


Binärbaum
(mit Java-Code)
Zwei der wichtigsten Themen in der Informatik sind das Sortieren und Suchen von Datensätzen. Eine Datenstruktur, die für beides häufig zum Einsatz kommt, ist der Binärbaum im Allgemeinen und seine Spezialfälle binärer Suchbaum und binärer Heap.
In diesem Artikel erfährst du:
- Was ist ein Binärbaum?
- Welche Arten von Binärbäumen gibt es?
- Wie implementiert man einen Binärbaum in Java?
- Welche Operationen stellen Binärbäume bereit?
- Was bedeuten pre-order, in-order, post-order und level-order bei der Traversierung von Binärbäumen?
Den Quellcode zum Artikel findest du in diesem GitHub-Repository.
Binärbaum Definiton
Ein Binärbaum ist eine Baum-Datenstruktur, in der jeder Knoten maximal zwei Kindknoten hat. Die Kindknoten werden als linkes und rechtes Kind bezeichnet.
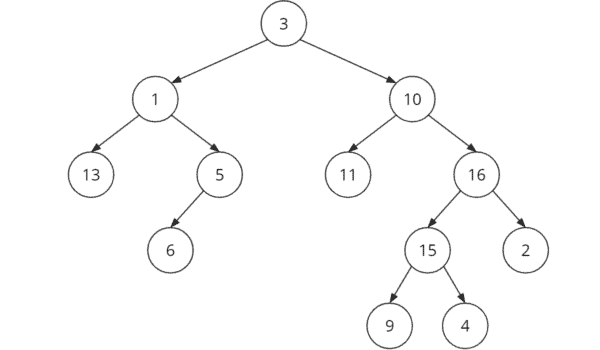
Binärbaum Beispiel
Ein Binärbaum sieht beispielsweise wie folgt aus:
Binärbaum Terminologie
Die folgenden Begriffe sollte man als Entwickler kennen:
- Ein Knoten (englisch "node") ist eine Struktur, die einen Wert enthält, sowie optionale Referenzen auf einen linken und einen rechten Kindknoten (oder nur Kind, englisch "child node" oder "child").
- Die Verbindung zwischen zwei Knoten bezeichnet man als Kante (englisch "edge").
- Der oberste Knoten wird als Wurzel oder Wurzelknoten bezeichnet (englisch "root" oder "root node").
- Ein Knoten, der Kinder hat, ist ein innerer Knoten (englisch "inner node", kurz "inode") und gleichzeitig der Elternknoten (englisch "parent" oder "parent node") des oder der Kinder.
- Ein Knoten ohne Kinder wird äußerer Knoten (englisch "outer node") oder auch Blatt (englisch "leaf" oder "leaf node") genannt.
- Ein Knoten mit nur einem Kind ist ein Halbblatt (englisch "half node"). Achtung: diesen Begriff gibt es – im Gegensatz zu allen anderen – ausschließlich bei Binärbäumen, nicht bei Bäumen im Allgemeinen.
- Die Anzahl der Kindknoten bezeichnet man auch als Ausgangsgrad eines Knotens (englisch "degree").
- Die Tiefe (englisch "depth") eines Knotens gibt an, wie viele Ebenen der Knoten von der Wurzel entfernt ist. Die Wurzel hat also eine Tiefe von 0, die Kinder der Wurzel eine Tiefe von 1, usw.
- Die Höhe (englisch "height") des Binärbaums ist die maximale Tiefe aller Knoten.
Die folgende Grafik zeigt dieselbe Binärbaum-Datenstruktur wie zuvor, beschriftet mit Knotentypen, Knotentiefe und Höhe des Binärbaumes.

