befinden.
Die folgende Abbildung zeigt eine beispielhafte Anwendung, die
- durch einen User über ein User Interface gesteuert wird,
- durch einen User über eine REST-API gesteuert wird,
- durch eine externe Anwendung über dieselbe REST-API gesteuert wird,
- eine Datenbank ansteuert und
- eine externe Anwendung ansteuert.
(Die Nummerierung steht nicht für eine Reihenfolge, sondern referenziert die Pfeile in der Abbildung.)
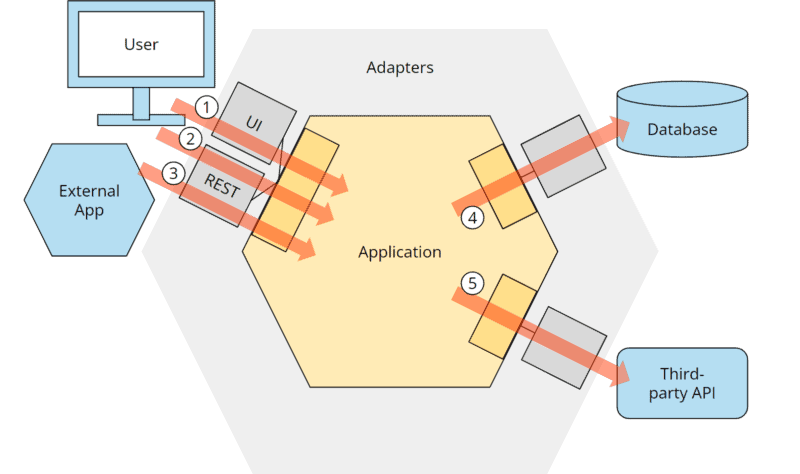
Die Anbindung der externen Komponenten wird durch „Adapter“ realisiert.
So könnte z. B. das User Interface ein Registrierungsformular bereitstellen. Wenn der User alle Daten ausgefüllt hat und auf „Registrieren“ klickt, generiert der UI-Adapter daraus ein „Registriere User“-Kommando und schickt dieses an die Geschäftslogik. Das gleiche Kommando könnte aber auch durch den REST-Adapter für einen entsprechenden HTTP-POST-Request generiert werden:
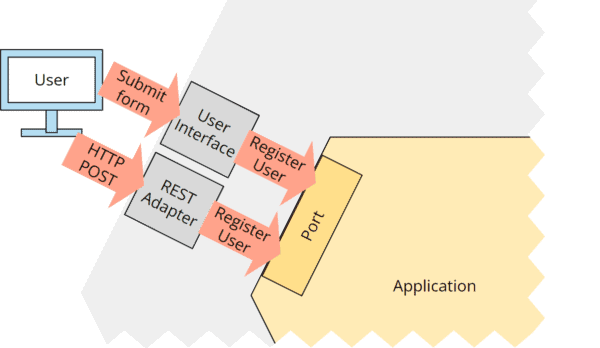
Auf der „anderen Seite“ der Anwendung könnte der Datenbank-Adapter das Kommando „Speichere Benutzer“ in eine „INSERT INTO User VALUES (...)“-SQL-Query übersetzen:
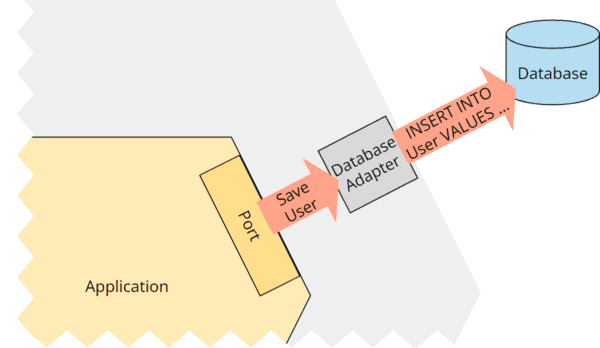
Wie genau der Adapter das bewerkstelligt – ob er dazu einen O/R-Mapper einsetzt und welchen und in welcher Version – spielt aus Sicht des Anwendungskerns keine Rolle.
An einen Port können mehrere Adapter angeschlossen werden. So kann – wie im Beispiel oben – an den Port für die Steuerung der Anwendung ein User-Interface-Adapter und ein REST-Adapter angeschlossen sein. Und an einen Port zum Versand von Notifications könnte ein E-Mail-Adapter, ein SMS-Adapter und ein WhatsApp-Adapter angeschlossen sein.
Der Begriff „Port“ ist übrigens eine Anspielung auf elektrische Anschlüsse (englisch: „ports“), an die jedes Gerät angeschlossen werden kann, das den mechanischen und elektrischen Protokollen des Anschlusses entspricht.
Primäre und sekundäre Ports und Adapter
Am Beispiel oben haben wir bereits gesehen, dass es zwei Arten von Ports und Adaptern gibt. Solche, die die Anwendung steuern und solche, die von der Anwendung gesteuert werden.
Die erste Gruppe nennen wir „primäre“ oder „treibende“ (englisch: „primary“, „driving“) Ports und Adapter; diese werden in der Regel auf der linken Seite des Hexagons dargestellt.
Die zweite Gruppe bezeichnen wir als „sekundäre“ oder „getriebene“ (englisch: „secondary“, „driven“) Ports und Adapter; sie werden normalerweise rechts dargestellt.
Dependency Rule
In der Theorie hört sich das soweit ganz gut an. Doch wie erreichen wir programmatisch, dass keine technischen Details (wie JPA-Entities) und Libraries (wie O/R-Mapper) zur Anwendung durchsickern?
Die Antwort findet sich in der sogenannten „Dependency Rule“ (deutsch: Abhängigkeitsregel). Diese besagt, dass alle Quellcode-Abhängkeiten ausschließlich von außen nach innen, also in Richtung des Application Hexagons zeigen dürfen:
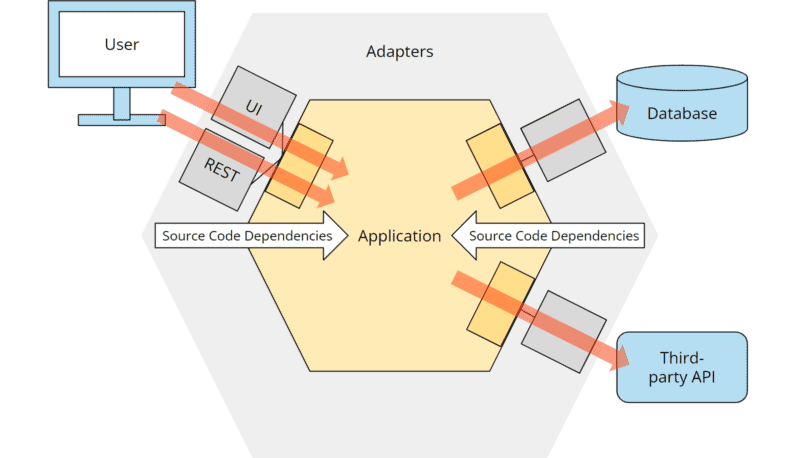
Die Umsetzung in Klassen und ihre Beziehungen zueinander gestaltet sich für primäre Ports und Adapter (also die linke Seite der Grafik) recht simpel.
