
O-Notation und Zeitkomplexität – anschaulich erklärt

Die O-Notation (ausgesprochen: "Groß O Notation")¹ wird eingesetzt, um die Komplexität von Algorithmen zu beschreiben.
Auf Google und YouTube findet man zahlreiche Artikel und Videos, die die O-Notation erklären. Doch für das Verständnis der meisten davon (wie z. B. dieses Wikipedia-Artikels), sollte man als Vorbereitung ein Mathematik-Studium absolviert haben. ;-)
In diesem Artikel werde ich daher die O-Notation und die damit beschriebene Zeit- und Platzkomplexität ausschließlich anhand von Beispielen und Diagrammen erklären – und ganz ohne mathematische Formeln, Beweisführungen und Symbole wie θ, Ω, ω, ∈, ∀, ∃ und ε.
Alle Quellcodes aus diesem Artikel findest du in diesem GitHub-Repository.
¹ alternative Bezeichnungen: "Landau-Notation" oder "Asymptotische Notation"; englisch: "Big O notation".
Arten von Komplexität
Zeitkomplexität
Zeitkomplexität (englisch: "computational time complexity") beschreibt die Änderung der Ausführungszeit eines Algorithmus in Abhängigkeit von der Änderung der Größe der Eingabedaten.
Oder anders gesagt: "Um wie viel verlangsamt sich ein Algorithmus, wenn die Menge der Eingabedaten größer wird?"
Beispiele:
- Wie viel länger dauert es ein Element innerhalb eines unsortierten Arrays zu suchen, wenn sich die Größe des Arrays verdoppelt? (Antwort: doppelt so lange)
- Wie viel länger dauert es ein Element innerhalb eines sortierten Arrays zu suchen, wenn sich die Größe des Arrays verdoppelt? (Antwort: einen Schritt mehr)
Platzkomplexität
Platzkomplexität (englisch: "space complexity") beschreibt, wie viel zusätzlichen Speicherplatz ein Algorithmus in Abhängigkeit von der Größe der Eingabedaten benötigt.
Damit ist nicht der Speicherbedarf für die Eingabedaten selbst gemeint (d. h. dass man für ein doppelt so großes Eingabe-Array selbstverständlich doppelt so viel Platz benötigt), sondern derjenige Speicher, den der Algorithmus für Schleifen- und Hilfsvariablen, temporäre Datenstrukturen und Call Stack (z. B. durch Rekursion) zusätzlich benötigt.
Komplexitätsklassen
Algorithmen werden in sogenannte Komplexitätsklassen eingeteilt. Eine Komplexitätsklasse wird mit dem Landau-Symbol O ("Groß O") gekennzeichnet.
Im folgenden stelle ich die wichtigsten Komplexitätsklassen vor, wobei ich mit den leicht verständlichen Klassen beginne und dann zu den etwas komplizierteren komme. Dementsprechend sind die Klassen nicht nach Aufwand sortiert.
O(1) – konstanter Aufwand
Ausgesprochen: "O von 1"
Die Ausführungszeit ist konstant, also unabhängig von der Anzahl der Eingabeelemente n.
Im folgenden Graph stellt die horizontale Achse die Anzahl der Eingabeelemente n (oder allgemeiner: die Größe des Eingabeproblems) dar und die vertikale Achse die benötigte Zeit.
Da Komplexitätsklassen nur verwendet werden können, um Algorithmen einzuordnen, nicht aber, um deren genaue Laufzeit zu berechnen, sind die Achsen nicht beschriftet.

O(1) Beispiele
Die folgenden zwei Problemstellungen sind Beispiele für konstanten Aufwand:
- Zugriff auf ein bestimmtes Element eines Arrays der Größe n: Egal wie groß ein Array ist, der Zugriff über
array[index]benötigt immer die gleiche Zeit². - Einfügen eines Elements am Anfang einer verketteten Liste: Dies erfordert immer das Setzen von einem bzw. zwei (bei einer doppelt verketteten Liste) Zeigern (oder Referenzen), unabhängig davon, wie groß die verkettete Liste ist. (Bei einem Array hingegen müssten dazu alle Werte um ein Feld nach rechts verschoben werden, was bei einem größeren Array länger dauert als bei einem kleineren.)
² Hundertprozentig korrekt ist diese Aussage nicht, denn hier kommen auch noch Effekte durch die CPU-Caches ins Spiel: Wenn der Datenblock, der das auszulesende Element enthält, bereits (oder noch) im CPU-Cache liegt (wofür die Wahrscheinlichkeit größer ist, je kleiner das Array ist), dann ist der Zugriff schneller, als wenn dieser erst aus dem RAM gelesen werden muss.
