


Java 23 Features
(mit Beispielen)
Java 23 wurde am 17. September 2024 veröffentlicht. Du kannst es hier herunterladen.
Die Highlights von Java 23:
- Markdown Documentation Comments: Endlich dürfen wir JavaDoc auch mit Markdown schreiben.
- Importiere ganze Module mit Module Import Declarations.
- Matche Variablen jetzt auch gegen primitive Typen mit Primitive Types in Patterns, instanceof, and switch (Preview).
print(),println()undreadln(): Ein- und Ausgaben ohneSystem.inundSystem.outmit Implicitly Declared Classes and Instance Main Methods.- Benutze Flexible Constructor Bodies, um in Konstruktoren schon vor dem Aufruf von
super(...)Felder zu initialisieren.
Darüber hinaus gehen viele weitere in Java 21 und Java 22 eingeführte Features ohne bzw. mit kleinen Änderungen in eine neue Preview-Runde.
Eine Ausnahme machen die in Java 21 vorgestellten und in Java 22 wiedervorgelegten String Templates: Diese sind in Java 23 nicht mehr enthalten. Laut Gavin Bierman besteht zwar Einigkeit darüber, dass das Design überarbeitet werden muss, jedoch herrscht Uneinigkeit darüber, wie dies konkret geschehen soll. Die Sprachentwickler haben daher beschlossen, sich mehr Zeit für die Überarbeitung des Designs zu nehmen und das Feature in einer späteren Java-Version rundum überarbeitet vorzustellen.
Für alle JEPs und sonstigen Änderungen verwende ich wie immer die originalen, englischen Bezeichnungen.
Markdown Documentation Comments – JEP 467
Um JavaDoc-Kommentare zu formatieren, mussten wir seit jeher HTML verwenden. Das war 1995 sicher eine gute Wahl – heutzutage ist jedoch für das Schreiben von Dokumentation Markdown wesentlich beliebter als HTML.
JDK Enhancement Proposal 467 macht es möglich, dass wir ab Java 23 JavaDoc-Kommentare zukünftig in Markdown schreiben können.
Das folgende Beispiel zeigt die Dokumentation der Math.ceilMod(...)-Methode in der herkömmlichen Schreibweise:
/**
* Returns the ceiling modulus of the {@code long} and {@code int} arguments.
* <p>
* The ceiling modulus is {@code r = x - (ceilDiv(x, y) * y)},
* has the opposite sign as the divisor {@code y} or is zero, and
* is in the range of {@code -abs(y) < r < +abs(y)}.
*
* <p>
* The relationship between {@code ceilDiv} and {@code ceilMod} is such that:
* <ul>
* <li>{@code ceilDiv(x, y) * y + ceilMod(x, y) == x}</li>
* </ul>
* <p>
* For examples, see {@link #ceilMod(int, int)}.
*
* @param x the dividend
* @param y the divisor
* @return the ceiling modulus {@code x - (ceilDiv(x, y) * y)}
* @throws ArithmeticException if the divisor {@code y} is zero
* @see #ceilDiv(long, int)
* @since 18
*/Code-Sprache: Java (java)Das Beispiel enthält formatierten Code, Absatzmarken, eine Aufzählung, einen Link und JavaDoc-spezifische Angaben wie @param und @return.
Um Markdown zu verwenden, müssen wir alle Zeilen eines JavaDoc-Kommentars mit drei Schrägstrichen beginnen lassen. Derselbe Kommentar als Markdown würde wie folgt aussehen:
/// Returns the ceiling modulus of the `long` and `int` arguments.
///
/// The ceiling modulus is `r = x - (ceilDiv(x, y) * y)`,
/// has the opposite sign as the divisor `y` or is zero, and
/// is in the range of `-abs(y) < r < +abs(y)`.
///
/// The relationship between `ceilDiv` and `ceilMod` is such that:
///
/// - `ceilDiv(x, y) * y + ceilMod(x, y) == x`
///
/// For examples, see [#ceilMod(int, int)].
///
/// @param x the dividend
/// @param y the divisor
/// @return the ceiling modulus `x - (ceilDiv(x, y) * y)`
/// @throws ArithmeticException if the divisor `y` is zero
/// @see #ceilDiv(long, int)
/// @since 18Code-Sprache: Java (java)Das ist sowohl einfacher zu schreiben als auch besser zu lesen.
Was hat sich im Einzelnen verändert?
- Statt mit
{@code ... }wird Quellcode mit`...`markiert. - Das HTML-Absatzzeichen
<p>kann durch eine Leerzeile ersetzt werden. - Die Elemente der Aufzählung werden durch Bindestriche eingeleitet.
- Statt mit
{@link ... }werden Links mit[...]markiert. - Die JavaDoc-spezifische Angaben wie
@paramund@returnbleiben unverändert.
Die folgenden Text-Formatierungen werden unterstützt:
/// **This text is bold.**
/// *This text is italic.*
/// _This is also italic._
/// `This is source code.`
///
/// ```
/// This is a block of source codex.
/// ```
///
/// Indented text
/// is also rendered as a code block.
///
/// ~~~
/// This is also a block of source code
/// ~~~Code-Sprache: Java (java)Aufzählungslisten und nummerierte Listen werden unterstützt:
/// This is a bulleted list:
/// - One
/// - Two
/// - Three
///
/// This is a numbered list:
/// 1. One
/// 1. Two
/// 1. ThreeCode-Sprache: Java (java)Auch einfache Tabellen können dargestellt werden:
/// | Binary | Decimal |
/// |--------|---------|
/// | 00 | 0 |
/// | 01 | 1 |
/// | 10 | 2 |
/// | 11 | 3 |Code-Sprache: Java (java)Links zu anderen Programmelementen können wie folgt eingebaut werden:
/// Links:
/// - ein Modul: [java.base/]
/// - ein Paket: [java.lang]
/// - eine Klasse: [Integer]
/// - ein Feld: [Integer#MAX_VALUE]
/// - eine Methode: [Integer#parseInt(String, int)]Code-Sprache: Java (java)Sollen sich Link-Text und Link-Ziel unterscheiden, kann der Link-Text in eckigen Klammern vorangestellt werden:
/// Links:
/// - [ein Modul][java.base/]
/// - [ein Paket][java.lang]
/// - [eine Klasse][Integer]
/// - [ein Feld][Integer#MAX_VALUE]
/// - [eine Methode][Integer#parseInt(String)]Code-Sprache: Java (java)Und zu guter Letzt: JavaDoc-Tags wie @param, @throws etc. werden nicht ausgewertet, wenn sie innerhalb von Code oder Code-Blöcken verwendet werden.