Eigenschaften von Binärbäumen
Bevor wir zur Implementierung von Binärbäumen und deren Operationen kommen, zunächst eine kurze Übersicht über einige spezielle Arten von Binärbäumen.
Voller Binärbaum
In einem vollen Binärbaum (englisch: full binary tree) haben alle Knoten entweder keine oder zwei Kinder.
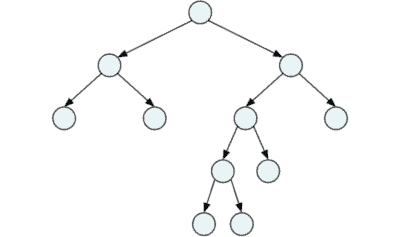
Vollständiger Binärbaum
Leider wird diese Bezeichnung in der Literatur nicht einheitlich verwendet. Manche Autoren bezeichnen einen kompletten Binärbaum als vollständig, andere bezeichnen einen perfekten Binärbaum als vollständig. Ich werde daher nur die Begriffe komplett und perfekt verwenden.
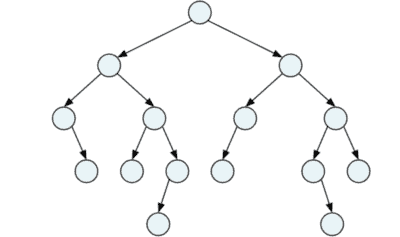
Kompletter Binärbaum
In einem kompletten Binärbaum (englisch: complete binary tree) sind alle Ebenen, außer möglicherweise die letzte, vollständig gefüllt. Wenn die letzte Ebene nicht vollständig gefüllt ist, dann sind deren Knoten so weit wie möglich links angeordnet.

Perfekter Binärbaum
Ein perfekter Binärbaum (englisch: perfect binary tree) ist ein voller Binärbaum, in dem alle Blätter die gleiche Tiefe haben.

Ein perfekter Binärbaum der Höhe h hat n = 2h+1-1 Knoten und l = 2h Blätter.
Bei einer Höhe von 3 sind das 15 Knoten, davon 8 Blätter.
Balancierter Binärbaum
In einem balancierten Binärbaum (englisch: balanced binary tree) unterscheiden sich die linken und rechten Teilbäume eines jeden Knoten in der Höhe um maximal eins.
Sortierter Binärbaum
In einem sortierten Binärbaum (englisch: sorted binary tree) enthält der linke Teilbaum eines Knotens nur Werte die kleiner (oder gleich) als der Wert des Elternknotens sind, und der rechte Teilbaum nur Werte die größer (oder gleich) als der Wert des Elternknotens sind. Solch eine Datenstruktur wird auch binärer Suchbaum genannt.
Binärbaum in Java
Für die Binärbaum-Implementierung in Java definieren wir zunächst die Datenstruktur für die Knoten (Klasse Node im GitHub-Repository). Der Einfachheit halber verwenden wir int-Primitive als Werte. Wir können natürlich auch jeden anderen oder einen generischen Datentyp verwenden; mit einem int ist der Code allerdings leserlicher – und das ist für dieses Tutorial am wichtigsten.
public class Node {
int data;
Node left;
Node right;
Node parent;
public Node(int data) {
this.data = data;
}
}Code-Sprache: Java (java)Die parent-Referenz ist nicht zwingend nötig für die Speicherung und Darstellung des Baumes; sie ist allerdings – zumindest bei bestimmten Arten von Binärbäumen – hilfreich beim Löschen von Knoten.
Der Binärbaum selbst besteht zunächst einmal nur aus dem Interface BinaryTree und dessen Minimal-Implementierung BaseBinaryTree, welche lediglich eine Referenz auf den Wurzelknoten enthält:
public interface BinaryTree {
Node getRoot();
}
public class BaseBinaryTree implements BinaryTree {
Node root;
@Override
public Node getRoot() {
return root;
}
}Code-Sprache: Java (java)Warum wir uns hier die Mühe machen ein Interface zu definieren, wird sich im weiteren Verlauf des Tutorials zeigen.
Die Binärbaum-Datenstruktur ist damit vollständig definiert.
Binärbaum-Traversierung
Eine der wichtigsten Operationen auf Binärbäumen ist die Traversierung aller Knoten, also das Besuchen aller Knoten in einer bestimmten Reihenfolge. Die gängigsten Arten der Traversierung sind:
- Tiefensuche (pre-order, post-order, in-order, reverse in-order)
- Breitensuche (level-order)
In den folgenden Abschnitten werden die verschiedenen Arten an folgendem Beispiel gezeigt:

Das oben erwähnte Besuchen während der Traversierung realisieren wir mit dem Visitor-Pattern, d. h. wir erstellen ein Visitor-Objekt, das wir an die Traversierungsmethode übergeben.
Tiefensuche im Binärbaum
Bei der Tiefensuche (englisch: depth-first search, DFS) wird in einer bestimmten Reihenfolge:
- der aktuelle Knoten besucht (im folgenden als "N" bezeichnet),
- die Tiefensuche rekursiv auf das linke Kind aufgerufen (im folgenden "L"),
- die Tiefensuche rekursiv auf das rechte Kind aufgerufen (im folgenden "R").
Die gängigen Reihenfolgen sind:
Hauptreihenfolge (pre-order)
In der Hauptreihenfolge (Kennzeichnung: N–L–R) erfolgt die Traversierung in folgender Reihenfolge:
- Besuchen des aktuellen Knotens "N"
- Rekursiver Aufruf der Tiefensuche auf linken Teilbaum "L"
- Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum "R"
Die Knoten des Beispielbaumes werden, wie in folgender Grafik zu sehen, in folgender Reihenfolge besucht: 3→1→13→10→11→16→15→2
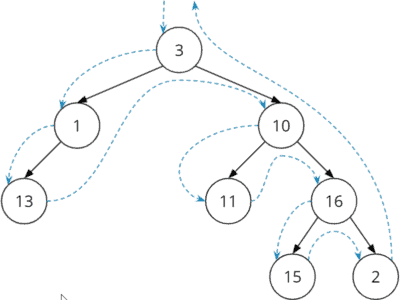
Der Code hierfür ist relativ simpel (Klasse DepthFirstTraversalRecursive ab Zeile 21):
public static void traversePreOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
visitor.visit(node);
traversePreOrder(node.left, visitor);
traversePreOrder(node.right, visitor);
}Code-Sprache: Java (java)Die Methode kann entweder direkt aufgerufen werden – dann muss ihr der Wurzelknoten übergeben werden – oder über die nicht-statische Methode traversePreOrder() der gleichen Klasse (DepthFirstTraversalRecursive ab Zeile 17):
public void traversePreOrder(NodeVisitor visitor) {
traversePreOrder(tree.getRoot(), visitor);
}Code-Sprache: Java (java)Dazu muss eine Instanz von DepthFirstTraversalRecursive erstellt werden, wobei dem Konstruktur eine Referenz auf den Binärbaum übergeben wird:
new DepthFirstTraversalRecursive(tree).traversePreOrder(visitor);Code-Sprache: Java (java)Eine iterative Implementierung ist mit einem Stack möglich (Klasse DepthFirstTraversalIterative ab Zeile 20). Die iterativen Implementierungen sind recht komplex, weshalb ich sie hier nicht mit abdrucke.
Warum ich in den iterativen Tree-Traversals ArrayDeque anstatt Stack verwende, kannst du hier nachlesen: Warum man Stack nicht (mehr) verwenden sollte
Nebenreihenfolge (post-order)
In der Nebenreihenfolge (Kennzeichnung: L–R–N) erfolgt die Traversierung in folgender Reihenfolge:
- Rekursiver Aufruf der Tiefensuche auf linken Teilbaum "L"
- Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum "R"
- Besuchen des aktuellen Knotens "N"
Die Knoten des Beispielbaumes werden hierbei in folgender Reihenfolge besucht: 13→1→11→15→2→16→10→3