O(1) Beispiel-Quellcode
Der folgende Quellcode (Klasse ConstantTimeSimpleDemo im GitHub-Repository) zeigt ein einfaches Beispiel zur Messung des Aufwandes für das Einfügen eines Elements am Anfang einer verketteten Liste:
public static void main(String[] args) {
for (int n = 32; n <= 8_388_608; n *= 2) {
LinkedList<Integer> list = createLinkedListOfSize(n);
long time = System.nanoTime();
list.add(0, 1);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
private static LinkedList<Integer> createLinkedListOfSize(int n) {
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < n; i++) {
list.add(i);
}
return list;
}Code-Sprache: Java (java)Bei mir liegen die benötigten Zeiten – ungleichmäßig über die verschiedenen Messungen verteilt – zwischen 1.200 ns und 19.000 ns. Für einen schnellen Test reicht das aus. Allerdings bekommen wir hier keine besonders guten Messergebnisse, da sowohl HotSpot-Compiler als auch Garbage Collector jederzeit anspringen können.
Bessere Messergebnisse liefert das Testprogramm TimeComplexityDemo mit der Klasse ConstantTime. Hier werden zunächst mehrere Warmup-Runden ausgeführt, um dem HotSpot-Compiler die Gelegenheit zu geben den Code zu optimieren. Erst danach werden wiederholt Messungen vorgenommen und der Median der Messwerte ausgegeben.
Hier ein Auszug der Ergebnisse:
--- ConstantTime (results 5 of 5) ---
ConstantTime, n = 32 -> fastest: 31,700 ns, median: 44,900 ns
ConstantTime, n = 16,384 -> fastest: 14,400 ns, median: 40,200 ns
ConstantTime, n = 8,388,608 -> fastest: 34,000 ns, median: 51,100 nsCode-Sprache: Klartext (plaintext)Der Aufwand bleibt also in etwa gleich, unabhängig von der Größe der Liste. Die vollständigen Testergebnisse findest du in der Datei test-results.txt.
O(n) – linearer Aufwand
Ausgesprochen: "O von n"
Der Aufwand wächst linear mit der Anzahl der Eingabeelemente n: Verdoppelt sich n, dann verdoppelt sich auch ungefähr der Aufwand.
"Ungefähr" deshalb, weil der Aufwand auch Komponenten mit niedrigeren Komplexitätsklassen enthalten kann. Diese fallen bei hinreichend großem n nicht ins Gewicht, so dass sie bei der Notation vernachlässigt werden.
In folgendem Diagramm habe ich das dadurch demonstriert, dass der Graph etwas oberhalb des Nullpunkts beginnt (der Aufwand enthält also auch eine konstante Komponente):

O(n) Beispiele
Die folgenden Problemstellungen sind Beispiele für linearen Aufwand:
- Finden eines bestimmten Elements in einem Array: Es müssen dazu alle Elemente des Arrays betrachtet werden – bei doppelt so vielen Elementen dauert es doppelt so lang.
- Summieren aller Elemente eines Arrays: Auch dafür müssen alle Elemente einmal betrachtet werden – ist das Array doppelt so groß, dauert es doppelt so lang.
Es ist wichtig zu verstehen, dass die Komplexitätsklasse keine Aussage über die absolut benötigte Zeit macht, sondern lediglich über die Änderung der benötigten Zeit in Abhängigkeit von der Änderung der Eingabegröße. Beispielsweise würde die beiden o. g. Beispiele mit einer verketteten Liste deutlich länger benötigen als mit einem Array – an der Komplexitätsklasse ändert das jedoch nichts.
O(n) Beispiel-Quellcode
Der folgende Quellcode (Klasse LinearTimeSimpleDemo) misst den Aufwand für das Summieren aller Elemente eines Arrays:
public static void main(String[] args) {
for (int n = 32; n <= 536_870_912; n *= 2) {
int[] array = createArrayOfSize(n);
long sum = 0;
long time = System.nanoTime();
for (int i = 0; i < n; i++) {
sum += array[i];
}
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
private static int[] createArrayOfSize(int n) {
int[] array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = i;
}
return array;
}Code-Sprache: Java (java)Auf meinem System steigt die benötigte Zeit von 1.100 ns auf 155.911.900 ns ungefähr linear an. Bessere Messergebnisse liefert auch hier das Testprogramm TimeComplexityDemo mit der Algorithmus-Klasse LinearTime – hier ein Auszug der Ergebnisse:
--- LinearTime (results 5 of 5) ---
LinearTime, n = 512 -> fastest: 300 ns, median: 300 ns
LinearTime, n = 524,288 -> fastest: 159,300 ns, median: 189,400 ns
LinearTime, n = 536,870,912 -> fastest: 164,322,600 ns, median: 168,681,700 nsCode-Sprache: Klartext (plaintext)Die vollständigen Testergebnisse findest du auch hier wieder in test-results.txt.