Neue Preview-Features in Java 23
Java 23 bringt uns zwei neue Preview-Features. Diese solltest du nicht in Produktivcode einsetzen, da sie sich noch ändern können (oder, wie im Fall von String Templates, auch kurzfristig wieder entfernt werden können).
Du musst Preview-Features sowohl im javac-Kommando explizit über die VM-Optionen --enable-preview --source 23 freischalten. Für das java-Kommando genügt --enable-preview.
Module Import Declarations (Preview) – JEP 476
Schon seit Java 1.0 werden in jeder .java-Datei automatisch alle Klassen des Pakets java.lang importert. Deshalb können wir Klassen wie Object, String, Integer, Exception, Thread, usw. ohne import-Statements verwenden.
Ebenso konnten wir schon immer komplette Pakete importieren. So führt z. B. import java.util.* dazu, dass wir Klassen wie List, Set, Map, ArrayList, HashSet und HashMap nicht einzeln importieren müssen.
JDK Enhancement Proposal 476 macht es nun möglich, dass wir auch komplette Module importieren können. Genauer gesagt: alle Klassen in den vom Modul exportierten Paketen.
So können wir z. B. wie folgt das komplette java.base-Modul importieren und Klassen dieses Moduls (im Beispiel List, Map, Collectors, Stream) ohne weitere Imports nutzen:
import module java.base;
public static Map<Character, List<String>> groupByFirstLetter(String... values) {
return Stream.of(values).collect(
Collectors.groupingBy(s -> Character.toUpperCase(s.charAt(0))));
}Code-Sprache: Java (java)Um import module zu verwenden ist es nicht nötig, dass sich die importierende Klasse selbst in einem Modul befindet.
Mehrdeutige Klassennamen
Wenn es zwei importierte Klassen mit gleichem Namen gibt, wie Date im folgenden Beispiel, kommt es zu einem Compiler-Fehler:
import module java.base;
import module java.sql;
. . .
Date date = new Date(); // Compiler error: "reference to Date is ambiguous"
. . .Code-Sprache: Java (java)Die Lösung ist einfach: Wir müssen die gewünschte Date-Klasse zusätzlich direkt importieren:
import module java.base;
import module java.sql;
import java.util.Date; // ⟵ This resolves the ambiguity
. . .
Date date = new Date();
. . .Code-Sprache: Java (java)Transitive Imports
Wenn ein importiertes Modul ein anderes Modul transitiv importiert, dann sind auch alle Klassen der exportierten Pakete des transitiv importierten Moduls ohne explizite Imports nutzbar.
Beispielsweise importiert das Modul java.sql das Module java.xml transitiv:
module java.sql {
. . .
requires transitive java.xml;
. . .
}Code-Sprache: Java (java)Somit benötigen wir im folgenden Beispiel keine expliziten Imports für SAXParserFactory und SAXParser und auch keinen expliziten Import des Moduls java.xml:
import module java.sql;
. . .
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
. . .Code-Sprache: Java (java)Automatischer Modul-Import in JShell
JShell importiert automatisch zehn häufig genutzte Pakete. Durch diesen JEP wird JShell in Zukunft das komplette java.base-Modul importieren.
Das lässt sich sehr schön demonstrieren, indem man JShell einmal ohne und einmal mit --enable-preview aufruft und dann das Kommando /imports eingibt:
$ jshell
| Welcome to JShell -- Version 23-ea
| For an introduction type: /help intro
jshell> /imports
| import java.io.*
| import java.math.*
| import java.net.*
| import java.nio.file.*
| import java.util.*
| import java.util.concurrent.*
| import java.util.function.*
| import java.util.prefs.*
| import java.util.regex.*
| import java.util.stream.*
jshell> /exit
| Goodbye
$ jshell --enable-preview
| Welcome to JShell -- Version 23-ea
| For an introduction type: /help intro
jshell> /imports
| import java.baseCode-Sprache: Klartext (plaintext)Beim Aufruf ohne --enable-preview sieht du die zehn importieren Pakete, beim Aufruf mit --enable-preview siehst du nur den Import des java.base-Moduls.
Automatischer Modul-Import in implizit deklarierten Klassen
Implizit deklarierte Klassen importieren ab Java 23 ebenfalls automatisch das komplette java.base-Modul.
Primitive Types in Patterns, instanceof, and switch (Preview) – JEP 455
Mit instanceof und switch können wir überprüfen, ob ein Objekt von einem bestimmten Typ ist, und wenn ja, dieses Objekt an eine Variable dieses Typs binden, einen bestimmten Programmpfad ausführen und in diesem Programmpfad die neue Variable benutzen.
Der folgende, seit Java 16 erlaubte Codeblock z. B. prüft, ob ein Objekt ein mindestens fünf Zeichen langer String ist, und wenn ja, gibt er diesen in Großbuchstaben aus. Wenn das Objekt ein Integer ist, wird die Zahl quadriert und ausgegeben. Andernfalls wird das Objekt ausgegeben, wie es ist.
if (obj instanceof String s && s.length() >= 5) {
System.out.println(s.toUpperCase());
} else if (obj instanceof Integer i) {
System.out.println(i * i);
} else {
System.out.println(obj);
}Code-Sprache: Java (java)Das gleiche können wir seit Java 21 deutlich übersichtlicher mit switch machen:
switch (obj) {
case String s when s.length() >= 5 -> System.out.println(s.toUpperCase());
case Integer i -> System.out.println(i * i);
case null, default -> System.out.println(obj);
}Code-Sprache: Java (java)Das funktioniert bisher aber nur mit Objekten. instanceof kann bisher gar nicht mit primitiven Datentypen kombiniert werden, switch nur insoweit, dass es Variablen der primitiven Typen byte, short, char und int gegen Konstanten matchen kann, z. B. so:
int x = ...
switch (x) {
case 1, 2, 3 -> System.out.println("Low");
case 4, 5, 6 -> System.out.println("Medium");
case 7, 8, 9 -> System.out.println("High");
}Code-Sprache: Java (java)Durch JDK Enhancement Proposal 455 gibt es in Java 23 zwei Änderungen:
- Zum einen dürfen in
switch-Ausdrücken und -Anweisungen ab sofort alle primitiven Typen verwendet werden, also auchlong,float,doubleundboolean. - Zum anderen können wir auch alle primitiven Typen im Pattern Matching verwenden – sowohl bei
instanceofals auch beiswitch.
