


Dijkstra-Algorithmus
(mit Java-Beispiel)
Wie findet ein Navigationssystem den kürzesten Weg vom Start zum Ziel in möglichst geringer Zeit? Dieser Frage (und ähnlichen) geht diese Artikelserie über "Shortest Path"-Algorithmen nach.
Dieser Teil behandelt den Dijkstra-Algorithmus (englisch: "Dijkstra's algorithm") – benannt nach dessen Erfinder, Edsger W. Dijkstra. Dijkstras Algorithmus findet in einem Graphen zu einem gegebenen Startknoten die kürzeste Entfernung zu allen anderen Punkten (oder zu einem vorgegebenen Endpunkt).
Die Themen des Artikels im Einzelnen:
- Schritt-für-Schritt-Beispiel zur Erklärung der Funktionsweise des Algorithmus
- Quellcode des Dijkstra-Algorithmus (mit
PriorityQueue) - Bestimmung der Zeitkomplexität des Algorithmus
- Messung der Laufzeit – mit
PriorityQueue,TreeSetundFibonacciHeap
Fangen wir an mit dem Beispiel!
Dijkstras Algorithmus – Beispiel
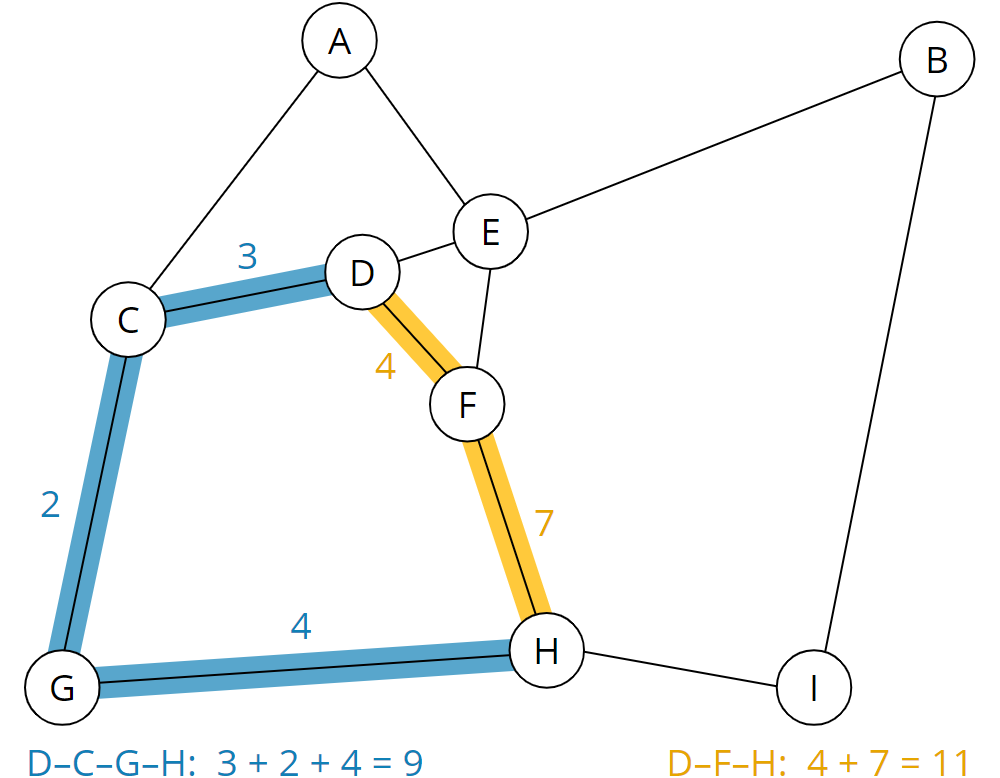
Den Dijkstra-Algorithmus erklärt man am besten an einem Beispiel. Die folgende Grafik zeigt eine fiktive Straßenkarte. Orte werden durch Kreise mit Buchstaben dargestellt; die Linien sind Straßen und Wege, die diese Orte verbinden.