Den Code findest du in DepthFirstTraversalRecursive ab Zeile 42:
public static void traversePostOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traversePostOrder(node.left, visitor);
traversePostOrder(node.right, visitor);
visitor.visit(node);
}Code-Sprache: Java (java)Die iterative Implementierung, die bei der Post-Order-Traversierung noch komplizierter ist als bei der Pre-Order-Traversierung, findest du in DepthFirstTraversalIterative ab Zeile 44.
Symmetrische Reihenfolge (in-order)
In der symmetrischen Reihenfolge (Kennzeichnung: L–N–R) erfolgt die Traversierung in folgender Reihenfolge:
- Rekursiver Aufruf der Tiefensuche auf linken Teilbaum "L"
- Besuchen des aktuellen Knotens "N"
- Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum "R"
Die Knoten des Beispielbaumes werden in folgender Reihenfolge besucht: 13→1→3→11→10→15→16→2

Den rekursiven Code findest du in DepthFirstTraversalRecursive ab Zeile 62:
public static void traverseInOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traverseInOrder(node.left, visitor);
visitor.visit(node);
traverseInOrder(node.right, visitor);
}Code-Sprache: Java (java)Die iterative Implementierung der In-Order-Traversierung findest du in DepthFirstTraversalIterative ab Zeile 69.
Im binären Suchbaum werden bei der In-Order-Traversierung die Knoten in der Reihenfolge ihrer Sortierung besucht.
Anti-symmetrische Reihenfolge (reverse in-order)
In der anti-symmetrischen Reihenfolge (Kennzeichnung: R–N–L) erfolgt die Traversierung in folgender Reihenfolge:
- Rekursiver Aufruf der Tiefensuche auf rechten Teilbaum "R"
- Besuchen des aktuellen Knotens "N"
- Rekursiver Aufruf der Tiefensuche auf linken Teilbaum "L"
Die Knoten des Beispielbaumes werden in entgegengesetzter Reihenfolge zur In-Order-Traversierung besucht: 2→16→15→10→11→3→1→13

Den rekursiven Code findest du in DepthFirstTraversalRecursive ab Zeile 83:
public static void traverseReverseInOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traverseReverseInOrder(node.right, visitor);
visitor.visit(node);
traverseReverseInOrder(node.left, visitor);
}Code-Sprache: Java (java)Die iterative Implementierung der Reverse-In-Order-Traversierung findest du in DepthFirstTraversalIterative ab Zeile 89.
Im binären Suchbaum werden bei der Reverse-In-Order-Traversierung die Knoten in absteigender Reihenfolge ihrer Sortierung besucht.
Breitensuche im Binärbaum
Bei der Breitensuche (englisch: breadth-first, BFS) – auch Level-Order-Traversierung genannt – werden die Knoten von der Wurzel beginnend, Ebene für Ebene, von links nach rechts besucht.
Es ergibt sich folgende Reihenfolge: 3→1→10→13→11→16→15→2

Um die Knoten in dieser Reihenfolge zu besuchen, benötigen wir eine Queue, in der wir zuerst den Root-Knoten einfügen, und dann wiederholt das erste Element entnehmen, dieses besuchen und dessen Kinder in die Queue eintragen – solange bis die Queue wieder leer ist.
Den Code findest du in der Klasse BreadthFirstTraversal:
public static void traverseLevelOrder(Node root, NodeVisitor visitor) {
if (root == null) {
return;
}
Queue<Node> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
Node node = queue.poll();
visitor.visit(node);
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}Code-Sprache: Java (java)Den Aufruf aller Traversierungs-Arten findest du beispielhaft in der Methode traverseTreeInVariousWays() der Klasse Example1.
Operationen auf Binärbäumen
Neben der Traversierung sind weitere grundlegenden Operationen auf Binärbäumen das Einfügen sowie das Löschen von Knoten.
Operationen zum Suchen werden von speziellen Binärbäume wie z. B. dem binären Suchbaum bereitgestellt. Ohne spezielle Eigenschaften können wir im Binärbaum nur suchen, in dem wir über alle Knoten traversieren und diese mit dem gesuchten Element vergleichen.
Element einfügen
Beim Einfügen neuer Elemente müssen wir verschiedene Fälle unterscheiden:
Fall A: Knoten unter Blatt oder Halbblatt einfügen
Es ist leicht einen neuen Knoten an ein Blatt oder ein Halbblatt anzuhängen. Hierzu müssen wir lediglich die left- oder right-Referenz des Parent-Knotens P, an den wir den neuen Knoten N anhängen wollen, auf den neuen Knoten setzen. Wenn wir auch mit parent-Referenzen arbeiten, müssen wir diese im neuen Knoten N auf den Parent-Knoten P setzen.