In beiden Fällen, also bei switch über long, float, double und boolean sowie beim Pattern Matching mit primitiven Variablen, muss der switch – genauso wie bei allen neuen switch-Features – erschöpfend sein, also alle möglichen Fälle abdecken.
Ab Java 23: Primitive Typen im Pattern Matching
Bei primitiven Pattern ist die genaue Bedeutung eine andere als bei der Verwendung von Objekten – denn bei primitiven Typen gibt es ja keine Vererbung:
Sei a eine Variable eines primitiven Typen (also byte, short, int, long, float, double, char oder boolean) und B einer eben dieser primitiven Typen. Dann ergibt a instanceof B genau dann true, wenn der präzise Wert von a auch in einer Variablen vom Typ B gespeichert werden kann.
Damit du besser verstehst, was damit gemeint ist, hier ein einfaches Beispiel:
int a = ...
if (a instanceof byte b) {
System.out.println("b = " + b);
}Code-Sprache: Java (java)Der Code ist wie folgt zu lesen: Wenn der Wert der Variablen a auch in einer byte-Variablen gespeichert werden kann, dann weise der byte-Variablen b diesen Wert zu und gebe diesen aus.
Für a = 5 wäre das z. B. der Fall, für a = 1000 hingegen nicht, da byte lediglich Werte von -128 bis 127 speichern kann.
Genau wie bei Objekten darfst du auch bei primitiven Typen direkt im instanceof-Check mit && weitere Prüfungen anschließen. Der folgende Code z. B. gibt nur positive byte-Werte (also 1 bis 127) aus:
int a = ...
if (a instanceof byte b && b > 0) {
System.out.println("b = " + b);
}Code-Sprache: Java (java)Zahlreiche weitere Beispiele und Besonderheiten findest du im Hauptartikel Primitive Typen in Patterns, instanceof und switch.
Primitive Typ-Pattern mit switch
Wir können primitive Pattern nicht nur in instanceof einsetzen, sondern auch in switch:
double value = ...
switch (value) {
case byte b -> System.out.println(value + " instanceof byte: " + b);
case short s -> System.out.println(value + " instanceof short: " + s);
case char c -> System.out.println(value + " instanceof char: " + c);
case int i -> System.out.println(value + " instanceof int: " + i);
case long l -> System.out.println(value + " instanceof long: " + l);
case float f -> System.out.println(value + " instanceof float: " + f);
case double d -> System.out.println(value + " instanceof double: " + d);
}Code-Sprache: Java (java)Hier müssen wir – genau wie bei Objekttypen – das Prinzip der dominierenden und dominierten Typen sowie die Vollständigkeitsprüfung beachten. Was das genau bedeutet erfährst du im Hauptartikel Primitive Typen in Patterns, instanceof und switch.
Wiedervorgelegte Preview und Incubator-Features
Sieben Preview- und Incubator-Features werden in Java 23 wiedervorgelegt, drei davon ohne Änderungen gegenüber Java 22:
Stream Gatherers (Second Preview) – JEP 473
Seit der Einführung der Stream API in Java 8 klagte die Java-Community über den eingeschränkten Umfang an intermediären Stream-Operationen. Operationen wie beispielsweise „window” oder „fold” wurden schmerzlich vermisst und immer wieder angefordert.
Anstatt sich dem Druck der Community zu beugen und diese Funktionen bereitzustellen, hatten die JDK-Entwickler eine bessere Idee: Sie implementierten eine API, mit der sie selbst und auch alle anderen Java Developer selbst intermediäre Stream-Operationen implementieren können.
Diese neue API nennt sich „Stream Gatherers”. Sie wurde erstmals in Java 22 durch JDK Enhancement Proposal 461 vorgestellt und in Java 23 durch JDK Enhancement Proposal 473 unverändert ein zweites Mal als Preview vorgelegt, um weiteres Feedback von der Community einzusammeln.
Mit dem folgenden Code könnten wir z. B. die intermediäre Stream-Operation „map” als Stream Gatherer implementieren und einsetzen:
public <T, R> Gatherer<T, Void, R> mapping(Function<T, R> mapper) {
return Gatherer.of(
Integrator.ofGreedy(
(state, element, downstream) -> {
R mappedElement = mapper.apply(element);
return downstream.push(mappedElement);
}));
}
public List<Integer> toLengths(List<String> words) {
return words.stream()
.gather(mapping(String::length))
.toList();
}
Code-Sprache: Java (java)Wie genau Stream Gatherers funktionieren, welche Einschränkungen es dabei gibt und ob wir endlich die lang ersehnten „window”- und „fold”-Operationen bekommen, erfährst du im Hauptartikel über Stream Gatherer.
Implicitly Declared Classes and Instance Main Methods (Third Preview) – JEP 477
Wenn Java-Entwicklerinnen und -Entwickler ihr erstes Programm schreiben, sieht das – bisher – meistens so aus:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Code-Sprache: Java (java)Java-Anfänger werden hier mit zahlreichen neuen Konzepten auf einmal konfrontiert:
- mit Klassen,
- mit dem Sichtbarkeitsmodifikator
public, - mit statischen Methoden,
- mit unbenutzten Methodenargumenten,
- mit
System.out.
Wäre es nicht schön, wenn wir das alles streichen und uns aufs Wesentliche konzentrieren könnten – so wie in folgendem Screenshot?

Genau das machen „Implicitly Declared Classes and Instance Main Methods“ möglich!
Ab Java 23 ist der folgende Code ein gültiges und vollständiges Java-Programm:
void main() {
println("Hello world!");
}Code-Sprache: Java (java)Wie wird das ermöglicht?
- Eine Klassenangabe ist nicht mehr zwingend erforderlich. Wird die Klassenangabe weggelassen, erzeugt der Compiler eine implizite Klasse.
- Eine
main()-Methode muss wederpublicnochstaticsein, noch muss sie Argumente haben. - Eine implizite Klasse importiert automatisch die neue Klasse
java.io.IO, die die statischen Methodenprint(...),println(...)undreadln(...)enthält.