Die dicken Linien stellen eine Schnellstraße dar; die etwas dünneren Linien sind die Landstraßen, und die gestrichelten Linien sind schwer passierbare Feldwege.
Die Straßenkarte bilden wir nun auf einen Graphen ab. Dörfer werden dabei zu Knoten, Straßen und Wege werden zu Kanten.
Die Gewichte der Kanten geben an, wie viele Minuten es dauert von einem Ort zum anderen zu kommen. Dabei spielt sowohl die Länge als auch die Beschaffenheit der Wege eine Rolle, d. h. eine lange Hauptstraße ist möglicherweise schneller passierbar als ein deutlich kürzerer Feldweg.
Es ergibt sich folgender Graph:

Aus dem Graph kann man nun z. B. ablesen, dass der Weg von D nach H auf der kürzesten Strecke – also auf dem Feldweg über Knoten F – 11 Minuten dauert (gelb hinterlegte Strecke). Über die deutlich längere Route über die Land- und Schnellstraßen über Knoten C und G (blaue Strecke) dauert es nur 9 Minuten:
Das menschliche Gehirn ist sehr gut darin, solche Muster zu erkennen. Einem Computer müssen wir dies erst mit geeigneten Mitteln beibringen. Hier kommt der Dijkstra-Algorithmus ins Spiel.
Vorbereitung – Tabelle der Knoten
Zuerst müssen wir einige Vorbereitungen treffen: Wir erstellen eine Tabelle der Knoten mit zwei zusätzlichen Attributen: Vorgänger-Knoten und Gesamtdistanz zum Startknoten. Die Vorgänger-Knoten bleiben zunächst leer; die Gesamtdistanz zum Startknoten wird im Startknoten selbst auf 0 gesetzt, in allen anderen Knoten auf ∞ (unendlich).
Die Tabelle wird nach Gesamtdistanz zum Startknoten aufsteigend sortiert, d. h. der Startknoten selbst (Knoten D) steht ganz vorne in der Tabelle; die übrigen Knoten sind unsortiert. Im Beispiel belassen wir sie in alphabetischer Reihenfolge:
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| D | – | 0 |
| A | – | ∞ |
| B | – | ∞ |
| C | – | ∞ |
| E | – | ∞ |
| F | – | ∞ |
| G | – | ∞ |
| H | – | ∞ |
| I | – | ∞ |
Im folgenden ist es wichtig die Begriffe Distanz und Gesamtdistanz zu unterscheiden:
- Distanz bezeichnet die Distanz von einem Knoten zu seinen Nachbarknoten;
- Gesamtdistanz bezeichnet die Summe aller Teildistanzen vom Startknoten über eventuelle Zwischenknoten zu einem bestimmten Knoten.
Dijkstras Algorithmus Schritt für Schritt – Abarbeitung der Knoten
In den folgenden Darstellungen der Graphen werden Vorgänger der Knoten und Gesamtdistanz mit angezeigt. Diese Daten sind in der Regel nicht im Graph selbst enthalten, sondern ausschließlich in der oben beschriebenen Tabelle. Ich zeige sie hier mit an, um das Verständnis zu erleichtern.
Schritt 1: Betrachten aller Nachbarn des Startpunkts
Nun entnehmen wir das erste Element – Knoten D – aus der Liste und betrachten dessen Nachbarn, also C, E und F.

Da die Gesamtdistanz in all diesen Nachbarn noch unendlich ist (d. h. wir haben noch keinen Weg dorthin entdeckt), setzen wir die Gesamtdistanz der Nachbarn auf die Distanz von D zum jeweiligen Nachbarn und tragen jeweils D als Vorgänger ein.

Die Liste sortieren wir wieder nach Gesamtdistanz (die geänderten Einträge sind fett hervorgehoben):
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| E | D | 1 |
| C | D | 3 |
| F | D | 4 |
| A | – | ∞ |
| B | – | ∞ |
| G | – | ∞ |
| H | – | ∞ |
| I | – | ∞ |
Die Liste ist so zu lesen: Knoten E, C und F sind entdeckt und können über D in 1, 3 bzw. 4 Minuten erreicht werden.
Schritt 2: Betrachten aller Nachbarn von Knoten E
Nun wiederholen wir, was wir eben für den Startknoten D getan haben, für den nächsten Knoten der Liste, Knoten E. Wir entnehmen E und betrachten dessen Nachbarn A, B, D und F:

Für Knoten A und B ist die Gesamtdistanz nach wie vor unendlich. Daher setzen wir deren Gesamtdistanz auf die Gesamtdistanz des aktuellen Knotens E (also 1) plus der Distanz von E zum jeweiligen Knoten:
| Knoten A | 1 (kürzeste Gesamtdistanz zu E) + 3 (Distanz E–A) = 4 |
| Knoten B | 1 (kürzeste Gesamtdistanz zu E) + 5 (Distanz E–B) = 6 |
Knoten D ist in der Tabelle nicht mehr enthalten. Das bedeutet, dass der kürzeste Weg dorthin bereits entdeckt wurde (es ist der Startknoten). Wir brauchen den Knoten daher nicht weiter zu betrachten.
Hier noch einmal der Graph mit aktualisierten Einträgen für A und B:

Zu Knoten F ist bereits eine Gesamtdistanz eingetragen (4 über Knoten D). Um zu prüfen, ob F über den aktuellen Knoten E schneller erreicht werden kann, berechnen wir die Gesamtdistanz zu F über E:
| Knoten F | 1 (kürzeste Gesamtdistanz zu E) + 6 (Distanz E–F) = 7 |
Wir vergleichen diese Gesamtdistanz mit der für F eingetragenen Gesamtdistanz. Die neu berechnete Gesamtdistanz 7 ist größer als die gespeicherte Gesamtdistanz 4. Der Weg über E ist also länger als der zuvor entdeckte. Er interessiert uns damit nicht weiter, und wir lassen den Tabelleneintrag für F unverändert.
Es ergibt sich folgender Zwischenstand in der Tabelle (die Änderungen sind fett hervorgehoben):
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| C | D | 3 |
| F | D | 4 |
| A | E | 4 |
| B | E | 6 |
| G | – | ∞ |
| H | – | ∞ |
| I | – | ∞ |
Die neuen Einträge sind so zu lesen: A und B wurden entdeckt; A ist über Knoten E in insgesamt 4 Minuten erreichbar, B ist über Knoten E in insgesamt 6 Minuten erreichbar.
Schritt 3: Betrachten aller Nachbarn von Knoten C
Wir wiederholen den Prozess für den nächsten Knoten in der Liste: Knoten C. Wir entfernen ihn aus der Liste und betrachten dessen Nachbarn, A, D und G:

Knoten D wurde bereits aus der Liste entfernt und wird ignoriert.
Wir berechnen die Gesamtdistanzen über C zu A und G:
| Knoten A | 3 (kürzeste Gesamtdistanz zu C) + 2 (Distanz C–A) = 5 |
| Knoten G | 3 (kürzeste Gesamtdistanz zu C) + 2 (Distanz C–G) = 5 |
Für A ist bereits ein kürzerer Weg über E mit Gesamtdistanz 4 eingetragen. Wir ignorieren also den neu entdeckten Weg über C zu A mit der größeren Gesamtdistanz 5 und lassen den Tabelleneintrag für A unverändert.
Knoten G hat noch die Gesamtdistanz unendlich. Wir tragen daher für G Gesamtdistanz 5 via Vorgänger C ein:

G hat nun eine kürzere Gesamtdistanz als B und rutscht in der Tabelle eine Position nach oben:
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| F | D | 4 |
| A | E | 4 |
| G | C | 5 |
| B | E | 6 |
| H | – | ∞ |
| I | – | ∞ |
Schritt 4: Betrachten aller Nachbarn von Knoten F
Wir entfernen den nächsten Knoten der Liste, F, und betrachten dessen Nachbarn D, E und H:

Zu Knoten D und E wurden die kürzesten Wege bereits entdeckt; wir müssen die Gesamtdistanz über den aktuellen Knoten F also nur für H berechnen:
| Knoten H | 4 (kürzeste Gesamtdistanz zu F) + 7 (Distanz F–H) = 11 |
Knoten H hat noch die Gesamtdistanz unendlich; wir tragen daher als Vorgänger den aktuellen Knoten F und als Gesamtdistanz 11 ein:

H ist unser Zielknoten. Wir haben also einen Weg zum Ziel gefunden, mit der Gesamtdistanz 11. Wir wissen allerdings noch nicht, ob dies der kürzeste Weg ist. Wir haben in der Tabelle noch drei weitere Knoten mit kürzeren Gesamtdistanz als 11: A, G und B:
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| A | E | 4 |
| G | C | 5 |
| B | E | 6 |
| H | F | 11 |
| I | – | ∞ |
Eventuell gibt es ja von einem dieser Knoten noch einen kurzen Weg zum Ziel, über den wir auf eine Gesamtdistanz von weniger als 11 kommen könnten.
Wir müssen daher den Prozess so lange weiterführen, bis es in der Tabelle keine Einträge vor dem Zielknoten H gibt.
Schritt 5: Betrachten aller Nachbarn von Knoten A
Wir entfernen Knoten A und betrachten dessen Nachbarn C und E:

Beide sind nicht mehr in der Tabelle enthalten, für beide wurden also bereits die kürzesten Wege entdeckt – wir können sie somit ignorieren. Über Knoten A führt also kein Weg zum Ziel. Damit ist Schritt 6 beendet.
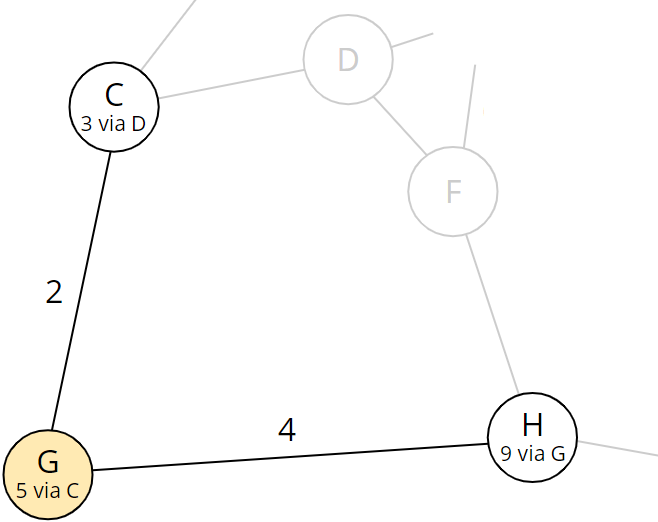
Schritt 6: Betrachten aller Nachbarn von Knoten G
Wir entnehmen Knoten G und betrachten dessen Nachbarn C und H:

C wurde bereits bearbeitet; es bleibt die Berechnung der Gesamtdistanz zu Knoten H über G:
| Knoten H | 5 (kürzeste Gesamtdistanz zu G) + 4 (Distanz G–H) = 9 |
Knoten H hat aktuell eine Gesamtdistanz von 11 über Knoten F. In Schritt 5 hatten wir den entsprechenden Weg entdeckt. Mit einer Gesamtdistanz von 9 haben wir nun einen kürzeren Weg gefunden! Wir ersetzen daher in H die 11 durch 9 und den bisherigen Vorgänger F durch den aktuellen Knoten G:
Die Tabelle sieht nun so aus:
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| B | E | 6 |
| H | G | 9 |
| I | – | ∞ |
Über Knoten B könnten wir einen noch kürzeren Weg zum Ziel finden, wir müssen also zuletzt auch noch diesen betrachten.
Schritt 7: Betrachten aller Nachbarn von Knoten B
Wir entnehmen also Knoten B und schauen uns dessen Nachbarn E und I an:

Zu E wurde der kürzeste Weg bereits entdeckt; für I berechnen wir die Gesamtdistanz über B:
| Knoten I | 6 (kürzeste Gesamtdistanz zu B) + 15 (Distanz B–I) = 21 |
Wir tragen für Knoten I die berechnete Gesamtdistanz und den aktuellen Knoten als Vorgänger ein:

In der Tabelle bleibt I hinter H:
| Knoten | Vorgänger | Gesamtdistanz |
|---|---|---|
| H | G | 9 |
| I | B | 21 |
Kürzester Weg zum Ziel wurde gefunden
Der erste Eintrag der Liste ist nun unser Zielknoten H. Es sind keine unentdeckten Knoten mit kürzerer Gesamtdistanz mehr vorhanden, von denen aus wir einen noch kürzeren Weg finden könnten.
Wir können aus der Tabelle ablesen: Der kürzeste Weg zum Zielknoten H führt über G und hat eine Gesamtdistanz von 9.
Backtrace zur Bestimmung des vollständigen Weges
Doch wie bestimmen wir den vollständigen Weg vom Startknoten D zum Zielknoten H? Dazu müssen wir uns Schritt für Schritt an den Vorgängern entlanghangeln.
Diesen sogenannten "Backtrace" führen wir anhand der in der Tabelle gespeicherten Vorgängerknoten durch. Der Übersicht halber stelle ich diese Daten hier noch einmal im Graphen dar:

Der Vorgänger des Zielknotens H ist G; der Vorgänger von G ist C; und der Vorgänger von C ist der Startpunkt D. Der kürzeste Weg lautet also: D–C–G–H.
Kürzeste Wege zu allen Knoten finden
Wenn wir den Algorithmus an dieser Stelle nicht abbrechen, sondern solange fortfahren, bis die Tabelle nur noch einen einzigen Eintrag enthält, haben wir die kürzesten Wege zu allen Knoten gefunden!
Im Beispiel müssen wir dazu nur noch die Nachbarknoten von Knoten H betrachten – G und I:

Knoten G wurde bereits abgearbeitet; wir berechnen die Gesamtdistanz zu I über H:
| Knoten I | 9 (kürzeste Gesamtdistanz zu H) + 3 (Distanz H–I) = 12 |
Der neu berechnete Weg zu I (12 via H) ist kürzer als der bereits hinterlegte (21 via B). Wir ersetzen also Vorgänger und Gesamtdistanz in Knoten I:

Die Tabelle enthält nun nur noch Knoten I:
| Knoten | Vorgänger | Distanz |
|---|---|---|
| I | B | 12 |
Wenn wir nun Knoten I entnehmen, ist die Tabelle leer, d. h. zu allen Nachbarknoten von I wurden bereits die kürzesten Wege gefunden.
Wir haben somit für alle Knoten des Graphes den kürzesten Weg vom (oder zum) Startknoten D gefunden!
Dijkstras "Kürzester Pfad"-Algorithmus – Informelle Beschreibung
Vorbereitung:
- Erstelle eine Tabelle aller Knoten mit Vorgängerknoten und Gesamtdistanz.
- Setze die Gesamtdistanz des Startknotens auf 0 und die aller anderer Knoten auf unendlich.
Abarbeitung der Knoten:
Solange die Tabelle nicht leer ist, entnehme das Element mit der kleinsten Gesamtdistanz und mache damit folgendes:
- Ist das entnommene Element der Zielknoten? Wenn ja, ist die Abbruchbedingung erfüllt. Folge dann den Vorgängerknoten zurück zum Startknoten, um den kürzesten Weg zu bestimmen.
- Andersfalls betrachte alle Nachbarknoten des entnommenen Elements, die sich noch in der Tabelle befinden. Für jeden Nachbarknoten:
- Berechne die Gesamtdistanz als Summe der Gesamtdistanz des entnommenen Knotens plus der Distanz zum betrachteten Nachbarknoten.
- Ist diese Gesamtdistanz kürzer als die bisher gespeicherte, setze den Vorgänger des Nachbarknotens auf den entnommenen Knoten und die Gesamtdistanz auf die neu berechnete.
Dijkstras Algorithmus – Java-Quellcode mit PriorityQueue
Wie implementiert man Dijkstras Algorithmus am besten in Java?
Im folgenden stelle ich dir den Quellcode Schritt für Schritt vor. Den vollständigen Code findest Du in meinem GitHub-Repository. Die einzelnen Klassen sind im folgenden ebenfalls verlinkt.
Datenstruktur für den Graph: Guava ValueGraph
Als allererstes benötigen wir eine Datenstruktur, die den Graph, also die Knoten und die sie verbindenden Kanten mit ihren Gewichten speichert.
Hierfür eignet sich beispielsweise der ValueGraph der Google Core Libraries for Java. Die verschiedenen Typen von Graphen, die die Library bereitstellt, werden hier erläutert.
Einen ValueGraph, der dem Beispiel oben entspricht, können wir wie folgt erstellen (Klasse TestWithSampleGraph im GitHub-Repository):
private static ValueGraph<String, Integer> createSampleGraph() {
MutableValueGraph<String, Integer> graph = ValueGraphBuilder.undirected().build();
graph.putEdgeValue("A", "C", 2);
graph.putEdgeValue("A", "E", 3);
graph.putEdgeValue("B", "E", 5);
graph.putEdgeValue("B", "I", 15);
graph.putEdgeValue("C", "D", 3);
graph.putEdgeValue("C", "G", 2);
graph.putEdgeValue("D", "E", 1);
graph.putEdgeValue("D", "F", 4);
graph.putEdgeValue("E", "F", 6);
graph.putEdgeValue("F", "H", 7);
graph.putEdgeValue("G", "H", 4);
graph.putEdgeValue("H", "I", 3);
return graph;
}Code-Sprache: Java (java)Die Typparameter des ValueGraph sind:
- Typ der Knoten: in unserem Fall