Was ist der Unterschied zwischen "linear" und "proportional"?
Eine Funktion ist linear, wenn sie durch eine gerade Linie dargestellt weden kann, z. B. f(x) = 5x + 3.
Proportional ist ein Sonderfall von linear, bei dem die Linie durch den Punkt (0,0) des Koordinatensystems geht, z. B. f(x) = 3x.
Da es in der Klasse O(n) einen konstanten Anteil geben kann, handelt es sich um linearen Aufwand.
O(n²) – quadratischer Aufwand
Ausgesprochen: "O von n Quadrat"
Der Aufwand wächst quadratisch mit der Anzahl der Eingabeelemente: Verdoppelt sich die Anzahl der Eingabeelemente n, dann vervierfacht sich in etwa der Aufwand. (Und verzehnfacht sich die Anzahl der Elemente, wächst die benötigte Zeit um den Faktor Hundert!)

O(n²) Beispiele
Beispiele für quadratischen Aufwand sind einfache Sortieralgorithmen wie Insertion Sort, Selection Sort und Bubble Sort.
O(n²) Beispiel-Quellcode
Das folgende Beispiel (QuadraticTimeSimpleDemo) zeigt, wie sich der Aufwand für das Sortieren eines Arrays mittels Insertion Sort in Abhängigkeit von der Größe des Arrays ändert:
public static void main(String[] args) {
for (int n = 32; n <= 262_144; n *= 2) {
int[] array = createRandomArrayOfSize(n);
long time = System.nanoTime();
insertionSort(array);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
private static int[] createRandomArrayOfSize(int n) {
ThreadLocalRandom random = ThreadLocalRandom.current();
int[] array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = random.nextInt();
}
return array;
}
private static void insertionSort(int[] elements) {
for (int i = 1; i < elements.length; i++) {
int elementToSort = elements[i];
int j = i;
while (j > 0 && elementToSort < elements[j - 1]) {
elements[j] = elements[j - 1];
j--;
}
elements[j] = elementToSort;
}
}Code-Sprache: Java (java)Bessere Messergebnisse bekommt man wiederum mit dem Testprogramm TimeComplexityDemo und der Klasse QuadraticTime. Hier der Auszug der Ergebnisse, bei dem man schön die jeweilige ungefähre Vervierfachung der Zeit bei Verdoppelung der Problemgröße erkennen kann:
QuadraticTime, n = 8,192 -> fastest: 4,648,400 ns, median: 4,720,200 ns
QuadraticTime, n = 16,384 -> fastest: 19,189,100 ns, median: 19,440,400 ns
QuadraticTime, n = 32,768 -> fastest: 78,416,700 ns, median: 79,896,000 ns
QuadraticTime, n = 65,536 -> fastest: 319,905,300 ns, median: 330,530,600 ns
QuadraticTime, n = 131,072 -> fastest: 1,310,702,600 ns, median: 1,323,919,500 nsCode-Sprache: Klartext (plaintext)Die vollständigen Testergebnisse findest du in test-results.txt.
O(n) vs. O(n²)
An dieser Stelle möchte ich noch einmal darauf hinweisen, dass der Aufwand Komponenten niedrigerer Komplexitätsklassen und konstante Faktoren enthalten kann. Beides ist für die O-Notation irrelevant, da diese bei hinreichend großem n nicht mehr ins Gewicht fallen.
Es kann somit auch sein, dass beispielsweise O(n²) schneller ist als O(n) – zumindest bis zu einer gewissen Größe von n.
Im folgenden Beispiel-Diagramm werden drei fiktive Algorithmen gegenübergestellt: einer mit der Komplexitätsklasse O(n²) und zwei mit O(n), wobei einer davon schneller ist als der andere. Es ist gut zu sehen, wie bis zu n = 4 der orangene O(n²)-Algorithmus weniger Zeit benötigt als der gelbe O(n)-Algorithmus. Und sogar bis n = 8 weniger Zeit als der türkise O(n)-Algorithmus.
Ab hinreichend großem n – also ab n = 9 – ist und bleibt O(n²) der langsamste Algorithmus.

Als nächstes kommen wir zu zwei nicht ganz so intuitiv verständlichen Komplexitätsklassen.
O(log n) – logarithmischer Aufwand
Ausgesprochen: "O von log n"
Der Aufwand wächst ungefähr um einen konstanten Betrag, wenn sich die Anzahl der Eingabeelemente verdoppelt.