Um beim Beispiel der Benutzerregistrierung zu bleiben, könnten wir die gewünschte Architektur etwa mit folgenden Klassen realisieren:
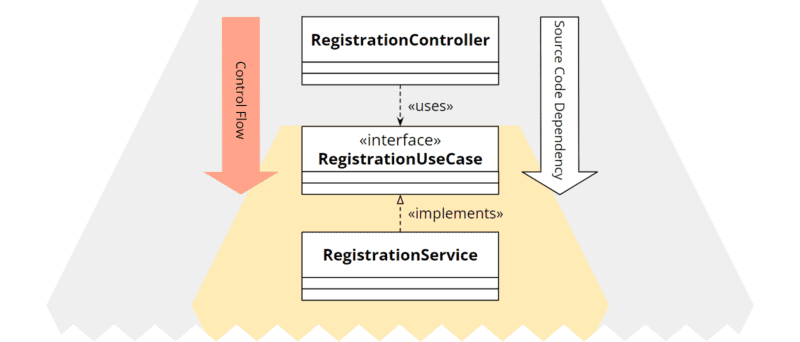
Der RegistrationController ist der Adapter. Der primäre Port wird durch das Interface RegistrationUseCase definiert. Die durch den Port beschriebene Funktionalität wird durch den RegistrationService implementiert. (Diese Namenskonvention habe ich dem großartigen Buch „Get Your Hands Dirty on Clean Architecture“ von Tom Hombergs entnommen.)
Die Quellcode-Abhängigkeit führt von RegistrationController zu RegistrationUseCase, also, wie gefordert, in Richtung Kern.
Doch wie implementieren wir die sekundären Ports und Adapter, also die rechte Seite der Grafik, auf der die Quellcode-Abhängigkeit entgegengesetzt zur Aufrufrichtung sein muss? Wie kann der Kern der Anwendung beispielsweise auf die Datenbank zugreifen, wenn sich die Datenbank außerhalb des Kerns befindet und die Quellcode-Abhängkeit zum Kern gerichtet sein soll?
Hier kommt das Dependency Inversion Principle, also eine Umkehrung der Abhängigkeit, ins Spiel.
Dependency Inversion
Der Port wird auch hier durch ein Interface definiert. Allerdings sind die Beziehungen zwischen den Klassen ausgetauscht: Der PersistanceAdapter benutzt den PersistencePort nicht, sondern implementiert ihn. Und der RegistrationService implementiert den PersistencePort nicht, sondern benutzt ihn:

Mittels Dependency Inversion Principle können wir also die Richtung einer Code-Abhängigkeit wählen – für sekundäre Ports und Adapter also entgegengesetzt zur Aufrufrichtung.
Mapping
Die Isolierung der technischen Details vom Anwendungskern führt zu einem Dilemma, das sich z. B. beim Einsatz eines O/R-Mappers bemerkbar macht. Entity-Klassen werden in der Regel mit Annotationen versehen, die den Mapper instruieren, auf welche Datenbanktabelle und Spalten die Entity und ihre Properties gemappt werden sollen, wie der Primärschlüssel zu generieren ist und wie Collections auf Relationen abzubilden sind.
Da der Anwendungskern die technischen Details des Persistenz-Adapters nicht kennen soll, kann solch eine Entity im Anwendungskern nicht mit diesen technischen Annotationen versehen werden:
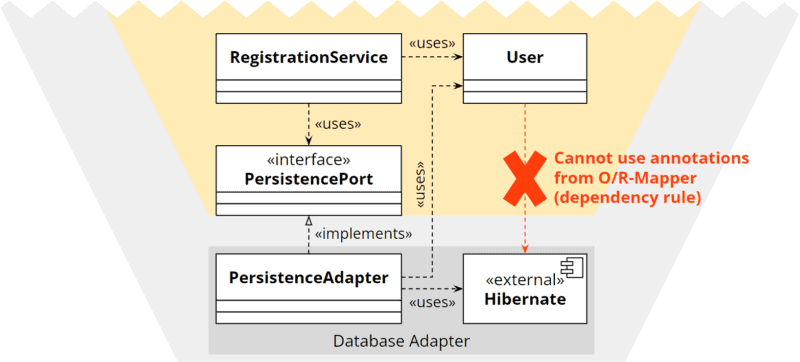
Andererseits kann die Entity nicht im Adapter implementiert werden, da dann der Anwendungskern keinen Zugriff mehr auf sie haben würde:
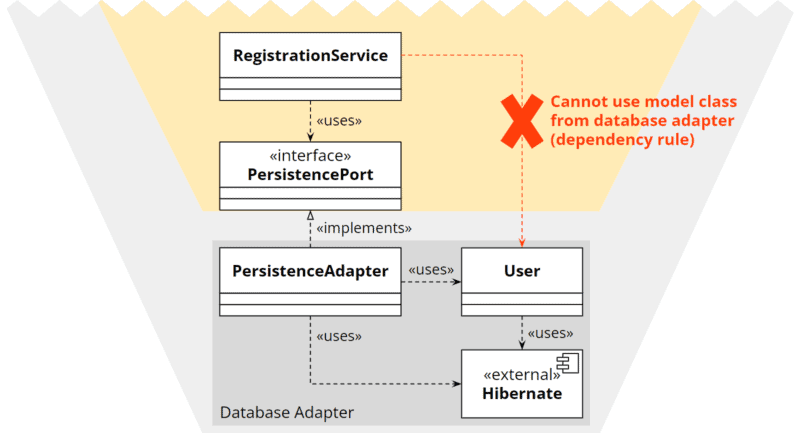
Wie löst man dieses Dilemma auf?