Weitere Details, Beispiele, zu beachtende Einschränkungen und was bei mehreren überladenen main()-Methoden passiert, erfährst du im Hauptartikel über die Java-main()-Methode.
Die hier beschriebenen Änderungen wurden erstmals in Java 21 unter dem Namen „Unnamed Classes and Instance Main Methods“ veröffentlicht. In Java 22 wurden einige übermäßig komplizierten Aspekte des Features vereinfacht und das Feature umbenannt.
In Java 23 wurde durch JDK Enhancement Proposal 477 die automatisch importierte java.io.IO-Klasse hinzugefügt, sodass letztendlich auch System.out weggelassen werden kann, was im zweiten Preview in Java 22 noch nicht möglich war.
In Java 24 wird das Feature erneut umbenannt in „Simple Source Files and Instance Main Methods“.
Bitte bedenke, dass sich das Feature noch im Preview-Stadium befindet und mit der VM-Option --enable-preview aktiviert werden muss.
Structured Concurrency (Third Preview) – JEP 480
Structured Concurrency ist ein moderner, durch virtuelle Threads möglich gewordener Ansatz, um Aufgaben in parallel auszuführende Teilaufgaben aufzuteilen.
Structured Concurrency bietet eine klare Struktur für den Start und das Ende von parallelen Aufgaben und eine geordnete Fehlerbehandlung. Sollten die Ergebnisse bestimmter Teilaufgaben nicht mehr benötigt werden, können diese Teilaufgaben sauber abgebrochen werden.
Ein Beispiel für die Anwendung von Structured Concurrency ist die Implementierung einer race()-Methode, die zwei Aufgaben startet und das Ergebnis der zuerst beendeten Aufgabe zurückgibt, während die andere Aufgabe automatisch abgebrochen wird:
public static <R> R race(Callable<R> task1, Callable<R> task2)
throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<R>()) {
scope.fork(task1);
scope.fork(task2);
scope.join();
return scope.result();
}
}Code-Sprache: Java (java)Eine ausführlichere Beschreibung, weitere Einsatzmöglichkeiten und zahlreiche Beispiele findest du im Hauptartikel über Structured Concurrency.
Structured Concurrency wurde in Java 21 als Preview-Feature vorgestellt und in Java 22 ohne Änderungen erneut vorgelegt. Auch in Java 23, in JDK Enhancement Proposal 480, gab es keine Änderungen – die JDK-Entwickler erhoffen sich weiteres Feedback vor der Finalisierung des Features.
Scoped Values (Third Preview) – JEP 481
Scoped Values können benutzt werden, um Werte an weit entfernte Methodenaufrufe zu übergeben, ohne dass diese durch alle Methoden der Aufrufkette als Paramter hindurchgeschleift werden müssen.
Das klassische Beispiel ist der auf einem Webserver eingeloggte User, für den ein bestimmter Use Case ausgeführt werden soll. Viele der im Rahmen solch eines Use Cases aufgerufenen Methoden benötigen Zugriff auf die User-Informationen. Mit Scoped Values können wir einen Kontext aufspannen, innerhalb dessen alle Methoden auf das User-Objekt zugreifen können, ohne dass dieses als Parameter an all diese Methoden übergeben werden muss.
Aufgespannt wird so ein Kontext mit ScopedValue.where(...):
public class Server {
public final static ScopedValue<User> LOGGED_IN_USER = ScopedValue.newInstance();
. . .
private void serve(Request request) {
. . .
User loggedInUser = authenticateUser(request);
ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.run(() -> restAdapter.processRequest(request));
. . .
}
}Code-Sprache: Java (java)Nun können die innerhalb der run(...)-Methode aufgerufene Methode – sowie alle von ihr direkt oder indirekt aufgerufenen Methoden, z. B. eine tief im Call-Stack aufgerufene Repository-Methode – wie folgt auf den User zugreifen:
public class Repository {
. . .
public Data getData(UUID id) {
Data data = findById(id);
User loggedInUser = Server.LOGGED_IN_USER.get();
if (loggedInUser.isAdmin()) {
enrichDataWithAdminInfos(data);
}
return data;
}
. . .
}Code-Sprache: Java (java)Wer schon einmal mit ThreadLocal-Variablen gearbeitet hat, wird eine Ähnlichkeit erkennen. Scoped Values haben jedoch eine ganze Reihe Vorteile gegenüber ThreadLocals. Was diese Vorteile sind, erfährst du neben einer umfassenden Einführung im Hauptartikel über Scoped Values.
Scoped Values wurden gemeinsam mit Structured Concurrency in Java 21 als Preview-Feature eingeführt und in Java 22 ohne Änderungen in eine zweite Preview-Runde geschickt.
Durch JDK Enhancement Proposal 481 wurden in Java 23 die folgenden zwei statischen Methoden der ScopedValue-Klasse zu einer Methode zusammengefasst:
// Java 22:
public static <T, R> R getWhere (ScopedValue<T> key, T value, Supplier<? extends R> op)
public static <T, R> R callWhere(ScopedValue<T> key, T value, Callable<? extends R> op) Code-Sprache: Java (java)Die Methoden unterschieden sich lediglich dadurch, dass an getWhere(...) ein Supplier übergeben wird (ein funktionales Interface mit einer get()-Methode, das keine Exception deklariert) und an callWhere(...) ein Callable (ein funktionales Interface mit einer call()-Methode, die throws Exception deklariert).
Nehmen wir an, wir wollen im Kontext des Scoped Values folgende Methode aufrufen, wobei SpecificException eine checked Exception ist:
Result doSomethingSmart() throws SpecificException {
. . .
}Code-Sprache: Java (java)In Java 22 mussten wir diese Methode wie folgt aufrufen:
// Java 22:
try {
Result result = ScopedValue.callWhere(USER, loggedInUser, this::doSomethingSmart);
} catch (Exception e) { // ⟵ Catching generic Exception
. . .
}Code-Sprache: Java (java)Da Callable.call() eine generische Exception wirft, mussten wir eben auch Exception abfangen, selbst wenn die aufgerufene Methode eine spezifische Exception geworfen hat.
