


Heapsort – Algorithmus, Quellcode, Zeitkomplexität
Bei Heapsort denkt jeder Java-Entwickler zunächst an den Java-Heap. Dass Heapsort damit nichts zu tun hat – und wie Heapsort genau funktioniert – zeigt dir dieser Artikel.
Im Detail erfährst du:
- Was ist ein Heap?
- Wie funktioniert der Heapsort-Algorithmus?
- Wie sieht der Quellcode von Heapsort aus?
- Wie bestimmt man die Zeitkomplexität von Heapsort?
- Was ist Bottom-Up-Heapsort und welche Vorteile hat es?
- Wie schlägt sich Heapsort im Vergleich zu Quicksort und Mergesort?
Was ist ein Heap?
Ein "Heap" (deutsch: "Haufen" oder "Halde") bezeichnet einen Binärbaum, in dem jeder Knoten entweder größer/gleich seiner Kinder ist ("Max Heap") – oder kleiner/gleich seiner Kinder ("Min Heap").
Hier ist ein einfaches Beispiel für einen "Max Heap":
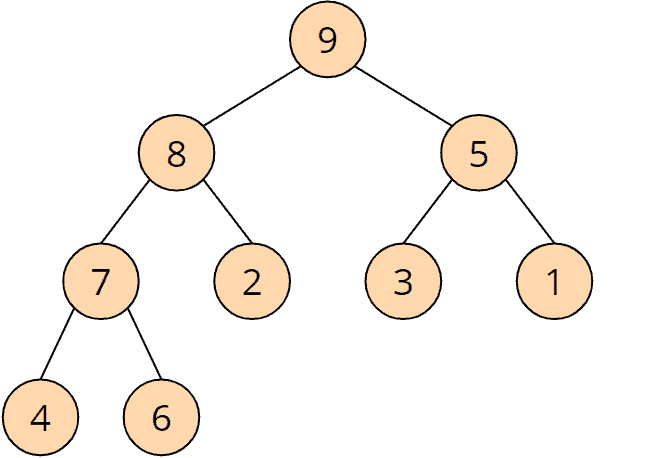
Die 9 ist größer als die 8 und die 5; die 8 ist größer als die 7 und die 2; usw.
Ein Heap wird auf ein Array projiziert, indem dessen Elemente von oben links zeilenweise nach rechts unten in das Array übertragen werden:
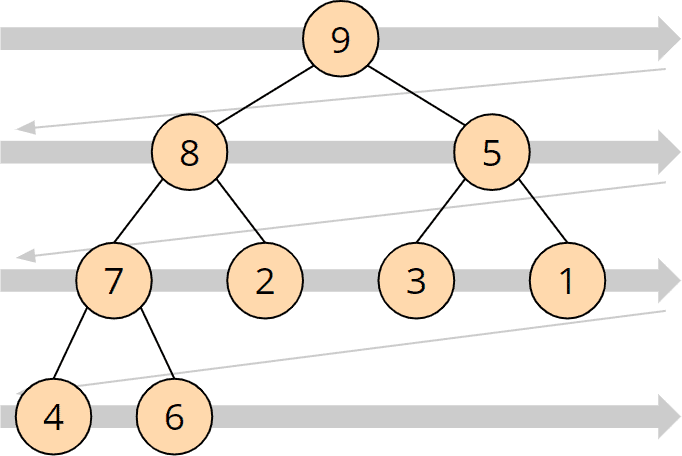
Der oben gezeigte Heap sieht als Array also so aus:
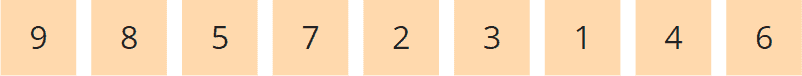
Bei einem "Max Heap" ist das größte Element immer ganz oben – in der Array-Form ist es folglich ganz links. Wie man diese Eigenschaft zum Sortieren verwenden kann, erfährst du im folgenden Abschnitt.
Heapsort-Algorithmus
Der Heapsort-Algorithmus besteht aus zwei Phasen: In der ersten Phase wird das zu sortierende Array in einen Max Heap umgewandelt. Und in der zweiten Phase wird jeweils das größte Element (also das an der Baumwurzel) entnommen und aus den restlichen Elementen erneut ein Max Heap hergestellt.
Die folgenden Abschnitte erklären die zwei Phasen im Detail anhand eines Beispiels:
Phase 1: Heap erstellen
Das zu sortierende Array muss zunächst in einen Heap umgewandelt werden. Dazu wird keine neue Datenstruktur angelegt, sondern die Zahlen werden innerhalb des Arrays so umsortiert, dass die oben beschriebene Heap-Struktur entsteht.
Wie dies geschieht erkläre ich in folgendem Beispiel anhand der aus den vorangegangenen Teilen der Artikelserie bekannten Zahlenfolge [3, 7, 1, 8, 2, 5, 9, 4, 6].
Diese "projizieren" wir wie oben beschrieben auf einen Binärbaum. Dabei ist der Binärbaum keine separate Datenstruktur, sondern lediglich ein Gedankenkonstrukt – im Speicher liegen die Elemente ausschließlich in dem Array.