In den nächsten Abschnitten stelle ich dir verschiedene Strategien dafür vor.
Duplikation mit Zwei-Wege-Mapping
Wir legen eine zusätzliche Modellklasse im Adapter an, die keinerlei Geschäftslogik enthält, dafür aber die technischen Annotationen. Der Adapter muss dann die Modellklasse des Kerns auf die eigene Modellklasse mappen und umgekehrt.
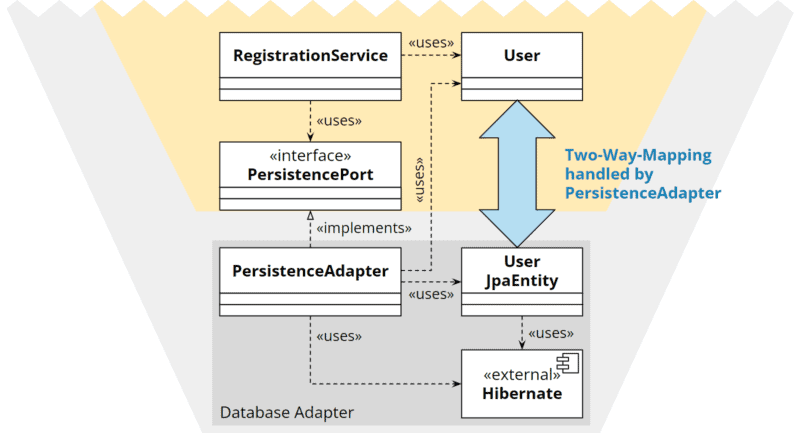
Nach meiner Erfahrung ist diese Variante die am besten geeignete.
Duplikation mit Ein-Weg-Mapping
Wir definieren im Kern ein Interface, welches sowohl von der Modellklasse im Kern als auch von der Modellklasse im Adapter implementiert wird. So muss nur das vom Kern kommende Modell in das Adapter-Modell übersetzt werden. Eine Übersetzung Richtung Kern ist nicht nötig: Der Adapter kann dem Kern seine eigene Modellklasse schicken, da diese das im Kern definierte Interface implementiert.
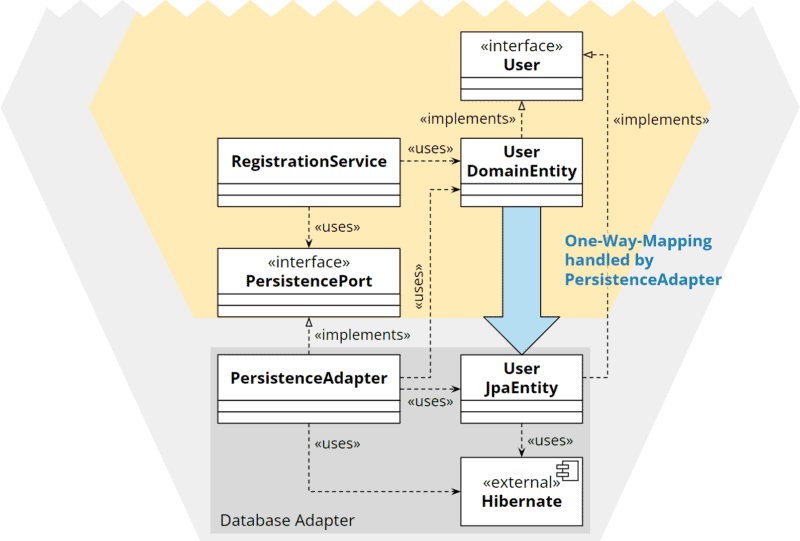
Diese Variante erfordert, dass das Interface nur die Zugriffsmethoden für diejenigen Felder definiert, die persistiert werden sollen. Geschäftslogik-Methoden dürfen im Interface nicht definiert werden. Mir gefällt diese Strategie nicht, da sie weniger intuitiv ist und nach meiner Erfahrung mehr Aufwand darstellt und schlechter wartbar ist als das Zwei-Wege-Mapping.
Technische Instruktionen außerhalb des Programmcodes
Manche Libraries, wie z. B. Hibernate, erlauben es, die technischen Instruktionen in einer XML-Datei zu definieren anstatt mit Annotationen in der Modellklasse. So kann der Adapter die Modellklasse des Kerns verwenden ohne Code duplizieren zu müssen.
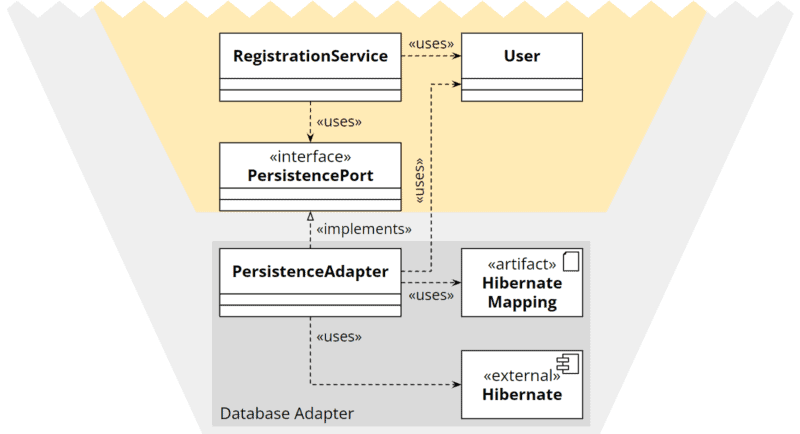
Externe Instruktionen sind allerdings oft deutlich unübersichtlicher als Annotationen im Code, so dass ich auch diese Strategie nicht gerne einsetze.
Aufweichung der Architekturgrenzen
Letztendlich kann man auch die bewusste Entscheidung treffen, die strengen Architekturgrenzen aufzuweichen, eine Abhängigkeit vom Kern zur ORM-Library zuzulassen und die Annotationen direkt an die Entity im Kern setzen.