In Java 23 gibt es nun nur noch eine callWhere(...)-Methode:
public static <T, R, X extends Throwable> R callWhere(
ScopedValue<T> key, T value, ScopedValue.CallableOp<? extends R, X> op) throws XCode-Sprache: Java (java)Statt eines Suppliers oder eines Callables wird nun eine ScopedValue.CallableOp übergeben. Dies ist ein wie folgt definiertes funktionales Interface:
@FunctionalInterface
public static interface ScopedValue.CallableOp<T, X extends Throwable> {
T call() throws X
}Code-Sprache: Java (java)Dieses neue Interface enthält eine möglicherweise geworfene Exception als Typ-Parameter X. Somit kann der Compiler erkennen, welche Art von Exception der Aufruf von callWhere(...) werfen kann – und wir können im catch-Block direkt SpecificException behandeln:
// Java 23:
try {
Result result = ScopedValue.callWhere(USER, loggedInUser, () -> doSomethingSmart());
} catch (SpecificException e) { // ⟵ Catching SpecificException
. . .
}Code-Sprache: Java (java)Und wenn doSomethingSmart() keine Exception oder eine RuntimeException wirft, können wir den catch-Block weglassen:
// Java 23:
Result result = callWhere(USER, loggedInUser, this::doSomethingSmart);Code-Sprache: Java (java)Diese Änderung in Java 23 macht den Code ausdrucksstärker und weniger fehleranfällig.
Flexible Constructor Bodies (Second Preview) – JEP 482
Nehmen wir mal an, du hast eine Klasse, wie die folgende:
public class ConstructorTestParent {
private final int a;
public ConstructorTestParent(int a) {
this.a = a;
printMe();
}
void printMe() {
System.out.println("a = " + a);
}
}Code-Sprache: Java (java)Und nehmen wir an, du hast eine zweite Klasse, die diese Klasse erweitert:
public class ConstructorTestChild extends ConstructorTestParent {
private final int b;
public ConstructorTestChild(int a, int b) {
super(a);
this.b = b;
}
}Code-Sprache: Java (java)Und jetzt würdest du gerne im Konstruktur von ConstructorTestChild sicherstellen, dass a und b nicht negativ sind, bevor der Super-Konstruktor aufgerufen wird.
Eine entsprechende Prüfung vor den Konstruktor zu setzen, war bisher nicht erlaubt. Deshalb mussten wir uns mit Verrenkungen wie der folgenden aushelfen:
public class ConstructorTestChild extends ConstructorTestParent {
private final int b;
public ConstructorTestChild(int a, int b) {
super(verifyParamsAndReturnA(a, b));
this.b = b;
}
private static int verifyParamsAndReturnA(int a, int b) {
if (a < 0 || b < 0) throw new IllegalArgumentException();
return a;
}
}Code-Sprache: Java (java)Das ist weder sehr elegant noch gut lesbar.
Nehmen wir weiterhin an, du möchtest die im Konstruktor der Elternklasse aufgerufene printMe() Methode überschreiben, um zusätzlich die Felder der abgeleiteten Klasse auszugeben:
public class ConstructorTestChild extends ConstructorTestParent {
. . .
@Override
void printMe() {
super.printMe();
System.out.println("b = " + b);
}
}Code-Sprache: Java (java)Was würde diese Methode ausgeben, wenn du new ConstructorTestChild(1, 2) aufrufst?
Sie würde nicht etwa a = 1 und b = 2 ausgeben, sondern:
a = 1
b = 0Code-Sprache: Klartext (plaintext)Denn b ist zu diesem Zeitpunkt noch gar nicht initialisiert. Es wird ja erst nach dem Aufruf von super(...), also des Konstruktors, der wiederrum printMe() aufruft, initialisiert.
Beide Probleme gehören mit „Flexible Constructor Bodies” der Vergangenheit an.
Zum einen darf in Zukunft vor dem Aufruf des Super-Konstruktors mit super(...) – und auch vor dem Aufruf eines alternativen Konstruktors mit this(...) – jeglicher Code ausgeführt werden, der nicht auf die gerade konstruierte Instanz, also auch nicht auf deren Felder zugreift (dies wurde bereits in Java 22 durch JDK Enhancement Proposal 447 ermöglicht).
Zum anderen dürfen die Felder der gerade konstruierten Instanz jedoch initialisiert werden. Dies wurde in Java 23 durch JDK Enhancement Proposal 482 möglich.
Das erlaubt es nun, den Code wie folgt umzuschreiben:
public class ConstructorTestChild extends ConstructorTestParent {
private final int b;
public ConstructorTestChild(int a, int b) {
if (a < 0 || b < 0) throw new IllegalArgumentException(); // ⟵ Now allowed!
this.b = b; // ⟵ Now allowed!
super(a);
}
@Override
void printMe() {
super.printMe();
System.out.println("b = " + b);
}
}Code-Sprache: Java (java)Ein Aufruf von new ConstructorTestChild(1, 2) führt nun zur erwarteten Ausgabe:
a = 1
b = 2Code-Sprache: Klartext (plaintext)Der neue Code ist zum einen einfacher zu lesen und zum anderen sicherer, da so die Gefahr eingedämmt werden kann, dass in überschriebenen Methoden in abgeleiteten Klassen auf ein uninitialisiertes Feld zugegriffen wird.
Weitere Beispiele und einige zu beachtende Besonderheiten findest du im Hauptartikel über Flexible Constructor Bodies.
Class-File API (Second Preview) – JEP 466
Das Java Class-File API ist eine Schnittstelle zum Lesen und Schreiben von .class-Dateien, also von kompiliertem Java-Bytecode. Sie soll das im JDK weit verbreitete Bytecode-Manipulations-Framework ASM ersetzen.
Das Class-File-API wurde in Java 22 als Preview-Feature vorgestellt und in Java 23 durch JDK Enhancement Proposal 466 mit einigen Verbesserungen in eine zweite Preview-Runde geschickt.
Da vermutlich nur wenige Java-Entwicklerinnen und -Entwickler direkt mit der Class-File-API arbeiten werden, sondern in aller Regel indirekt durch andere Tools, werde ich die neue Schnittstelle hier, wie auch schon im Java-22-Artikel, nicht im Detail beschreiben.
Falls das Class-File-API für dich von Interesse ist, findest du alle Details in JDK Enhancement Proposal 466. Oder schreib einen Kommentar unter den Artikel! Sollte wider Erwarten ein hinreichendes Interesse bestehen, werde ich gerne einen Artikel über die Class-File-API schreiben.