Dieser Baum entspricht noch keinem Max Heap. Dessen Definiton lautet ja, dass Eltern immer größer oder gleich ihrer Kinder sind.
Um einen Max Heap herzustellen, besuchen wir nun alle Elternknoten – rückwärts vom letzten bis zum ersten – und sorgen dafür, dass die Heap-Bedingung für den jeweiligen Knoten und die darunter erfüllt ist. Dies machen wir mit der sogenannten heapify()-Funktion.
Aufruf Nr. 1 der heapify-Funktion
Die heapify()-Funktion wird zuerst für den letzten Elternknoten aufgerufen. Elternknoten sind 3, 7, 1 und 8. Der letzte Elternknoten ist die 8. Die heapify()-Funktion prüft, ob die Kinder kleiner sind als der Elternknoten. 4 und 6 sind kleiner als 8. An diesem Elternknoten ist die Heap-Bedingung also erfüllt, und die heapify()-Funktion ist beendet.
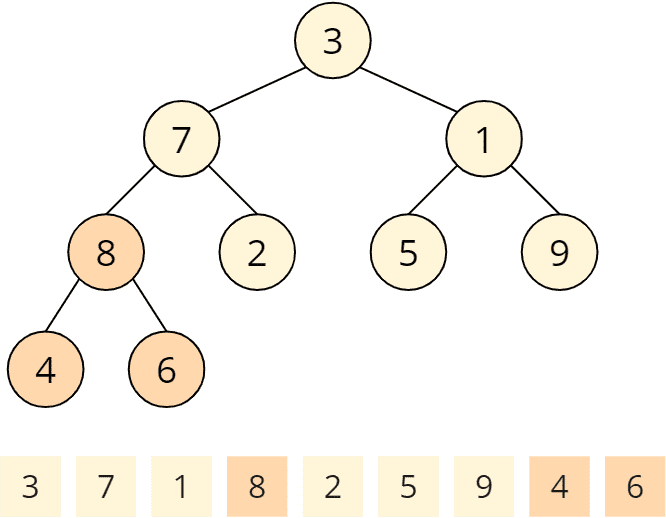
Aufruf Nr. 2 der heapify-Funktion
Als zweites wird heapify() für den vorletzten Knoten aufgerufen: die 1. Die Kinder 5 und 9 sind beide größer als die 1, die Heap-Bedingung ist also verletzt. Um die Heap-Bedingung wiederherzustellen, tauschen wir nun das größere Kind mit dem Elternknoten, also die 9 mit der 1. Die heapify()-Funktion ist damit wieder beendet.

Aufruf Nr. 3 der heapify-Funktion
Nun wird heapify() auf der 7 aufgerufen. Kindknoten sind 8 und 2, nur die 8 ist größer als der Elternknoten. Wir tauschen also die 7 mit der 8:

Da der Kindknoten, den wir eben getauscht haben, selbst zwei Kinder hat, muss die heapify()-Funktion nun prüfen, ob die Heap-Bedingung für diesen Kindknoten noch erfüllt ist. In diesem Fall ist die 7 größer als 4 und 6, die Heap-Bedingung ist also erfüllt; die heapify()-Funktion ist damit beendet.

Aufruf Nr. 4 der heapify-Funktion
Jetzt sind wir bereits am Wurzelknoten mit dem Element 3 angekommen. Beide Kindknoten, 8 und 9 sind größer, wobei die 9 das größte Kind ist und daher mit dem Elternknoten vertauscht wird:

Wiederum hat der getauschte Kindknoten selbst Kinder, so dass wir die Heap-Bedingung an diesem Kindknoten überprüfen müssen. Die 5 ist größer als die 3, d. h. die Heap-Bedingung ist nicht erfüllt und muss durch Tauschen der 5 und der 3 wiederhergestellt werden:

Damit ist auch der vierte und letzte Aufruf der heapify()-Funktion beendet. Ein Max Heap ist entstanden:

Damit gehen wir über in Phase zwei des Heapsort-Algorithmus.
Phase 2: Sortieren des Arrays
In Phase 2 machen wir uns die Tatsache zunutze, dass das größte Element des Max Heaps immer an dessen Wurzel (bzw. im Array ganz links) steht.
Phase 2, Schritt 1: Root und letztes Element tauschen
Das Wurzelelement (die 9) tauschen wir nun mit dem letzten Element (der 6), so dass die 9 an ihrer finalen Position am Ende des Arrays steht (im Array blau markiert). Außerdem entfernen wir dieses Element gedanklich aus dem Baum (im Baum grau dargestellt):