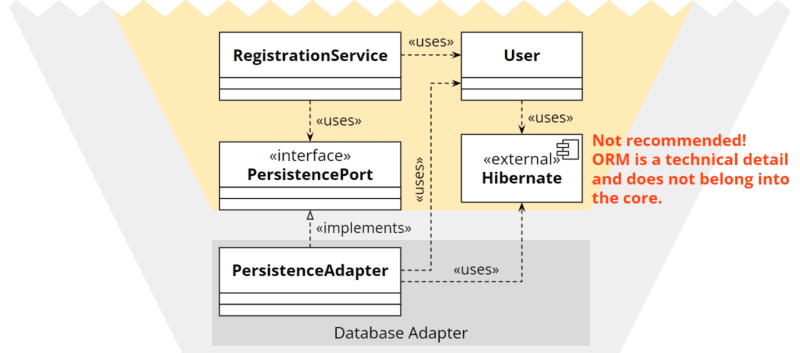
Von dieser Option würde ich immer abraten. Fängt man einmal damit an, dauert es gemäß der Broken-Windows-Theorie nicht lange, bis die nächste Architekturvorschrift aufgeweicht wird.
Mapping im REST-Adapter
Mapping ist nicht nur beim Datenbankadapter ein Thema, sondern z. B. auch bei einem REST-Adapter. Oft wollen wir nicht alle Attribute einer Entity über die Schnittstelle sichtbar machen (z. B. Primärschlüssel oder Erstellungs- und Änderungsdatum) und für manche Attribute müssen wir definieren, wie diese formatiert werden (z. B. Datums- und Zeitangaben).
Auch das können wir mit technischen Annotationen steuern (z. B. @JsonIgnore oder @JsonFormat beim Einsatz von Jackson). Aber auch diese wollen wir nicht im Anwendungskern haben. Daher ist es auch bei REST-Adaptern in der Regel sinnvoll, eine Entity auf eine Adapter-spezifische Modellklasse zu mappen, die nur die sichtbaren Felder sowie die Formatierungs-Instruktionen enthält.
Tests
Ich habe zu Beginn des Artikels als eine der Anforderungen an eine gute Softwarearchitektur „isoliert testbaren Komponenten“ genannt. Tatsächlich macht es uns die hexagonale Architektur sehr einfach (wie auch in den folgenden Teilen dieser Artikelserie in der Praxis zu sehen sein wird), die Geschäftslogik der Anwendung zu testen:
- Tests können die Geschäftslogik über die primären Ports aufrufen.
- Die sekundären Ports können wir mit Test Doubles verbinden, z. B. in Form von Stubs, um Abfragen der Anwendung zu beantworten, oder Spies, um von der Anwendung gesendete Ereignisse aufzuzeichnen.
Die folgende Grafik zeigt einen Unit Test, der ein Test Double für die Datenbank erzeugt und mit dem sekundären Datenbank-Port verbindet („Arrange“), einen Use-Case am primären Port aufruft („Act“) und die Antwort des Ports sowie die Interaktion mit dem Test Double verifiziert („Assert“):
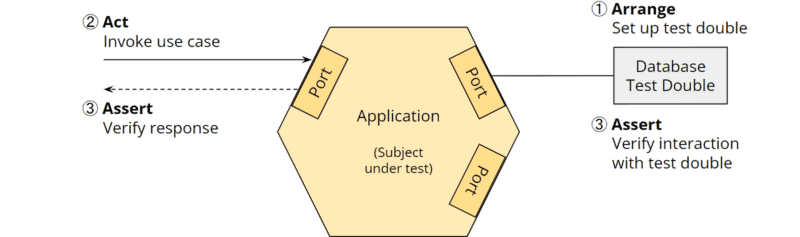
Nicht nur die Geschäftslogik kann isoliert von den Adaptern getestet werden, sondern auch die Adapter isoliert von der Geschäftslogik (z. B. im Java-Ökosystem primäre REST-Adapter mit REST Assured, sekundäre REST-Adapter mit WireMock und Datenbank-Adapter mit TestContainers).
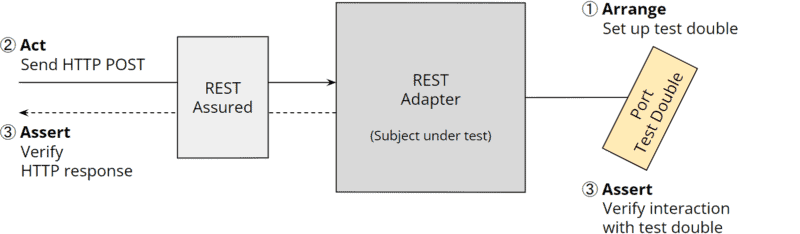
Die folgende Grafik zeigt einen Integrationstest, der ein Test Double für den primären Port erzeugt („Arrange“), per REST Assured einen HTTP-POST-Request an den REST-Adapter sendet („Act“) und schließlich die HTTP-Antwort sowie die Interaktion mit dem Test Double verifiziert („Assert“):
Die letzte Grafik zeigt einen Integrationstest für den Datenbank-Adapter, der per TestContainers eine Test-Datenbank hochfährt („Arrange“), eine Methode auf dem Datenbank-Adapter aufruft („Act“) und schließlich prüft, ob der Rückgabewert der Methode und ggf. die Änderungen in der Test-Datenbank den Erwartungen entsprechen („Assert“):
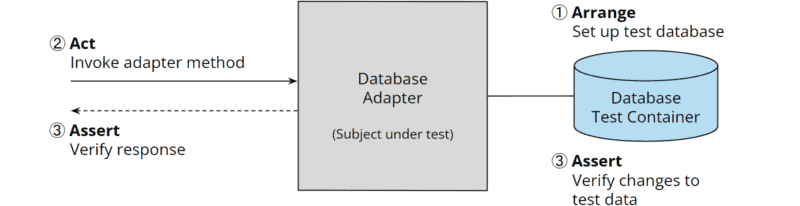
Neben diesen isolierten Tests dürfen natürlich auch vollständige Systemtests nicht fehlen (in geringerem Umfang gemäß der Testpyramide).
Warum ein Hexagon?
Alistair Cockburn wird immer wieder gefragt, ob das Hexagon oder die Zahl „sechs“ eine bestimmte Bedeutung habe. Seine Anwort auf diese Frage ist: „Nein“. Er wollte eine Form verwenden, die noch keiner verwendet hat. Vierecke werden überall verwendet, und Fünfecke sind schwer zu zeichnen. Also wurde es ein Sechseck.
Das Sechseck ist außerdem hervorragend geeignet, um links zwei primäre Ports und rechts zwei sekundäre Ports einzuzeichnen. Cockburn sagt, ihm sei noch nie ein Projekt begegnet, für dessen schematische Darstellung mehr als vier Ports nötig waren.