Vector API (Eighth Incubator) – JEP 469
Dreieinhalb Jahre ist es nun her, dass die Vector API erstmals als Incubator-Feature im JDK enthalten war. Und auch in Java 23 wird sie ohne Änderungen im Incubator-Stadium verbleiben, spezifiziert durch JDK Enhancement Proposal 469.
Die Vector-API wird es ermöglichen, Vektorberechnungen wie die folgende auf spezielle Operationen moderner CPUs abzubilden. Dadurch werden solche Berechnungen extrem schnell durchgeführt werden können – bis zu einer bestimmten Vektorgröße in nur einem einzigen CPU-Zyklus!
Ich werde die Vector-API im Detail beschreiben, sobald sie das Preview-Stadium erreicht hat. Das wird vorraussichtlich dann der Fall sein, wenn auch die für die Vector-API notwendigen Funktionen von Project Valhalla im Preview-Stadium verfügbar sind (was laut Aussage der Valhalla-Entwickler seit etwa einem Jahr „bald” der Fall sein soll).
Deprecations und Löschungen
In diesem Abschnitt findest du einen Überblick über Features, die als deprecated markiert oder komplett aus dem JDK entfernt wurden.
Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal – JEP 471
Die sun.misc.Unsafe-Klasse wurde 2002 mit Java 1.4 eingeführt. Ein Großteil ihrer Methoden dient dem direkten Zugriff auf Speicher – sowohl auf den Java-Heap als auch auf nicht vom Heap kontrollierten, also nativen Speicher.
Wie der Name der Klasse schon andeutet, sind die meisten dieser Operationen unsicher, d. h. sie können zu undefiniertem Verhalten, Leistungseinbußen oder Systemabstürzen führen, wenn sie nicht korrekt eingesetzt werden.
Unsafe war ursprünglich nur für JDK-interne Zwecke gedacht – doch in Java 1.4 gab es zum einen noch kein Modulsystem, dass diese Klasse vor uns Entwicklern hätte verstecken können – und zum anderen gab es keine Alternativen, wollte man bestimmte Operationen möglichst performant implementieren (z. B. Compare-and-Swap) oder auf größere Off-Heap-Speicherblöcke als 2 GB zugreifen (das ist das Limit von ByteBuffer).
Heute jedoch existieren Alternativen:
- In Java 9 wurden VarHandles eingeführt, die direkten und optimierten Zugriff auf On-Heap-Speicher ermöglichen, dabei verschiedene Arten von Memory Barriers setzen können und auch atomare Operationen wie Compare-and-Swap bereitstellen.
- In Java 22 wurde die Foreign Function & Memory API finalisiert, eine Schnittstelle zum Aufruf von Funktionen in nativen Libraries und zur Verwaltung von nativem, also Off-Heap-Speicher.
Aufgrund der Verfügbarkeit dieser stabilen, sicheren und performanten Alternativen entschieden die JDK-Entwickler in JDK Enhancement Proposal 471, alle Unsafe-Methoden für den Zugriff auf On-Heap- und Off-Heap-Speicher in Java 23 als deprecated for removal zu kennzeichnen und in einer zukünftigen Java-Version zu entfernen.
Die Entfernung wird in vier Phasen durchgeführt:
- Phase 1: In Java 23 werden die Methoden als deprecated for removal markiert, so dass es bei deren Verwendung zu Kompilerwarnungen kommt.
- Phase 2: Vorraussichtlich in Java 25 wird die Verwendung dieser Methoden auch zu Laufzeitwarnungen führen.
- Phase 3: Vorraussichtlich in Java 26 werden die Methoden
UnsupportedOperationExceptions werfen. - Phase 4: Die Methoden werden entfernt. In welchem Release dies geschehen wird, ist noch nicht festgelegt.
Das Default-Verhalten in den jeweiligen Phasen kann durch die VM-Option --sun-misc-unsafe-memory-access überschrieben werden:
--sun-misc-unsafe-memory-access=allow– alle Unsafe-Methoden dürfen verwendet werden. Es werden zwar Kompilerwarnungen angezeigt, aber keine Warnungen zur Laufzeit ausgegeben (Standardeinstellung in Phase 1).--sun-misc-unsafe-memory-access=warn– zur Laufzeit wird eine Warnung angezeit, sobald eine der betroffenen Methoden das erste Mal aufgerufen wird (Standardeinstellung in Phase 2).--sun-misc-unsafe-memory-access=debug– zur Laufzeit wird eine Warnung und ein Stacktrace ausgegeben, wann immer eine der betroffenen Methoden aufgerufen wird.--sun-misc-unsafe-memory-access=deny– die betroffenen Methoden werfen eineUnsupportedOperationException(Standardeinstellung in Phase 3).
In den Phasen 2 und 3 kann dabei jeweils nur das Verhalten der jeweils vorherigen Phase aktiviert werden, und in Phase 4 wird diese VM-Option keinen Effekt mehr haben.
Eine vollständige Liste aller als deprecated markierten Methoden mit ihrem jeweiligen Ersatz findest du im Abschnitt sun.misc.Unsafe memory-access methods and their replacements des JEPs.
Thread.suspend/resume and ThreadGroup.suspend/resume are removed
Bereits in Java 1.2 wurden die für Deadlocks anfälligen Methoden Thread.suspend(), Thread.resume(), ThreadGroup.suspend() und ThreadGroup.resume() als deprecated markiert.
In Java 14 wurden diese Methoden dann als deprecated for removal deklariert.
Seit Java 19 werfen ThreadGroup.suspend() und resume() eine UnsupportedOperationException – und seit Java 20 auch Thread.suspend() und resume().
In Java 23 wurden all diese Methoden schließlich entfernt.
Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8320532 registriert.
ThreadGroup.stop is removed
Ebenfalls in Java 1.2 wurde ThreadGroup.stop() als deprecated markiert, da das Konzept zum Stoppen einer Thread-Gruppe von Anfang an mangelhaft implementiert war.
In Java 16 wurde die Methode als deprecated for removal deklariert.
Seit Java 19 wirft ThreadGroup.stop() eine UnsupportedOperationException.
In Java 23 wurde diese Methode schließlich entfernt.
Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8320786 registriert.
Sonstige Änderungen in Java 23
In diesem Abschnitt findest du Änderungen, mit denen die meisten Java-Entwicklerinnen und -Entwickler nicht in ihrer täglichen Arbeit konfrontiert sind. Natürlich ist es dennoch gut, über diese Änderungen Bescheid zu wissen.