Fall B: Knoten zwischen internen Knoten und dessen Kind einfügen
Doch wie geht man vor, wenn man einen Knoten zwischen einem internen Knoten und einem seiner Kinder einfügen will?

Das ist nur mit einer Reorganisation des Baumes möglich. Wie genau der Baum reorganisiert wird, hängt von der konkreten Art des Binärbaumes ab.
Wir implementieren in diesem Tutorial einen sehr einfachen Binärbaum und gehen für die Reorganisation wie folgt vor:
- Wenn der neue Knoten N als linkes Kind unter den internen Knoten P eingefügt werden soll, wird Ps aktueller linker Teilbaum L als linkes Kind unter den neuen Knoten N gesetzt. Entsprechend wird der Parent von L auf N gesetzt und der Parent von N auf P.
- Wenn der neue Knoten N als rechtes Kind unter den internen Knoten P eingefügt werden soll, wird Ps aktueller rechter Teilbaum R als rechtes Kind unter den neuen Knoten N gesetzt. Entsprechend wird der Parent von R auf N gesetzt und der Parent von N auf P.
Die folgende Grafik zeigt den zweiten Fall: Wir fügen den neuen Knoten N zwischen P und R ein:
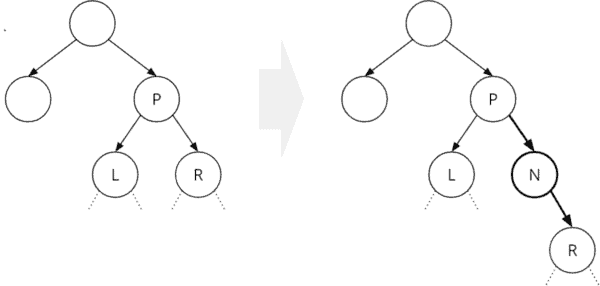
Das ist – wie gesagt – eine sehr einfache Implementierung. Im Beispiel oben resultiert diese in einem stark unbalancierten Binärbaum.
Spezielle Binärbäume gehen hier anders vor, um eine Baum-Struktur beizubehalten, die die speziellen Eigenschaften des jeweiligen Binärbaumes (Sortierung, Balancierung, etc.) erfüllt.
Baumknoten einfügen – Java-Quellcode
Hier siehst du den Code zum Einfügen eines neuen Knotens mit Wert data unter den gegebenen Knoten parent an die gegebene Seite side (links oder rechts) mit der im vorherigen Abschnitt festgelegten Reorganisations-Strategie (Klasse SimpleBinaryTree ab Zeile 18).
(Der Switch-Ausdruck mit den geschweiften Klammern wurde in Java 12/13 eingeführt).
public Node insertNode(int data, Node parent, Side side) {
var node = new Node(data);
node.parent = parent;
switch (side) {
case LEFT -> {
if (parent.left != null) {
node.left = parent.left;
node.left.parent = node;
}
parent.left = node;
}
case RIGHT -> {
if (parent.right != null) {
node.right = parent.right;
node.right.parent = node;
}
parent.right = node;
}
default -> throw new IllegalStateException();
}
return node;
}Code-Sprache: Java (java)In der Methode createSampleTree() der Klasse Example1 siehst du, wie der Binärbaum aus dem Beispiel vom Beginn des Artikels angelegt wird.
Element löschen
Auch beim Löschen eines Knotens müssen wir verschiedene Fälle unterscheiden.
Fall A: Knoten ohne Kinder (Blatt) löschen
Ist der zu löschende Knoten N ein Blatt, hat also selbst keine Kinder, dann wird der Knoten einfach entfernt. Dazu prüfen wir, ob der Knoten linkes oder rechtes Kind des Parents P ist und setzen entsprechend dessen left- oder right-Referenz auf null.