Vorteile der Hexagonalen Architektur
Nachdem wir die hexagonale Architektur von allen Seiten betrachtet haben, ist es an der Zeit sich die Ziele einer guten Softwarearchitektur in Erinnerung zu rufen und zu überprüfen, inwieweit die hexagonale Architektur diese Ziele erfüllt.
Software soll leicht änderbar sein und dies während ihrer gesamten Lebensdauer bleiben. Dazu sollte sie in voneinander isolierte, unabhängig entwickelbare und testbare Komponenten strukturiert sein.
Gehen wir die Kriterien im einzelnen durch...
Änderbarkeit
- Wir können die Geschäftslogik im Anwendungskern ändern, ohne die Adapter oder die Infrastruktur ändern zu müssen (wobei in der Praxis eine Änderung der Geschäftslogik oft mit Änderungen am User Interface und der Datenspeicherung einhergeht).
- Wir können die Infrastruktur (z. B. die Datenbank oder den O/R-Mapper) aktualisieren und austauschen, ohne auch nur eine Zeile Code in der Geschäftslogik ändern zu müssen. Wir müssen ausschließlich den entsprechenden Adapter anpassen.
- Indem wir mit der Entwicklung des Anwendungskerns beginnen, können wir Entscheidungen über die Infrastruktur hinauszögern und sehr spät im Entwicklungsprozess treffen. Die bei der Entwicklung des Kerns gesammelte Erfahrung erlaubt es uns, bessere Entscheidungen über die einzusetzende Infrastruktur (Application Framework, Datenbanksystem, etc.) zu treffen.
Isolierung
- In der Anwendungskern werden ausschließlich fachliche Themen behandelt.
- Alle technischen Belange sind in den primären und sekundären Adaptern implementiert.
- Anwendungskern und Adapter sind durch Ports isoliert – die Use Cases im Anwendungskern interagieren ausschließlich mit diesen Ports, ohne die technischen Details dahinter zu kennen.
- Die Isolierung erlaubt es, alle Verantwortlichkeiten im Code klar zu lokalisieren, was das Risiko der Aufweichung der Architekturgrenzen erheblich verringert.
Entwicklung
- Sobald die Ports der Anwendung definiert sind, kann die Arbeit an den Komponenten (Kern, User Interface, Datenbankanbindung, etc.) leicht auf mehrere Entwickler, Pairs oder Teams aufgeteilt werden.
Testbarkeit
- Wie oben im Detail gezeigt, können alle Komponenten durch Einsatz von Test Doubles vollständig isoliert getestet werden.
Die hexagonale Architektur erfüllt damit alle Kriterien einer guten Softwarearchitektur. Das hört sich fast zu gut an, um wahr zu sein. Hat das hexagonale Architekturmodell denn keine Nachteile?
Nachteile der Hexagonalen Architektur
Das Implementieren der Ports und Adapter und die Umsetzung der gewählten Mapping-Strategie stellt einen nicht zu vernachlässigen Mehraufwand dar. Dieser amortisiert sich für große Enterprise-Applikationen schnell; für kleinere Anwendungen, z. B. einen einfachen CRUD-Microservice mit minimaler Geschäftslogik lohnt sich der Mehraufwand eher nicht.
Im besten Fall habt ihr einen seniorigen Entwickler/Architekten im Team, der bereits Erfahrung mit der hexagonalen Architektur hat und der beurteilen kann, ob sich der initiale Mehraufwand für euer Projekt lohnt.
Ich empfehle dir, die Beispiel-Anwendung, an der ich in den weiteren Teile dieser Tutorial-Serie die Implementierung der hexagonalen Architektur demonstrieren werde, nachzuprogrammieren. So sammelst du erste Erfahrungen und wirst vielleicht selbst dieser erfahrene Entwickler, der die hexagonale Architektur für euer nächstes Projekt ins Spiel bringt.
Hexagonale Architektur und DDD (Domain Driven Design)
In der Literatur findet man immer wieder Darstellungen der hexagonalen Architektur mit „Entities“ und „Use Cases“ oder „Services“ innerhalb des Application Hexagons und/oder mit einem „Domain“- oder „Domain Model“-Hexagon innerhalb des Application Hexagons – in etwa wie in der folgenden Abbildung:
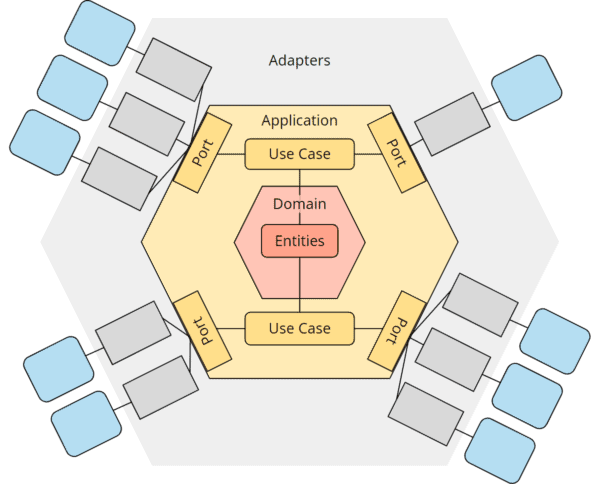
Tatsächlich lässt die hexagonale Architektur aber bewusst offen, was sich innerhalb des Application Hexagons befindet. Alistair Cockburn antwortete in einem sehr sehenswerten Interview auf die Frage „What do you see inside the Application?“ mit „I don’t care – not my business“. Das hexagonale Entwurfsmuster stehe für eine Design-Entscheidung: „Wrap your app in an API and put tests around it“.
Nichtsdestotrotz ergänzen sich Domain Driven Design (DDD) und hexagonale Architektur ausgesprochen gut, denn der DDD-Teilbereich des taktischen Designs eignet sich hervorragend, um die Geschäftsregeln innerhalb des Anwendungshexagons zu strukturieren.
Ich werde daher in den folgenden Artikeln dieser Serie, in denen ich die Implementierung einer hexagonalen Architektur mit Java demonstrieren werde, ebenfalls dieses zusätzliche Domain-Hexagon einsetzen.
Hexagonale Architekture und Microservices
Die hexagonale Architektur eignet sich auch für die Implementierung von Microservices, sofern diese zwei Kriterien erfüllen:
- Sie müssen Gechäftslogik enthalten und nicht rein technischer Natur sein. Ein Microservice, der z. B. alle Events, die er auf einem Event-Bus abhört, in ein anderes System loggt, hat einen rein technischen Zweck. Hier gibt es keine Geschäftslogik, die von den technischen Details isoliert werden könnte.