ZGC: Generational Mode by Default – JEP 474
In Java 21 wurde der „Generational Mode” des Z Garbage Collectors (ZGC) eingeführt. In diesem Modus macht sich der ZGC die „schwache Generationshypothese” (englisch: „Weak Generational Hypothesis”) zu Nutze und legt neue und alte Objekte in zwei separaten Bereichen ab: der „jungen Generation” und der „alten Generation”. Die junge Generation enthält hauptsächlich kurzlebige Objekte und wird häufiger bereinigt, während die alte Generation langlebige Objekte enthält und seltener aufgeräumt werden muss.
In Java 21 musste der Generational Mode mit der VM Option -XX:+UseZGC -XX:+ZGenerational aktiviert werden.
Da der Generational Mode für die meisten Anwendungsfälle zu beachtlichen Leistungssteigerungen führt, wird der Modus in Java 23 durch JDK Enhancement Proposal 474 standardmäßig aktiviert.
D. h. durch die VM-Option -XX:+UseZGC wird ZGC automatisch im Generational Mode aktiviert.
Deaktivieren kannst du den Generational Mode durch -XX:+UseZGC -XX:-ZGenerational.
Annotation processing in javac disabled by default
Falls du ein Projekt mit Lombok-Annotationen auf Java 23 aktualisiert hast, könnte es sein, dass das Projekt nicht mehr ohne weiteres compiliert.
Das liegt daran, dass in Java 23 das Annotation Processing standardmäßig deaktiviert wurde. Der Grund dafür ist, dass durch Annotation Processing potentiell schadhafter Code ausgeführt werden könnte.
Um Annotation Processing wieder zu aktivieren, hast du folgende zwei Optionen:
- Empfohlen: Über die
javac-Optionen-processor,--processor-pathoder--processor-module-pathden oder die zu aktivierenden Prozessoren angeben, z. B.:javac -processorpath …/m2repo/org/projectlombok/lombok/1.18.38/lombok-1.18.38.jar … - Aus Sicherheitsgründen nicht empfohlen: über die javac-Option
-proc:fullkannst du Annotation Processing für alle Prozessoren aktivieren:javac -proc:full ...
In einem Maven-Projekt aktivierst du das Annotation Processing für Lombok durch folgenden Eintrag in der pom.xml (erfordert maven-compiler-plugin 3.8.0 oder höher):
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>...</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>...</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>Code-Sprache: HTML, XML (xml)In Gradle ist es deutlich einfacher – hier musst du bloß im dependencies-Block folgende Zeile einfügen:
annotationProcessor 'org.projectlombok:lombok:1.18.8'Code-Sprache: Gradle (gradle)(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8321314 registriert.)
Removal of Module jdk.random
Diese Änderung ist nicht unter „Löschungen” einsortiert, da nicht wirklich etwas gelöscht wurde. Alle Klassen des Moduls jdk.random wurden in das java.base-Modul verschoben.
Solltest du das Java Modulsystem verwenden und irgendwo requires jdk.random angegeben haben, dann kannst du diesen Eintrag in Java 23 entfernen (das java.base-Modul wird automatisch eingebunden).
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8330005 registriert.)
Console Methods With Explicit Locale
Mit der in Java 6 eingeführten Console-Klasse können wir bequem Text auf der Konsole ausgeben und User-Eingaben von der Konsole einlesen:
Console console = System.console();
var name = console.readLine("What's your name (by the way, π = %.4f)? ", Math.PI);
var password = console.readPassword("Your password (by the way, e = %.4f)? ", Math.E);
console.printf("Your name is %s%n", name); // `printf` and `format` do the same
console.format("Your password starts with %c%n", password[0]);Code-Sprache: Java (java)Hierbei wurde immer das Default-Locale verwendet, d. h. je nach Spracheinstellung wurde Pi entweder als 3,1415 (mit Komma) oder 3.1415 (mit Punkt) ausgegeben.
Ab Java 23 kannst du bei den Methoden printf(...), format(...), readLine(...) und readPassword(...) als zusätzlichen Parameter an erster Stelle ein Locale angeben:
Console console = System.console();
var name = console.readLine(Locale.US, "What's your name (π = %.4f)? ", Math.PI);
var password = console.readPassword(Locale.US, "Your password (e = %.4f)? ", Math.E);
console.printf(Locale.US, "Your name is %s%n", name);
console.format(Locale.US, "Your password starts with %c%n", password[0]);Code-Sprache: Java (java)In diesem Beispiel wird nun Pi immer im amerikanischen Stil, also als 3.1415 ausgegeben.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8330276 registriert.)
Support for Duration Until Another Instant
Um die Dauer zwischen zwei Instant-Objekten zu bestimmen, musste man bisher Duration.between(...) verwenden:
Instant now = Instant.now();
Instant later = Instant.now().plus(ThreadLocalRandom.current().nextInt(), SECONDS);
Duration duration = Duration.between(now, later);Code-Sprache: Java (java)Da diese Methode nicht leicht auffindbar ist, wurde eine neue Instanz-Methode Instant.until(...) eingeführt, die exakt die gleiche Berechnung durchführt:
Instant now = Instant.now();
Instant later = Instant.now().plus(ThreadLocalRandom.current().nextInt(), SECONDS);
Duration duration = now.until(later);Code-Sprache: Java (java)(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8331202 registriert.)
Relax alignment of array elements
Auf einem 64-Bit-System arbeitet die JVM bei maximal 32 GB Heap standardmäßig mit komprimierten Pointern, den sogenannten „Compressed Oops“ (OOP = ordinary object pointer) und den „Compressed Class Pointers“. Diese komprimierten Pointer sind statt 64 Bit nur 32 Bit lang. Damit werden für jedes Objekt im Arbeitsspeicher 64 Bit (= 8 Byte) eingespart: 32 Bit für den Pointer auf das Objekt und weitere 32 Bit für den Pointer von diesem Objekt auf dessen Klasse.
Mit 32 Bit können eigentlich nur 232 Bytes = 4 GB adressiert werden. Doch die JVM wendet einen Trick an: Sie schiebt diese 32 Bit um drei Stellen nach links, so dass daraus 35 Bit werden (deren letzten drei Bit immer 0 sind). Mit diesen 35 Bit lassen sich dann 235 = 32 GB adressieren.