Fall B: Knoten mit einem Kind (Halbblatt) löschen
Hat der zu löschende Knoten N selbst ein Kind C, dann rückt dieses an die gelöschte Position auf. Wir müssen wieder prüfen, ob der zu löschende Knoten N linkes oder rechtes Kind des Parents P ist. Danach setzen wir entsprechend die left- oder right-Referenz des Parents auf das Kind C des zu löschenden Knotens N (den vorherigen Enkel) – und die parent-Referenz des Kindes C auf den Parent P des zu löschenden Knotens N (den vorherigen Großeltern-Knoten).

Fall C: Knoten mit zwei Kindern löschen
Wie geht man vor, wenn man einen Knoten mit zwei Kindern löschen will?

Dies ist nur mit einer Umorganisation des Binärbaum möglich. Analog zum Einfügen gibt es auch für das Löschen – je nach konkreter Art des Binärbaumes – unterschiedliche Strategien. In einem Heap beispielsweise wird an die Position des gelöschten Knotens der letzte Knoten des Baums gesetzt und danach der Heap repariert.
Wir verwenden für unser Tutorial folgende, einfach zu implementierende Variante:
- Wir ersetzen den gelöschten Knoten N durch dessen linken Teilbaum L.
- Wir hängen den rechten Teilbaum R an den am weitesten rechts liegenden Knoten des linken Teilbaums an.