- Sie müssen eine gewisse Größe haben. Für einen Microservice mit minimaler Geschäftslogik lohnt sich der Mehraufwand für Ports, Adapter und Mapping nicht. Eine feste Größengrenze gibt es nicht, hier muss eine Entscheidung aus Erfahrung heraus getroffen werden. Wenn nach Domain Driven Design gearbeitet wird und ein Microservice ein Aggregate mit mehreren Entities und die zugehörigen Services umfasst, ist der Einsatz der hexaginalen Architektur in der Regel sinnvoll.
Aus Sicht eines Microservices sind alle anderen Microservices Teile der Außernwelt und werden – genau wie die restliche Infrastruktur – über Ports und Adapter isoliert:
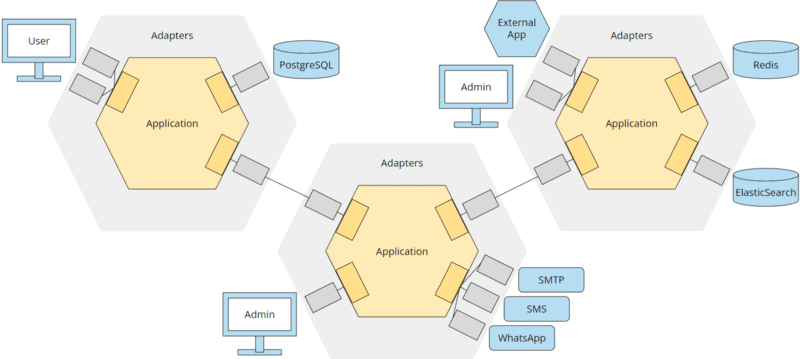
Meine Heransgehensweise für die Planung einer komplexen Geschäftsanwendung ist in der Regel eine Kombination aus Domain Driven Design, Microservices und hexagonaler Architektur:
- Einsatz von Strategic Design zur Planung von Core Domain, Sub Domains und Bounded Contexts.
- Aufteilung eines Bounded Contexts in einen oder mehrere Microservices. Ein Microservice kann ein oder mehrere Aggregates enthalten, aber auch den kompletten Bounded Context, sofern dieser nicht zu groß ist (und statt des gewünschten Microservices wieder ein Monolith entsteht).
- Implementierung des Application Hexagons nach Tactical Design, also mit Entities, Value Objects, Aggregates, Services, etc.
Hexagonale Architektur vs. „Ports & Adapters“
Hexagonale Architektur und „Ports and Adapters“ (manchmal auch „Ports & Adapters“) bezeichnen dieselbe Architektur. Der offizielle Name, den Alistair Cockburn dem in diesem Artikel beschriebenen Architekturmuster gegeben hat, ist „Ports and Adapters“.
Die gebräuchlichere, bildliche Bezeichnung „Hexagonale Architektur“ ergab sich aus der grafischen Darstellung der Architektur mit Sechsecken. Alistair Cockburn hat im oben erwähnten Interview verraten, dass auch er den figurativen Namen vorzieht – dass der offizielle Name eines Musters aber einer sein muss, der dessen Eigenschaften beschreibt.
Hexagonale Architektur vs. Schichtenarchitektur
Bereits zu Beginn des Artikels habe ich die weit verbreitete Schichtenarchitektur und deren Nachteile angesprochen (transitive Abhängigkeiten zur Datenbank, verschwimmende Schichtengrenzen, mangelhafte Isolierung der Komponenten, schlechte Testbarkeit, schlechte Aktualisierbarkeit und Austauschbarkeit von Infrastrukturkomponenten).
Im folgenden siehst du die beiden Architekturmuster gegenübergestellt. Im Gegensatz zur hexagonalen Architektur (hier in ihrer ursprünglichen Darstellung von Alistair Cockburn ohne explizite Ports) steht bei der Schichtenarchitektur nicht die Geschäftslogik im Zentrum, sondern die Datenbank:
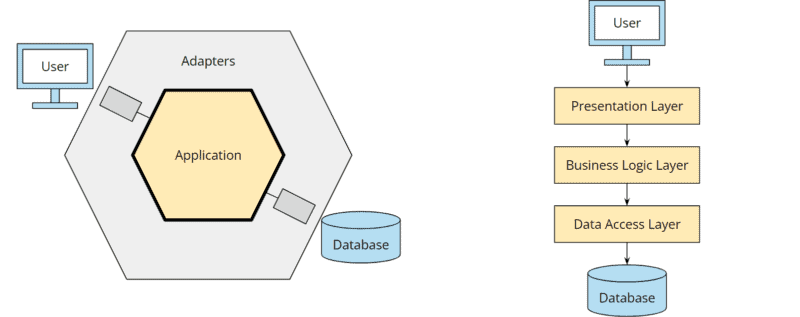
Wir wenden sozusagen ein „Database-Driven Design“ an und starten unsere Planungen damit, wie wir unser Modell in Tabellen speichern, anstatt zu überlegen, wie sich unser Modell verhalten soll.
Viele von uns Entwicklern arbeiten schon so lange mit dem Schichtenmodell, dass es in Fleisch und Blut übergegangen ist und wir es für das Normalste der Welt halten, eine Anwendung rund um eine Datenbank zu planen.
Ist es nicht viel sinnvoller, zuerst die Fachlichkeit einer Anwendung zu planen und zu entwickeln? Und erst dann, wenn es nötig ist, darüber nachzudenken, wie Daten persistiert werden? Sollte es nicht so sein, dass Änderungen in der Geschäftslogik ggf. Änderungen an der Persistenz erfordern – und nicht umgekehrt? Ich finde, ja.