Da, wie eben erwähnt, die letzten drei Bit immer 0 sind, kann so ein Pointer nicht auf jede beliebige Adresse im Speicher zeigen, sondern nur auf Adressen, die durch 23 = 8 teilbar sind. Und somit startet jedes Java-Objekt immer an einer durch 8 teilbaren Speicheradresse.
Das galt, aus unerfindlichen Gründen, bisher auch für die Start-Adresse der Array-Daten innerhalb eines Array-Objekts. Standardmäßig sind sowohl Compressed Oops als auch Compressed Class Pointers aktiviert, so dass z. B. ein Array mit z. B. drei Bytes (im Beispiel: 0, 8, 15) wie folgt aufgebaut ist:

Wir sehen hier zunächst einen 12-Byte-Header, der aus einem 8-Byte großen „Mark word“ besteht (das enthält u. a. Informationen für den Garbage Collector und für die Synchronisation) sowie einem 4-Byte großen komprimierten Class Pointer. Darauf folgen ein 4-Byte-Größenfeld und die eigentlichen Daten des Arrays. Am Ende liegen fünf unbelegte Bytes („Padding“), da die Gesamtgröße aus dem o. g. Grund auf einen durch acht teilbaren Wert aufgerundet wird.
So weit, so gut.
Wenn wir allerdings Compressed Class Pointers deaktivieren, dann ergab sich bisher folgendes Bild:

Da auch die Start-Adresse der Array-Daten (des blauen Bereichs in der Grafik) bisher durch acht teilbar sein musste, haben wir sowohl einen Verlust von vier Bytes vor den Array-Daten als auch einen weiteren Verlust von fünf Bytes am Ende des Objekts, insgesamt also neun Bytes.
Da es keinen Grund dafür, gibt auch die Array-Daten an einer durch acht teilbaren Adresse starten zu lassen (es gibt keine komprimierten Pointer dorthin), wurde das Layout bei unkomprimierten Class Pointers in Java 23 wie folgt geändert:
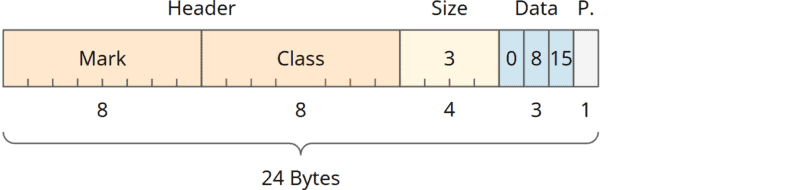
Der blaue Bereich beginnt nun direkt nach dem Größenfeld. Das gleiche Array belegt nun acht Bytes weniger, und es geht nur noch ein Byte verloren, nicht mehr neun. Bei einer Anwendung mit vielen kleinen Arrays, kann das in Summe zu einer spürbaren Reduzierung des Speicherbedarfs führen.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8139457 registriert.)
Change LockingMode default from LM_LEGACY to LM_LIGHTWEIGHT
In Java 21 wurde ein neuer, leichtgewichtiger Locking-Mechanismus eingeführt, der mittelfristig das bisherige Stack Locking ablösen soll.
In Java 22 wurde diese zunächst experimentelle Option zu einer produktiven Option befördert.
In Java 23 wird Lightweight Locking zum Standard-Locking-Mechanismus.
Du kannst vorübergehend den bisherigen Default-Modus, Stack Locking, durch die VM-Option -XX:LockingMode=1 wieder aktivieren.
Stack Locking wird in Java 24 als „deprecated“ markiert und voraussichtlich in Java 27 entfernt werden.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8319251 registriert.)
Vollständige Liste aller Änderungen in Java 23
In diesem Artikel hast du alle Java-23-Features kennengelernt, die aus JDK Enhancement Proposals (JEPs) hervorgegangen sind, sowie einige weitere ausgewählte Änderungen aus den Release Notes. Eine vollständige Liste aller Änderungen findest du in den Java 23 Release Notes.
Fazit
Java 23 bringt uns drei neue Features und eine Menge an aktualisierten Preview-Features.
- Das Schreiben und Lesen von JavaDoc-Kommentaren wird in Zukunft einfacher, da wir ab sofort auch Markdown verwenden dürfen.
- Statt wie bisher Klassen und Pakete, können wir in Zukunft mit
import moduleganze Module importieren und damit denimport-Block einer .java-Datei deutlich übersichtlicher machen. - Primitive Type Patterns erweitern die Pattern-Matching-Fähigkeiten von Java um primitive Typen. Ich kann mir allerdings nicht vorstellen, dass wir diese Art von Pattern Matching oft in unserem Code einsetzen werden (ganz im Gegensatz zu den Pattern-Matching-Fähigkeiten, die Java in den vorherigen Releases hinzubekommen hat).
- In implizit deklarierten Klassen dürfen wir nun statt
System.out.println(...)einfach nurprintln(...)schreiben. ScopedValue.callWhere(...)bekommt nun eine typisierteCallableOpübergeben, so dass der Compiler automatisch erkennen kann, ob die aufgerufene Operation eine checked Exception werfen kann – und wenn ja, welche. So müssen wir nicht mehr die generischeExceptionbehandeln, sondern die tatsächlich geworfene. Und die separateScopedValue.getWhere(-Methode kann dadurch wegfallen....)- In Konstruktoren abgeleiter Klassen dürfen wir nun vor dem Aufruf von
super(...)Felder der abgeleiteten Klasse initialisieren. Das ist hilfreich, wenn der Konstruktor der Elternklasse Methoden aufruft, die in der abgeleiteten Klasse überschrieben sind und dort auf eben diese Felder zugreifen. - Wer den Z Garbage Collector nutzt, kommt durch das Upgrade auf Java 23 automatisch in den Genuss des neuen generational mode, der die meisten Anwendungen spürbar performanter machen sollte.
- Außerdem wurde groß aufgeräumt: Die seit Ewigkeiten als deprecated markierten Methoden
Thread.suspend(),Thread.resume(),ThreadGroup.suspend(),ThreadGroup.resume()undThreadGroup.stop()wurden in Java 23 endlich entfernt. AlleUnsafe-Methoden für Speicherzugriffe wurden als deprecated for removal markiert.
Diverse sonstige Änderungen runden wie immer das Release ab. Das aktuelle Java-23-Release kannst du hier herunterladen.
Welche der neuen Java 23-Features findest du am spannendsten? Welches Feature vermisst du? Teile deine Meinung in den Kommentaren!