Wenn sich beispielsweise der Aufwand um eine Sekunde erhöht, wenn die Anzahl der Eingabeelemente von 1.000 auf 2.000 steigt, dann erhöht er sich lediglich um eine weitere Sekunde, wenn der Aufwand auf 4.000 steigt und wiederum um eine weitere Sekunde, wenn der Aufwand auf 8.000 steigt.

O(log n) Beispiel
Ein Beispiel für logarithmischen Aufwand ist die binäre Suche nach einem bestimmten Element in einem sortierten Array der Größe n.
Da wir mit jedem Suchschritt den zu durchsuchenden Bereich halbieren, können wir im Umkehrschluss mit nur einem Suchschritt mehr ein doppelt so großes Array durchsuchen.
(Die älteren unter uns kennen das vielleicht noch von der Suche im Telefonbuch oder in einem Lexikon.)
O(log n) Beispiel-Quellcode
Das folgende Beispiel (LogarithmicTimeSimpleDemo) misst, wie sich der Aufwand für die binäre Suche innerhalb eines sortierten Arrays im Verhältnis zur Größe des Arrays verändert:
public static void main(String[] args) {
for (int n = 32; n <= 536_870_912; n *= 2) {
int[] array = createArrayOfSize(n);
long time = System.nanoTime();
Arrays.binarySearch(array, 0);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
private static int[] createArrayOfSize(int n) {
int[] array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = i;
}
return array;
}Code-Sprache: Java (java)Bessere Messergebnisse bekommen wir, wie zuvor, mit dem Testprogramm TimeComplexityDemo und der Klasse LogarithmicTime. Hier die Ergebnisse:
LogarithmicTime, n = 32 -> fastest: 77,800 ns, median: 107,200 ns
LogarithmicTime, n = 2,048 -> fastest: 173,500 ns, median: 257,400 ns
LogarithmicTime, n = 131,072 -> fastest: 363,400 ns, median: 413,100 ns
LogarithmicTime, n = 8,388,608 -> fastest: 661,100 ns, median: 670,800 ns
LogarithmicTime, n = 536,870,912 -> fastest: 770,500 ns, median: 875,700 nsCode-Sprache: Klartext (plaintext)Die Problemgröße n wächst hier jeweils um den Faktor 64. Der Aufwand wächst nicht immer exakt um den gleichen Wert, aber doch ausreichend genau, um zu demonstrieren, dass logarithmischer Aufwand deutlich günstiger ist als linearer Aufwand (bei welchem die benötigte Zeit auch jeweils um den Faktor 64 wachsen würde).
Die vollständigen Testergebnisse findest Du, wie auch zuvor, in der Datei test-results.txt.
O(n log n) – quasi-linearer Aufwand
Ausgesprochen: "O von n log n"
Der Aufwand wächst etwas stärker als linear, da die lineare Komponente mit einer logarithmischen multipliziert wird; man kann zum besseren Verständnis auch ein Multiplikationszeichen einfügen: O(n × log n).
Am besten lässt sich das am Graphen veranschaulichen. Wir haben hier eine Kurve, deren Steigung zu Beginn noch sichtbar wächst, mit wachsendem n sich aber einer Geraden annähert:

O(n log n) Beispiel
Als Beispiele für quasi-linearen Aufwand können effiziente Sortieralgorithmen wie Quicksort, Mergesort und Heapsort genannt werden.
O(n log n) Beispiel-Quellcode
Der folgende Beispiel-Code (Klasse QuasiLinearTimeSimpleDemo) zeigt, wie sich der Aufwand für das Sortieren eines Arrays mit Quicksort³ im Verhältnis zur Array-Größe ändert:
public static void main(String[] args) {
for (int n = 64; n <= 67_108_864; n *= 2) {
int[] array = createRandomArrayOfSize(n);
long time = System.nanoTime();
Arrays.sort(array);
time = System.nanoTime() - time;
System.out.printf("n = %d -> time = %d ns%n", n, time);
}
}
private static int[] createRandomArrayOfSize(int n) {
ThreadLocalRandom random = ThreadLocalRandom.current();
int[] array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = random.nextInt();
}
return array;
}
Code-Sprache: Java (java)Genauer wird es wieder mit dem Testprogramm TimeComplexityDemo und der Klasse QuasiLinearTime. Hier ein Auszug der Ergebnisse:
QuasiLinearTime, n = 256 -> fastest: 12,200 ns, med.: 12,500 ns
QuasiLinearTime, n = 4,096 -> fastest: 228,600 ns, med.: 234,200 ns
QuasiLinearTime, n = 65,536 -> fastest: 4,606,500 ns, med.: 4,679,800 ns
QuasiLinearTime, n = 1,048,576 -> fastest: 93,933,500 ns, med.: 95,216,300 ns
QuasiLinearTime, n = 16,777,216 -> fastest: 1,714,541,900 ns, med.: 1,755,715,000 nsCode-Sprache: Klartext (plaintext)Die Problemgröße steigt hier jeweils um den Faktor 16 und die benötigte Zeit um Faktor 18,5 bis 20,3. Das vollständige Testergebnis findest du, wie immer, in test-results.txt.