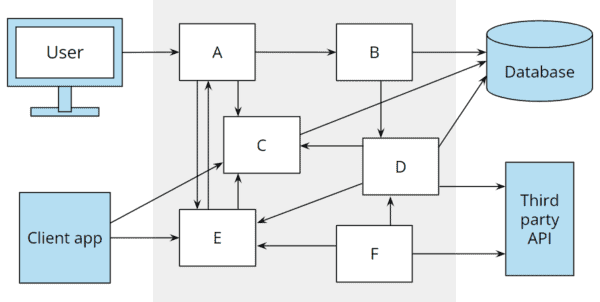
Und selten bleibt eine Geschäftsanwendung so einfach wie oben dargestellt. Wird die Anwendung erst einmal komplexer, werden zusätzliche Abhängigkeiten geschaffen. Die folgenden Abbildung zeigt die Architektur erweitert um eine REST-API und die Anbindung eines Drittanbieter-Services:
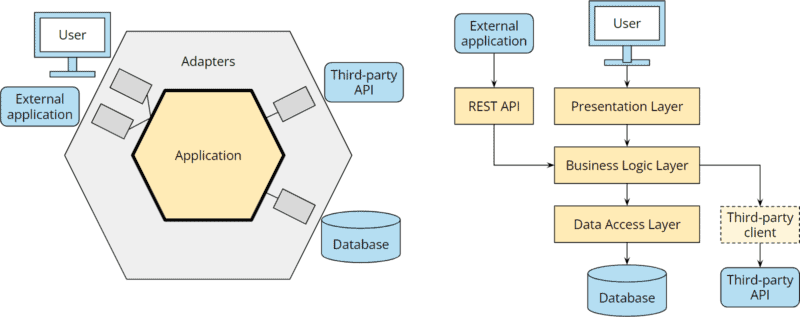
Bei der hexagonalen Architektur ist klar definiert, wo die zusätzlichen Komponenten hingehören.
Bei der Schichtenarchitektur wird oft eine REST-API an die Geschäftslogik gehängt (dabei wird evtl. im Presentation Layer implementierte Geschäftslogik dupliziert, wenn nicht vorher refactored wird), und die Geschäftslogik wiederum erhält eine zusätzliche Abhängigkeit auf den externen Service.
Den „Third-party client“ habe ich gestrichelt eingezeichnet, da dieser auch gerne weggelassen und direkt aus dem Business Layer (wenn nicht sogar aus dem Presentation Layer) auf die Schnittstelle der externen Anwendung zugegriffen wird.
Während bei der hexagonalen Architektur ein Port und zwei Adapter mit klaren Quellcode-Abhängigkeiten Richtung Kern hinzugekommen sind, wächst das Abhängigkeitschaos zwischen den Schichten: Wir haben jetzt transitive Abhängigkeiten von der REST-API zur Datenzugriffsschicht, von der REST-API zur Third-Party-API, vom User-Interface zur Datenzugriffsschicht und vom User-Interface zur Third-Party-API:
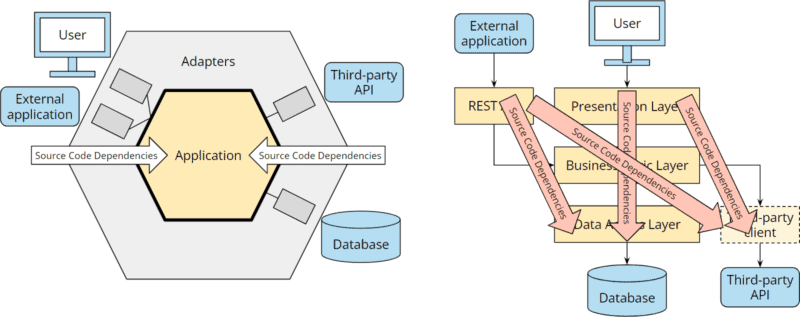
Diese Anhängigkeiten machen nicht nur den Code der unteren Schichten in REST-API, Presentation Layer und Business Layer verfügbar, sondern auch alle dort verwendeten Libraries. Und so verschwimmen die Architekturgrenzen weiter.
Hexagonale Architektur vs. Clean Architecture
Clean Architecture wurde 2012 von Robert Martin („Uncle Bob“) auf seinem Clean Coders Blog vorgestellt und 2017 im Buch „Clean Architecture“ ausführlich beschrieben.
Wie in der hexagonalen Architektur steht auch in der Clean Architecture die Geschäftslogik („Business Rules“) im Mittelpunkt. Um sie herum befinden sich die sogenannten Schnittstellenadapter („Interface Adapters“), welche den Kern mit der Benutzeroberfläche, der Datenbank und anderen externen Komponenten verbinden. Der Kern kennt nur die Schnittstellen der Adapter, weiß aber nichts über deren konkrete Implementierungen und die dahinter liegenden Komponenten.
Auch bei der Clean Architecture zeigen alle Quellcode-Abhängigkeiten ausschließlich in Richtung des Kerns. Dort, wo die Aufrufe von innen nach außen, also in die entgegengesetzte Richtung zur Quellcode-Abhängigkeit, führen, wird ebenfalls das Dependency Inversion Principle eingesetzt.
Die folgenden Grafik zeigt hexagonale Architektur und Clean Architecture gegenübergestellt:
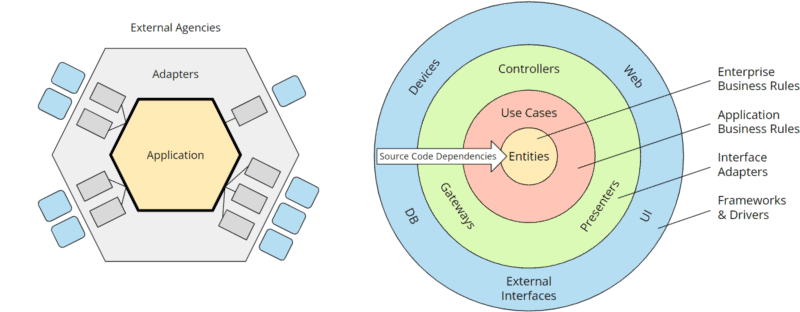
Wenn wir in der hexagonalen Architektur die Farben etwas anpassen und in der Clean Architecture die konkreten Adapter und externen Komponenten durch namenlose Platzhalter ersetzen, entstehen zwei sehr ähnliche Abbildungen:

Die Hexagone lassen sich nahezu eins zu eins auf die Ringe der Clean Architecture übertragen:
- Die um das äußere Hexagon angeordneten „External Agencies“ entsprechen dem äußeren Ring der Clean Architecture, „Frameworks & Drivers“.
- Das äußere Hexagon „Adapters“ entspricht dem Ring „Interface Adapters“.
- Das Application Hexagon entspricht in der Clean Architecture den „Business Rules“, also den Geschäftsregeln. Diese werden allerdings weiter unterteilt in „Unternehmensbezogene Geschäftsregeln“ (Entities) und „Geschäftsregeln der Anwendung“ (Use Cases, die die Entities orchestrieren und den Datenfluss von und zu ihnen steuern). Die hexagonale Architektur hingegen lässt die Architektur innerhalb des Application Hexagons bewusst offen.