Nachdem wir die 6 an die Wurzel des Baumes gesetzt haben, ist dieser kein Max Heap mehr. Im nächsten Schritt "reparieren" wir den Heap.
Phase 2, Schritt 2: Heap-Bedingung wiederherstellen
Um die Heap-Bedingung wiederherzustellen, rufen wir die aus Phase 1 bekannte heapify()-Funktion auf dem Wurzelknoten auf. Wir vergleichen also die 6 mit ihren Kindern, 8 und 5. Die 8 ist größer, wir tauschen sie daher mit der 6:
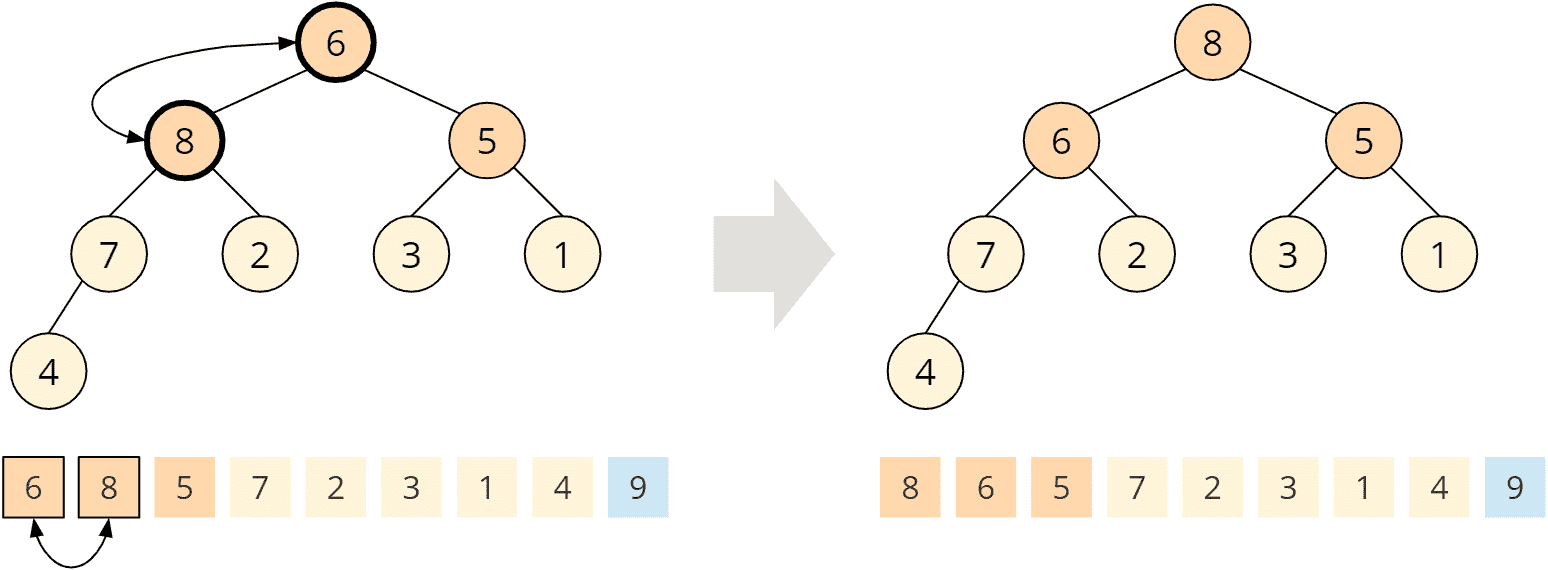
Der getauschte Kindknoten hat wiederum zwei Kinder, die 7 und die 2. Die 7 ist größer als die 6, daher tauschen wir auch diese zwei Elemente:

Der getauschte Kindknoten hat auch noch ein Kind, die 4. Die 6 ist größer als die 4, die Heap-Bedingung ist an diesem Knoten also erfüllt, so dass die heapify()-Funktion beendet ist und wir wieder einen Max Heap haben:

Wiederholung der Schritte
Damit steht nun wieder die größte Zahl des verbleibenden Arrays, die 8, an erster Stelle. Diese wird wieder mit dem letzten Element des Baums vertauscht. Da wir den Baum um ein Element gekürzt haben, liegt das letzte Element des Baumes auf dem vorletzten Feld des Arrays:

Damit sind die letzten zwei Felder des Arrays sortiert.
An der Wurzel ist nun wieder die Heap-Bedingung verletzt, und wir reparieren den Baum, indem wir heapify() auf dem Wurzelelement aufrufen (das folgende Bild zeigt alle heapify-Schritte auf einmal).

Wir wiederholen den Prozess solange, bis der Baum nur noch ein Element enthält:

Dieses ist das kleinste und verbleibt am Anfang des Arrays. Der Algorithmus ist beendet, das Array ist sortiert:

Heapsort Java Code Beispiel
Im folgenden findest du den Quellcode von Heapsort.
Die sort()-Methode ruft zunächst buildHeap() auf, um den Heap initial aufzubauen.
In der darauf folgenden Schleife iteriert die Variable swapToPos rückwärts vom Ende des Arrays bis zum zweiten Feld. Im Schleifenkörper wird das erste Element mit demjenigen an der Position swapToPos vertauscht und danach die heapify()-Methode auf dem Sub-Array bis zur (ausschließlichen) Position swapToPos aufgerufen:
public class HeapSort {
public void sort(int[] elements) {
buildHeap(elements);
for (int swapToPos = elements.length - 1; swapToPos > 0; swapToPos--) {
// Move root to end
ArrayUtils.swap(elements, 0, swapToPos);
// Fix remaining heap
heapify(elements, swapToPos, 0);
}
}
[...]
}Code-Sprache: Java (java)Die buildHeap()-Methode ruft für jeden Elternknoten – beginnend beim letzten – heapify() auf und übergibt dieser Methode das Array, die Länge des Sub-Arrays, das den Heap darstellt und die Position des Elternknotens, an dem heapify() starten soll:
void buildHeap(int[] elements) {
// "Find" the last parent node
int lastParentNode = elements.length / 2 - 1;
// Now heapify it from here on backwards
for (int i = lastParentNode; i >= 0; i--) {
heapify(elements, elements.length, i);
}
}Code-Sprache: Java (java)Die heapify()-Methode prüft, ob ein Kindknoten größer ist als der Elternknoten. Wenn das der Fall ist, wird das Elternelement mit dem größeren Kindelement vertauscht, und der Prozess wird auf dem Kindknoten wiederholt.
(Hier könnte man auch mit Rekursion arbeiten, was sich allerdings negativ auf die Platzkomplexität auswirken würde.)
void heapify(int[] heap, int length, int parentPos) {
while (true) {
int leftChildPos = parentPos * 2 + 1;
int rightChildPos = parentPos * 2 + 2;
// Find the largest element
int largestPos = parentPos;
if (leftChildPos < length && heap[leftChildPos] > heap[largestPos]) {
largestPos = leftChildPos;
}
if (rightChildPos < length && heap[rightChildPos] > heap[largestPos]) {
largestPos = rightChildPos;
}
// largestPos is now either parentPos, leftChildPos or rightChildPos.
// If it's the parent, we're done
if (largestPos == parentPos) {
break;
}
// If it's not the parent, then switch!
ArrayUtils.swap(heap, parentPos, largestPos);
// ... and fix again starting at the child we moved the parent to
parentPos = largestPos;
}
}Code-Sprache: Java (java)Du findest den Quellcode in der Klasse HeapSort im GitHub-Repository. Diese unterscheidet sich leicht von der hier abgedruckten Klasse: Die Klasse im Repository implementiert das Interface SortAlgorithm, um innerhalb des Testframeworks austauschbar zu sein.
Heapsort Zeitkomplexität
Klicke auf den folgenden Link für eine Einführung in "Zeitkomplexität" und "O-Notation" (mit Beispielen und Diagrammen).
Zeitkomplexität der heapify()-Methode
Fangen wir mit der heapify()-Funktion an, da diese auch für den initialen Aufbau des Heaps benötigt wird.
In der heapify()-Funktion hangeln wir uns einmal von oben nach unten durch den Baum. Die Höhe eines Binärbaumes (die Wurzel wird nicht mitgezählt) der Größe n ist maximal log2 n, d. h. bei einer Verdopplung der Anzahl Elemente wird der Baum lediglich eine Ebene tiefer:

Die Komplexität für die heapify()-Funktion ist entsprechend O(log n).
Zeitkomplexität der buildHeap()-Methode
Für den erstmaligen Aufbau des Heaps wird für jeden Elternknoten – rückwärts, beginnend beim letzten Knoten und endend an der Baumwurzel – die heapify()-Methode aufgerufen.
Ein Heap der Größe n hat n/2 (abgerundet) Elternknoten:

Da die Komplexität der heapify()-Methode, wie oben gezeigt, O(log n) ist, ist die Komplexität für die buildHeap()-Methode also maximal* O(n log n).
* Im übernächsten Abschnitt werde ich zeigen, dass die Zeitkomplexität der buildHeap()-Methode sogar O(n) ist. Da dies an der Gesamt-Zeitkomplexität nichts ändert, ist es nicht zwingend erforderlich, diese detailliertere Analyse durchzuführen.
Gesamt-Zeitkomplexität von Heapsort
Die heapify()-Funktion wird n-1 mal aufgerufen. Die Gesamtkomplexität für das Reparieren des Heaps ist also ebenfalls O(n log n).
Beide Teilalgorithmen haben also die gleiche Zeitkomplexität. Es gilt somit:
Die Zeitkomplexität von Heapsort beträgt: O(n log n)
Zeitkomplexität für den Aufbau des Heaps – genauer analysiert
Dieser Abschnitt ist sehr mathematisch und für die Herleitung der Zeitkomplexität des Gesamtalgorithmus (die wir ja bereits abgeschlossen haben) nicht zwingend erforderlich. Du kannst diesen Abschnitt daher auch überspringen.
Wir haben oben festgestellt, dass die buildHeap()-Methode für jeden Elternknoten heapify() aufruft. Was wir bisher nicht berücksichtigt haben ist, dass die Tiefe der Teilbäume, auf denen heapify() aufgerufen wird, unterschiedlich ist. Folgende Grafik soll das verdeutlichen (d steht für die Tiefe der Teilbäume):

Die heapify()-Methode wird also maximal für n/4 Bäume der Tiefe 1 aufgerufen, für n/8 Bäume der Tiefe 2, für n/16 Bäume der Tiefe 3, usw.
Die maximale Anzahl der Tauschoperationen in der heapify()-Methode entspricht der Tiefe des Teilbaums, auf der diese aufgerufen wird.
Die maximale Anzahl der Tauschoperationen Smax (S steht für "Swap") für den Aufbau des Heaps beträgt somit:
Smax = n/4 · 1 + n/8 · 2 + n/16 · 3 + n/32 · 4 + ...
Wenn wir beide Seiten des Terms mit 2 multiplizieren, erhalten wir:
2 · Smax = n/2 · 1 + n/4 · 2 + n/8 · 3 + n/16 · 4 + ...
Legen wir einmal beide Terme übereinander:
| 2 · Smax = | n/2 · 1 + | n/4 · 2 + n/8 · 3 + n/16 · 4 + ... |
| Smax = | n/4 · 1 + n/8 · 2 + n/16 · 3 + n/32 · 4 + ... |
Beide Terme enthalten n/4, n/8, n/16 usw. mit jeweils einem um die Konstante 1 unterschiedlichen Faktor. Wenn wir die Terme subtrahieren, erhalten wir:
2 · Smax - Smax = n/2 · 1 + n/4 · (2 - 1) + n/8 · (3 - 2) + n/16 · (4 - 3) + ...
Das lässt sich vereinfachen zu:
Smax = n/2 + n/4 + n/8 + n/16 + ...
Bzw:
Smax = n · (1/2 + 1/4 + 1/8 + 1/16 + ...)
Der Term 1/2 + 1/4 + 1/8 + 1/16 + ... nähert sich an 1 an, wie folgende Darstellung zeigt:

Somit lässt sich die Formel abschließend vereinfachen auf:
Smax ≤ n
Damit haben wir gezeigt, dass der Aufwand für den Aufbau des Heaps linear ist, die Zeitkomplexität also O(n) beträgt.
Die oben genannte Gesamtkomplexität von O(n log n) ändert sich durch die niedrigere Komplexitätsklasse eines Teilalgorithmus nicht.
Laufzeit des Java Heapsort Beispiels
Mit der Klasse UltimateSort kann die Laufzeit verschiedener Sortieralgorithmen für unterschiedliche Eingabegrößen ermittelt werden.
Die folgende Tabelle zeigt die Mediane der Laufzeiten für das Sortieren von zufällig angeordneten, sowie aufsteigend und absteigend vorsortierten Elementen, nach 50 Wiederholungen (dies ist der Übersicht halber nur ein Auszug; das vollständige Ergebnis findest du hier):
| n | unsortiert | aufsteigend | absteigend |
|---|---|---|---|
| ... | ... | ... | ... |
| 2.097.152 | 369,5 ms | 198,8 ms | 198,8 ms |
| 4.194.304 | 870,2 ms | 410,4 ms | 412,7 ms |
| 8.388.608 | 2.052,4 ms | 848,9 ms | 852,9 ms |
| 16.777.216 | 4.686,9 ms | 1.752,6 ms | 1.775,3 ms |
| 33.554.432 | 10.508,2 ms | 3.623,5 ms | 3.668,7 ms |
| 67.108.864 | 23.459,9 ms | 7.492.4 ms | 7.605,5 ms |
Hier die vollständigen Messwerte als Diagramm:

Es lässt sich gut sehen:
- Bei Verdopplung der Eingabemenge dauert das Sortieren etwas mehr als doppelt so lange; dies entspricht der erwarteten quasi-linearen Laufzeit O(n log n).
- Für vorsortierte Eingabedaten ist Heapsort etwa drei mal so schnell wie für unsortierte.
- Aufsteigend sortierte Eingabedaten werden etwa gleich schnell sortiert wie absteigend sortierte.
Warum ist Heapsort für vorsortierte Eingabedaten schneller?
Um dieser Frage auf den Grund zu gehen, verwende ich das Programm CountOperations, um die Anzahl von Vergleichs-, Lese- und Schreiboperationen von Heapsort für unsortierte, aufsteigend und absteigend sortierte Daten, für die jeweiligen Phasen, zu messen.
Das Ergebnis findest du in der Datei CountOperations_Heapsort.log. Die Erkenntnisse aus dem Test sind:
- Wenn die Eingabedaten absteigend sortiert sind, gibt es in Phase 1 nur etwa halb so viele Vergleiche wie bei unsortierten oder aufsteigend sortierten Daten; außerdem gibt es keine Tauschoperationen. Dies liegt daran, dass ein absteigend sortiertes Array bereits einem Max Heap entspricht.
- Aufsteigend sortierte Eingabedaten hingegeben entsprechen einem Min Heap. Dieser muss in der
buildHeap()-Phase komplett umgedreht werden, deshalb haben wir in diesem Fall etwa ein Drittel mehr Tauschoperationen als bei zufällig angeordneten Daten, in denen die Heap-Bedingung bereits an einigen Teilbäumen erfüllt ist. - In Phase 2 unterscheidet sich die Anzahl der Operationen nur minimal.
Wie lässt sich dann erklären, dass Heapsort sowohl für aufsteigend als auch für absteigend vorsortierte Eingabedaten etwa drei mal so schnell ist?
Die Antwort finden wir in der sogenannten Sprungvorhersage (englisch "branch prediction").
Bei vorsortierten Eingabedaten führen die Vergleichsoperationen immer wieder zum selben Ergebnis. Wenn die Sprungvorhersage nun davon ausgeht, dass die Vergleiche auch in Zukunft zum selben Ergebnis führen, können die Befehls-Pipelines der CPU voll ausgenutzt werden.
Bei unsortierten Eingabedaten hingegen kann keine zuverlässige Aussage über zukünftige Vergleichsergebnisse getroffen werden. Entsprechend muss die Befehls-Pipeline häufig gelöscht und wieder neu gefüllt werden.
Bottom-Up-Heapsort
Bottom-Up-Heapsort ist eine Variante, bei die heapify()-Methode durch geschickte Optimierung mit weniger Vergleichen auskommt. Dies ist vorteilhaft, wenn nicht beispielsweise int-Primitive verglichen werden, sondern Objekte mit einer aufwändigen compareTo()-Funktion.
Im regulären heapify() führen wir von oben nach unten an jedem Knoten zwei Vergleiche aus, um das größte von drei Elementen zu finden:
- Elternknoten mit linkem Kind
- Der größere Knoten aus dem ersten Vergleich mit dem zweiten Kind
Bottom-Up-Heapsort Algorithmus
Bottom-Up-Heapsort hingegen vergleicht nur die zwei Kinder miteinander und folgt dem jeweils größeren Kind bis zum Ende des Baumes ("top-down"). Von dort geht der Algorithmus wieder zurück Richtung Baumwurzel ("bottom-up") und sucht das erste Element, das größer als die Wurzel ist. Von hier ab werden alle Elemente jeweils um eine Position Richtung Wurzel verschoben, und das Wurzelelement wird auf das freigewordene Feld gesetzt.
Das folgendes Beispiel soll das Verständnis erleichern.
Bottom-Up-Heapsort Beispiel
In folgendem Beispiel werden die 9 und 4 verglichen, dann die Kinder der 9 – die 8 und die 6, und zuletzt die Kinder der 8 – die 7 und die 3:

Wir erreichen auf diese Weise die 7 und vergleichen diese mit der Baumwurzel, der 5:

Die 5 ist kleiner als die 7. Das bedeutet, dass das Wurzelelement bis ganz nach unten durchgereicht werden muss:

Im Endeffekt führt dies zum gleichen Ergebnis wie das reguläre heapify().
Bottom-Up-Heapsort macht sich zunutze, dass das Wurzelelement in der Regel sehr weit nach unten geschoben wird, da dieses nach jeder Iteration vom Ende des Baumes kommt und daher relativ klein ist.
Somit sind weniger Vergleiche nötig, wenn einmal bis ganz nach unten verglichen wird und dann wieder ein kurzes Stück nach oben, als wenn von oben bis nach ganz unten jeweils zwei Vergleiche durchgeführt werden:

Bottom-Up-Heapsort Quellcode
Die Klasse BottomUpHeapsort erbt von Heapsort und überschreibt lediglich deren heapify()-Methode mit der folgenden:
@Override
void heapify(int[] heap, int length, int rootPos) {
int leafPos = findLeaf(heap, length, rootPos);
int nodePos = findTargetNodeBottomUp(heap, rootPos, leafPos);
if (rootPos == nodePos) return;
// Move all elements starting at nodePos to parent, move root to nodePos
int nodeValue = heap[nodePos];
heap[nodePos] = heap[rootPos];
while (nodePos > rootPos) {
int parentPos = getParentPos(nodePos);
int parentValue = heap[parentPos];
heap[parentPos] = nodeValue;
nodePos = getParentPos(nodePos);
nodeValue = parentValue;
}
}Code-Sprache: Java (java)Die findLeaf()-Methode vergleicht jeweils zwei Kinder und folgt dem jeweils größeren, bis das Ende des Baumes erreicht ist (bzw. ein Knoten, der nur noch ein Kind enthält):
int findLeaf(int[] heap, int length, int rootPos) {
int pos = rootPos;
int leftChildPos = pos * 2 + 1;
int rightChildPos = pos * 2 + 2;
// Two child exist?
while (rightChildPos < length) {
if (heap[rightChildPos] > heap[leftChildPos]) {
pos = rightChildPos;
} else {
pos = leftChildPos;
}
leftChildPos = pos * 2 + 1;
rightChildPos = pos * 2 + 2;
}
// One child exist?
if (leftChildPos < length) {
pos = leftChildPos;
}
return pos;
}Code-Sprache: Java (java)Die Methode findTargetNodeBottomUp() sucht von unten nach oben das erste Element, das nicht kleiner als der Wurzelknoten ist:
int findTargetNodeBottomUp(int[] heap, int rootPos, int leafPos) {
int parent = heap[rootPos];
while (leafPos != rootPos && heap[leafPos] < parent) {
leafPos = getParentPos(leafPos);
}
return leafPos;
}Code-Sprache: Java (java)Und zuletzt die getParentPos()-Methode:
int getParentPos(int pos) {
return (pos - 1) / 2;
}Code-Sprache: Java (java)Bottom-Up-Heapsort Performance
Die Performance von Bottom-Up-Heapsort kann ebenfalls mit dem UltimateTest gemessen werden. Die Messwerte findest Du in ebenfalls in UltimateTest_Heapsort.log. Das folgende Diagramm zeigt die Laufzeiten von Bottom-Up-Heapsort im Vergleich mit dem regulären Heapsort:

Wie man sieht benötigt Bottom-Up-Heapsort für unsortierte Daten bis zu doppelt so lange wie das reguläre Heapsort, während es bei sortierten Daten in etwa gleich schnell ist.
Bevor wir der Ursache dafür auf den Grund gehen, schauen wir uns zunächst einen kleineren Ausschnitt des Diagramms an:

Bottom-Up-Heapsort wird also erst ab etwa zwei Millionen Elementen langsamer als das reguläre Heapsort.
Worin liegt die Ursache?
Das Ergebnis des oben erwähnten CountOperations-Programms zeigt, dass Bottom-Up-Heapsort weniger Vergleichs-, Lese und Schreiboperationen benötigt als das reguläre Heapsort – und zwar unabhängig von der Anzahl der zu sortierenden Elemente.
Warum ist es dennoch langsamer?
Bottom-up-Heapsort basiert auf der Annahme, dass das Wurzelelement immer bis zur Blattebene verschoben wird. Diese Annahme kann sich auch die Sprungvorhersage der CPU zunutze machen und damit diesen Vorteil relativieren.
Des weiteren müssen wir bei Bottom-Up-Heapsort zweimal durch den Baum gehen: einmal von oben nach unten und einmal zurück nach oben. Dies wirkt sich zwar nicht negativ auf die Anzahl der Operation aus, wohl aber auf den Zugriff auf den Hauptspeicher!
Denn während beim einmaligen Traversieren des Baumes Speicherseiten nur einmal vom Hauptspeicher in den CPU-Cache geladen werden müssen, sind bei entsprechend großen Bäumen auf dem Rückweg die meisten Speicherseiten bereits wieder aus dem Cache entfernt und müssen erneut gelesen werden.
Daher nähern wir uns bei hinreichend großen Bäumen an den Geschwindigkeitsfaktor zwei an.
Bottom-Up-Heapsort mit teuren Vergleichsoperationen
Bottom-Up-Heapsort optimiert dahingehend, dass weniger Vergleiche ausgeführt werden müssen. Bei int-Primitiven fallen Vergleiche nicht ins Gewicht, daher kann Bottom-Up-Heapsort hier seine Vorteile nicht ausspielen.
Ich habe daher einen weiteren Test ausgeführt, indem ich die Vergleichsoperationen künstlich verteuert habe. Du findest die angepassten Algorithmen in den Klassen HeapsortSlowComparisons und BottomUpHeapsortSlowComparisons im GitHub-Repository.
Bottom-Up-Heapsort schneidet bei diesem Vergleich deutlich besser ab:

Weitere Eigenschaften von Heapsort
Im folgenden werden die Platzkomplexität von Heapsort, dessen Stabilität und Parallelisierbarkeit betrachtet.
Platzkomplexität von Heapsort
Heapsort ist ein In-Place-Sortierverfahren, d. h. außer für Schleifen- und Hilfsvariablen wird kein zusätzlicher Speicherplatz benötigt. Die Anzahl dieser Variablen ist immer gleich, egal ob wir zehn Elemente sortieren oder zehn Millionen. Daher gilt:
Die Platzkomplexität von Heapsort ist: O(1)
Stabilität von Heapsort
Es lassen sich sehr leicht Beispiele konstruieren, die zeigen, dass Elemente mit gleichem Key ihre Position zueinander ändern können:
Beispiel 1
Wenn wir das Array [3, 2a, 2b, 1] mit Heapsort sortieren, sehen die Schritte wie folgt aus (2a und 2b stellen zwei Elemente mit demselben Key dar; hellgelb markiert sind die Elemente, die im nächsten Schritt vertauscht werden; blau markiert sind fertig sortierte Elemente):

An dieser Stelle können wir abbrechen, denn wir sehen bereits jetzt, dass das Ziel-Array auf [2a, 3] enden wird, d. h. die 2a wird rechts neben der 2b im Ziel-Array landen.
Algorithmus anpassen?
Im zweiten Schritt haben wir entsprechend des Algorithmus die 1 mit der 2a vertauscht. Könnten wir den Algorithmus so ändern, dass bei Kindknoten mit gleichem Key, nicht mit dem linken Kind getauscht wird, sondern mit dem rechten?
In dem Fall würde das Array oben stabil sortiert werden, da die 1 nicht mit der 2a, sondern mit der 2b getauscht werden würde, und daraufhin die 2b an der vorletzte Stelle des Arrays landen würde.
Beispiel 2
Versuchen wir das einmal mit einem anderen Eingabearray, mit [4, 3, 2a, 2b, 1]:

Nach Schritt 2 wurde der Stand erreicht, den wir zuvor als Ausgangsarray hatten, wobei jedoch 2a und 2b ihre Positionen getauscht haben. Wenn wir im nächsten Schritt die 1 nun mit dem rechten Kind tauschen, passiert das gleiche wie oben: die 2a landet zuerst im Ziel-Array und damit rechts von der 2b.
Wir haben für beide Algorithmus-Varianten Gegenbeispiele gezeigt und können daher feststellen:
Heapsort ist kein stabiles Sortierverfahren.
Parallelisierbarkeit von Heapsort
Bei Heapsort wird das gesamte Array ständig verändert, so dass es keine naheliegenden Lösungen gibt den Algororithmus zu parallelisieren.
Vergleich von Heapsort mit anderen effizienten Sortierverfahren
Im folgenden Diagramm siehst du die Ergebnisse des UltimateTests von Heapsort im Vergleich zu den Messwerten von Quicksort und Mergesort (im englischen in der Regel "Merge Sort") aus den jeweiligen Artikeln:
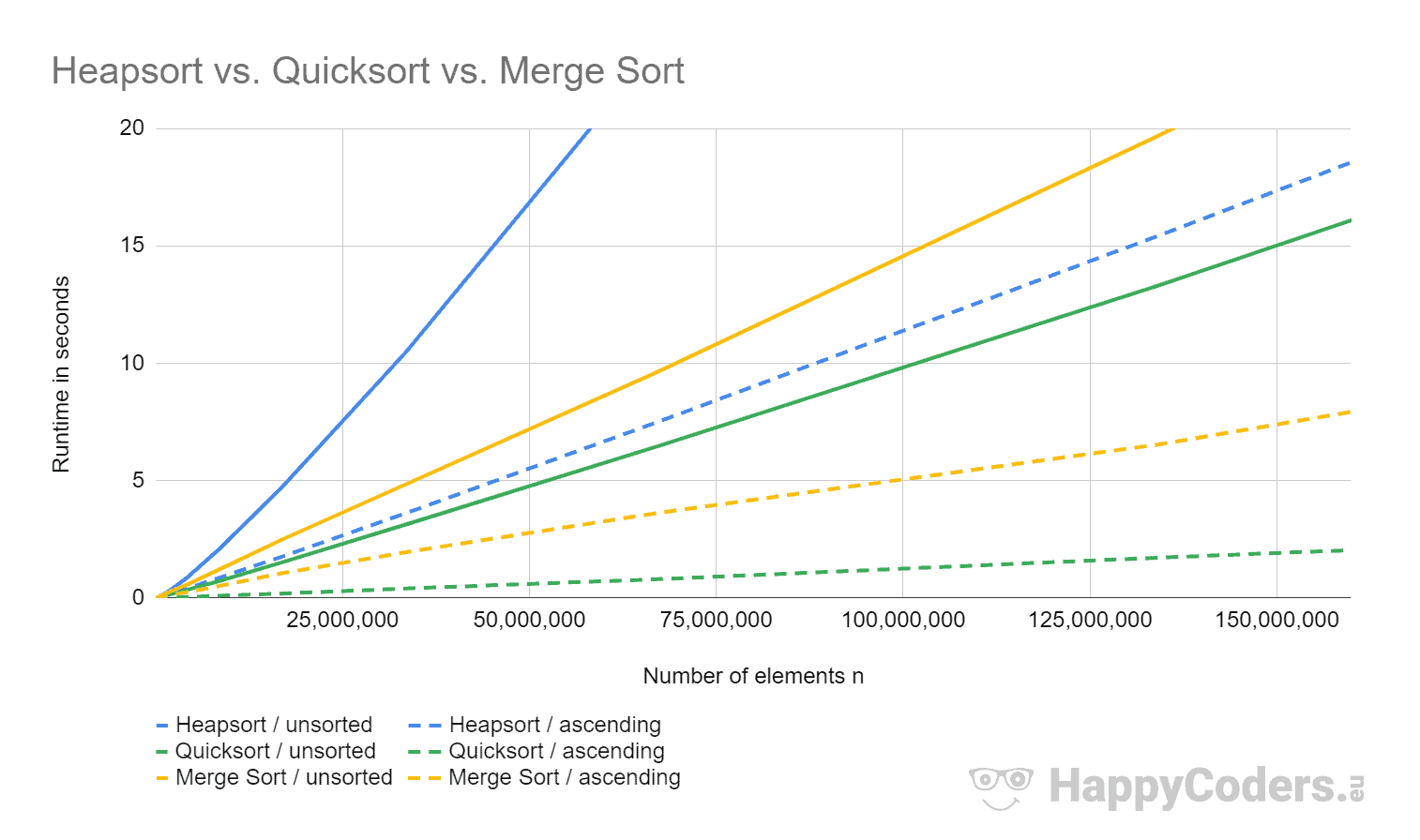
Heapsort ist bei zufällig verteilten Eingabedaten um Faktor 3,6 langsamer als Quicksort und um Faktor 2,4 langsamer als Merge Sort. Bei sortierten Daten ist Heapsort um Faktor 8 bis 9 langsamer als Quicksort und um Faktor 2 langsamer als Merge Sort.
Heapsort vs. Quicksort
Wie im vorangegangenen Abschnitt gezeigt, ist Quicksort in der Regel deutlich schneller als Heapsort.
Aufgrund der worst-case Zeitkomplexität bei Quicksort von O(n²) wird in der Praxis in manchen Fällen Heapsort gegenüber Quicksort vorgezogen.
Wie im Artikel über Quicksort gezeigt, ist bei geeigneter Wahl des Pivot-Elements der Eintritt des worst cases unwahrscheinlich. Dennoch besteht ein gewisses Risiko, welches ein potentieller Angreifer mit ausreichend Kenntnis der verwendeten Quicksort-Implementierung ausnutzen kann, um eine Anwendung mit entsprechend präparierten Eingabedaten in die Knie zu zwingen.
Heapsort vs. Mergesort
Auch Mergesort ist in der Regel schneller als Heapsort. Außerdem ist Mergesort im Gegensatz zu Heapsort stabil.
Heapsort hat gegenüber Mergesort den Vorteil, dass es keinen zusätzlichen Speicherbedarf hat, während Mergesort zusätzlichen Speicher in der Größenordnung O(n) benötigt.
Zusammenfassung
Heapsort ist ein effizienter, nicht stabiler Sortieralgorithmus mit einer Zeitkomplexität von O(n log n) im average, best und worst case.
Heapsort ist deutlich langsamer als Quicksort und Mergesort, weshalb man Heapsort in der Praxis seltener antrifft.
Weitere Sortieralgorithmen findest du in der Übersicht aller Sortieralgorithmen und ihrer Eigenschaften im ersten Teil der Artikelserie.