³ Genauer gesagt: Dual-Pivot Quicksort, welches bei Arrays mit weniger als 44 Elementen auf Insertion Sort wechselt. Aus diesem Grund startet dieser Test bei 64 Elementen, nicht bei 32 wie die anderen.
O-Notation Reihenfolge
Hier noch einmal die vorgestellten Komplexitätsklassen, aufsteigend sortiert nach Komplexität:
- O(1) – konstanter Aufwand
- O(log n) – logarithmischer Aufwand
- O(n) – linearer Aufwand
- O(n log n) – quasi-linearer Aufwand
- O(n²) – quadratischer Aufwand
Und hier der Vergleich in graphischer Darstellung:
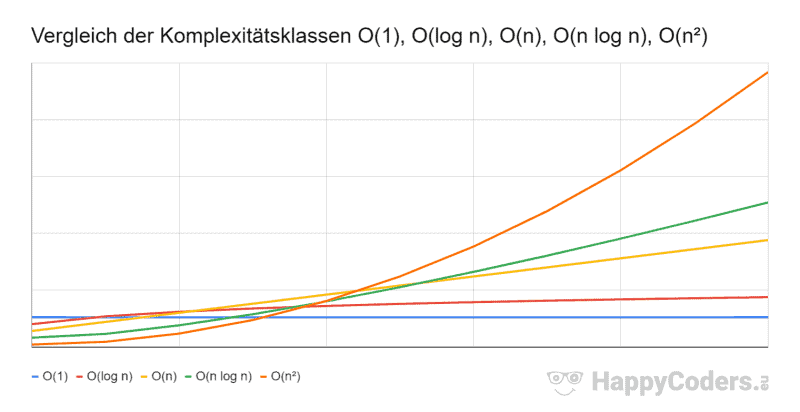
Ich habe die Kurven absichtlich so entlang der Aufwandsachse verschoben, dass die schlechteste Komplexitätsklasse O(n²) bei niedrigem n am schnellsten ist und die beste Komplexitätsklasse O(1) am langsamsten. Um dann zu zeigen, wie sich für hinreichend hohe Werte von n die Aufwände entsprechend den Erwartungen verschieben.
Weitere Komplexitätsklassen
Weitere Komplexitätsklassen sind z. B.
- O(nm) – polynomieller Aufwand
- O(2n) – exponentieller Aufwand
- O(n!) – faktorieller Aufwand
Diese sind jedoch so schlecht, dass wir Algorithmen mit diesen Komplexitäten möglichst vermeiden sollten.
Im folgenden Diagram habe ich diese Klassen noch einmal mit aufgenommen (für O(nm) mit m=3):

Die y-Achse musste ich hier im Vergleich zum vorherigen Diagramm um Faktor 10 stauchen, damit ich die drei zusätzlichen Kurven sinnvoll abbilden konnte.
Fazit
Zeitkomplexität beschreibt, wie sich die Laufzeit eines Algorithmus in Abhängigkeit von der Menge der Eingabedaten verändert. Die gebräuchlichsten Komplexitätsklassen sind (aufsteigend sortiert nach Aufwand): O(1), O(log n), O(n), O(n log n), O(n²).
Algorithmen mit konstantem, logarithmischem, linearem und quasi-linearem Aufwand führen in der Regel bei Eingabegrößen bis zu mehreren Milliarden Elementen in überschaubarer Zeit zu einem Ende, während Algorithmen mit quadratischem Aufwand für dieselben Eingabemengen schnell theoretische Ausführungszeiten von mehreren Jahren erreichen können⁴. Sie sollten also, soweit wie möglich, vermieden werden.
⁴ Quicksort beispielsweise sortiert auf meinem Laptop eine Milliarde Elemente in 90 Sekunden; Insertion Sort hingegen braucht für eine Million Elemente 85 Sekunden; das wären auf eine Milliarde Elemente hochgerechnet 85 Millionen Sekunden – oder anders ausgedrückt: etwas über zwei Jahre und acht Monate!