Die Ports werden in der Clean Architecture nicht explizit genannt, sind aber in den zugehörigen UML-Diagrammen und Quellcode-Beispielen in Form von Interfaces ebenfalls vorhanden:
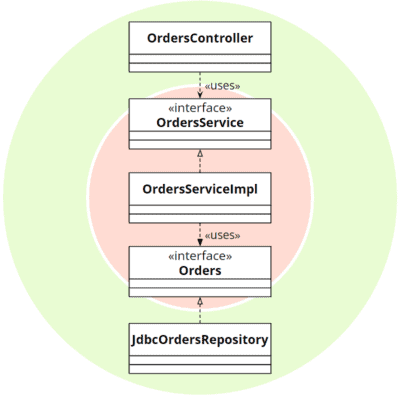
Zusammengefasst sind also beide Architekturen nahezu identisch: Die Software ist in Schichten aufgeteilt und alle Quellcode-Abhängigkeiten zeigen von den äußeren zu den inneren Schichten. Der Kern der Anwendung kennt keine Einzelheiten der äußeren Schichten und wird nur gegen deren Schnittstellen implementiert. So entsteht ein System, dessen technische Details austauschbar sind und das ohne diese vollständig testbar ist.
Hexagonale Architektur vs. Onion Architecture
Auch bei der von Jeffrey Palermo 2008 auf seinem Blog vorgestellten „Onion Architecture“ steht die Geschäftslogik im Kern, im sogenannten „Application Core“. Dieser definiert Schnittstellen zum User Interface und zur Infrastruktur (Datenbank, Filesystem, externe Systeme, usw.), kennt aber deren konkreten Implementierungen nicht. Somit wird auch hier der Kern von der Infrastruktur isoliert.
Genau wie bei der hexagonalen Architektur und bei der Clean Architecture zeigen auch bei der Onion Architecture alle Quellcode-Abhängigkeiten Richtung Kern. Dort, wo die Aufrufrichtung vom Kern zur Infrastruktur, also entgegengesetzt zur Quellcode-Abhängigkeit, geht, wird dies ebenfalls durch Dependency Inversion erreicht.
In der folgenden Grafik siehst du die hexagonale Architektur und die Onion Architektur gegenübergestellt:
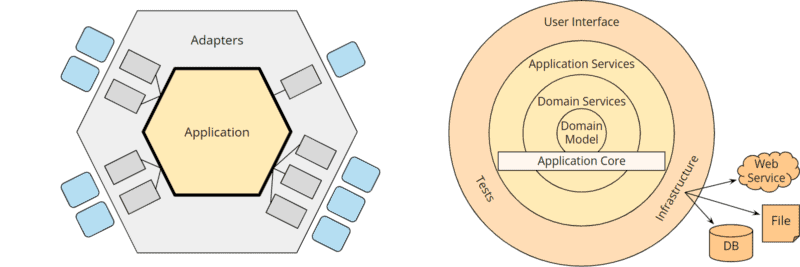
Wenn wir erneut die Farben etwas anpassen und in der Onion Architecture User Interface, Tests und Infrastruktur durch Platzhalter ersetzen und die optionalen Ringe des Applikationskernes ausblenden, entstehen wieder zwei sehr ähnliche Abbildungen:
Die Hexagone lassen sich nahezu eins zu eins auf die Ringe der Onion Architektur abbilden:
- Die um das äußere Hexagon angeordneten „External Agencies“ werden in der Onion Architektur durch die Infrastrukturkomponenten rechts unten dargestellt.
- Das äußere Hexagon „Adapters“ entspricht dem Ring, der „User Interface“, „Tests“ und „Infrastructure“ enthält.
- Das Application Hexagon entspricht in der Onion Architecture dem „Application Core“. Dieser wird weiter unterteilt in „Application Services“, „Domain Services“ und „Domain Model“, wobei nur das „Domain Model“ fester Bestandteil der Onion Architecture ist. Die weiteren Ringe des Anwendungskerns sind explizit als variabel gekennzeichnet. Das „Domain Model“ definiert die „Enterprise Business Rules“ und entspricht damit dem „Entities“-Ring – also dem innersten Ring – der Clean Architecture.
Im Endeffekt ist also auch die Onion Architecture nahezu identisch mit der hexagonalen Architektur – sie unterscheidet sich letztendlich nur durch das explizite „Domänenmodell“ im Zentrum des Anwendungskerns.
Zusammenfassung und Ausblick
Hexagonale Architektur bzw. „Ports and Adapters“ (alternativ Clean Architecture oder Onion-Architektur) sind ein Architekturmuster, das die Probleme der herkömmlichen Schichtenarchitektur (das Durchsickern von technischen Details in andere Schichten, schlechte Testbarkeit) eliminiert und es ermöglicht Entscheidungen über technische Details (z. B. die verwendete Datenbank) hinauszuschieben und zu ändern, ohne den Kern der Anwendung anpassen zu müssen.
Fachlicher Code befindet sich im Anwendungskern, bleibt dort unabhängig von technischem Code der Infrastruktur und kann isoliert entwickelt und getestet werden.
Alle Quellcode-Anhängigkeiten zeigen ausschließlich Richtung Kern. Dort wo die Aufrufe in die entgegengesetzte Richtung gehen, also vom Kern zur Infrastruktur (z. B. zur Datenbank), wird dies durch das Dependency Inversion Prinzip ermöglicht.
Das hexagonale Entwurfsmuster erfordert einen gewissen Mehraufwand und eigent sich daher insbesondere für komplexe Geschäftsanwendungen mit einer erwarteten Lebenszeit von mehreren Jahren bis Jahrzehnten.
Dieser Artikel ist der erste einer mehrteiligen Serie. In den folgenden Teilen werde ich dir zeigen:
- Wie implementiert man eine hexagonale Architektur mit Java – ganz ohne Application-Framework wie Spring oder Quarkus?
- Wie kann man die Einhaltung der Architekturvorgaben sicherstellen?
- Wie verbindet man einen Persistenz-Port, der bereits mit einem In-Memory-Adapter verbunden ist, mit einem zusätzlichen Datenbank-Adapter?
- Wie implementiert man eine hexagonale Architektur mit Quarkus?
- Wie implementiert man eine hexagonale Architektur mit Spring Boot?