Es ist gut zu erkennen, wie diese Strategie zu einem sehr unbalancierten Binärbaum führt. Binärbäume wir der binäre Suchbaum und der Binäre Heap haben daher – wie auch beim Einfügen – komplexere Strategien.
Baumknoten löschen – Java-Quellcode
Die folgende Methode (Klasse SimpleBinaryTree ab Zeile 71) entfernt den übergebenen Knoten node aus dem Baum. Die Fälle A, B und C sind durch entsprechende Kommentare gekennzeichnet.
public void deleteNode(Node node) {
if (node.parent == null && node != root) {
throw new IllegalStateException("Node has no parent and is not root");
}
// Case A: Node has no children --> set node to null in parent
if (node.left == null && node.right == null) {
setParentsChild(node, null);
}
// Case B: Node has one child --> replace node by node's child in parent
// Case B1: Node has only left child
else if (node.right == null) {
setParentsChild(node, node.left);
}
// Case B2: Node has only right child
else if (node.left == null) {
setParentsChild(node, node.right);
}
// Case C: Node has two children
else {
removeNodeWithTwoChildren(node);
}
// Remove all references from the deleted node
node.parent = null;
node.left = null;
node.right = null;
}Code-Sprache: Java (java)Die Methode setParentsChild() prüft, ob der zu löschende Knoten das linke oder rechte Kind seines Elternknotens ist und ersetzt die entsprechende Referenz im Elternknoten durch den Kindknoten child. Dieser ist null, wenn der zu löschende Knoten keine Kinder hat und entsprechend die Kind-Referenz im Elternknoten auf null gesetzt werden soll.
Für den Fall, dass der zu löschende Knoten die Wurzel ist, wird einfach die Wurzelreferenz neu gesetzt.
private void setParentsChild(Node node, Node child) {
// Node is root? Has no parent, set root reference instead
if (node == root) {
root = child;
if (child != null) {
child.parent = null;
}
return;
}
// Am I the left or right child of my parent?
if (node.parent.left == node) {
node.parent.left = child;
} else if (node.parent.right == node) {
node.parent.right = child;
} else {
throw new IllegalStateException(
"Node " + node.data + " is neither a left nor a right child of its parent "
+ node.parent.data);
}
if (child != null) {
child.parent = node.parent;
}
}Code-Sprache: Java (java)In Fall C (Knoten mit zwei Kindern löschen) wird der Baum, wie im vorangegangenen Abschnitt beschrieben, umorganisiert. Dies geschieht in der separaten Methode removeNodeWithTwoChildren():
private void removeNodeWithTwoChildren(Node node) {
Node leftTree = node.left;
Node rightTree = node.right;
setParentsChild(node, leftTree);
// find right-most child of left tree
Node rightMostChildOfLeftTree = leftTree;
while (rightMostChildOfLeftTree.right != null) {
rightMostChildOfLeftTree = rightMostChildOfLeftTree.right;
}
// append right tree to right child
rightMostChildOfLeftTree.right = rightTree;
rightTree.parent = rightMostChildOfLeftTree;
}Code-Sprache: Java (java)In der Methode deleteSomeNodes() der Klasse Example1 siehst du, wie einige Knoten des Beispielbaums wieder gelöscht werden.
Array-Darstellung des Binärbaums
Zum Abschluss möchte ich dir eine alternative Repräsentation des Binärbaums zeigen: die Speicherung in einem Array.
Dabei enthält das Array so viele Elemente wie ein perfekter Binärbaum der Höhe des zu speichernden Binärbaumes, also 2h+1-1 Elemente bei einer Höhe h (in der folgenden Grafik: 7 Elemente bei Höhe 2).
Die Knoten des Baumes werden von der Wurzel abwärts, Ebene für Ebene, von links nach rechts durchnummeriert und auf das Array abgebildet, wie folgende Grafik zeigt:

Nicht vorhandene Knoten können durch einen festgelegten Wert dargestellt werden. Sollte der Baum beispielsweise nur nicht-negative ganze Zahlen enthalten, könnte ein fehlender Knoten durch den Wert -1 dargestellt werden.
Bei einem kompletten Binärbaum kann alternativ das Array entsprechend verkürzt werden oder die Anzahl der Knoten als zusätzlicher Wert gespeichert werden.
Vor- und Nachteile der Array-Darstellung
Die Array-Darstellung hat folgende Vorteile:
- Die Speicherung ist kompakter, da keine Referenzen auf Kinder (und ggf. Eltern) benötigt werden.
- Trotzdem gelangt man schnell von Eltern zu Kindern und umgekehrt:
Für einen Knoten an Index i befinden sich...- das linke Kind an Index 2i+1,
- das rechte Kind an Index 2i+2,
- der Elternknoten an Index i/2 abgerundet.
- Eine Level-Order-Traversierung kann durch simple Iteration über das Array durchgeführt werden.
Dagegen aufwiegen muss man folgende Nachteile:
- Wenn der Binärbaum nicht komplett ist, wird Speicherplatz durch ungenutzte Array-Felder verschwendet.
- Wenn der Baum über die Array-Größe hinaus wächst, müssen die Daten in ein neues, größeres Array kopiert werden.
- Wenn der Baum kleiner wird, sollten (mit einem gewissen Spielraum) die Daten in ein neues, kleineres Array kopiert werden, um ungenutzten Speicherplatz freizugeben.
Zusammenfassung
In diesem Artikel hast du erfahren, was ein Binärbaum ist, welche Arten von Binärbäumen es gibt, welche Operationen auf Binärbäume anwendbar sind und wie man Binärbäume in Java implementiert.