Stringfür die Knotennamen "A" bis "I" - Typ der Kantenwerte: in unserem Fall
Integerfür die Entfernungen zwischen den Knoten
Da der Graph ungerichtet ist, spielt die Reihenfolge, in der die Knoten angegeben werden, keine Rolle.
Datenstruktur: Knoten, Gesamtdistanz und Vorgänger
Neben dem Graph benötigen wir eine Datenstruktur, die die Knoten und die zugehörige Gesamtdistanz vom Startpunkt sowie den Vorgängerknoten aufnimmt. Hierfür erstellen wir den folgenden NodeWrapper (Klasse im GitHub-Repository). Die Typvariable N ist dabei der Typ der Knoten – in unserem Beispiel wird das String sein für die Knotennamen.
class NodeWrapper<N> implements Comparable<NodeWrapper<N>> {
private final N node;
private int totalDistance;
private NodeWrapper<N> predecessor;
NodeWrapper(N node, int totalDistance, NodeWrapper<N> predecessor) {
this.node = node;
this.totalDistance = totalDistance;
this.predecessor = predecessor;
}
// getter for node
// getters and setters for totalDistance and predecessor
@Override
public int compareTo(NodeWrapper<N> o) {
return Integer.compare(this.totalDistance, o.totalDistance);
}
// equals(), hashCode()
}Code-Sprache: Java (java)Der NodeWrapper implementiert das Comparable-Interface: über die compareTo()-Methode definieren wir die natürliche Ordnung derart, dass NodeWrapper-Objekte entsprechend der Gesamtentfernung aufsteigend sortiert werden.
Der in den folgenden Abschnitten gezeigte Code bildet die findShortestPath()-Methode der Klasse DijkstraWithPriorityQueue (Klasse in GitHub).
Datenstruktur: PriorityQueue als Tabelle
Des Weiteren benötigen wir eine Datenstruktur für die Tabelle.
Hierfür wird häufig eine PriorityQueue verwendet. Die PriorityQueue hält am Kopf immer das kleinste Element bereit, welches wir mit der poll()-Methode entnehmen können. Die natürliche Ordnung der NodeWrapper-Objekte wird später dafür sorgen, dass poll() immer denjenigen NodeWrapper mit der geringsten Gesamtdistanz zurückliefert.
Tatsächlich ist die PriorityQueue nicht die optimale Datenstruktur. Ich werde sie dennoch vorerst einsetzen. Später im Abschnitt "Laufzeit mit PriorityQueue" werde ich die Performance der Implementierung messen, dann erklären, warum die PriorityQueue zu einer schlechten Performance führt – und schließlich eine besser geeignete Datenstruktur mit einer um Größenordnungen besseren Performance zeigen.
PriorityQueue<NodeWrapper<N>> queue = new PriorityQueue<>();Code-Sprache: Java (java)Datenstruktur: Lookup Map für NodeWrapper
Wir benötigen außerdem eine Map, die uns für einen Knoten des Graphen den entsprechenden NodeWrapper liefert. Hierfür eignet sich eine HashMap:
Map<N, NodeWrapper<N>> nodeWrappers = new HashMap<>();Code-Sprache: Java (java)Datenstruktur: Erledigte Knoten
Wir müssen im Verlauf des Algorithmus prüfen können, ob wir einen Knoten bereits erledigt haben, d. h. den kürzesten Weg dorthin gefunden haben. Dafür eignet sich ein HashSet:
Set<N> shortestPathFound = new HashSet<>();Code-Sprache: Java (java)Vorbereitung: Füllen der Tabelle
Kommen wir zum ersten Schritt des Algorithmus, dem Füllen der Tabelle.
Hier optimieren wir direkt ein bisschen. Wir brauchen nämlich gar nicht alle Knoten in die Tabelle zu schreiben – es reicht der Startknoten. Die weiteren Knoten schreiben wir erst dann in die Tabelle, wenn wir einen Weg dorthin finden.
Dies hat zwei Vorteile:
- Wir sparen uns Tabelleneinträge für Knoten, die vom Startpunkt entweder gar nicht erreichbar sind – oder nur über solche Zwischenknoten, die vom Startpunkt weiter entfernt sind als das Ziel.
- Wenn wir im späteren Verlauf die Gesamtdistanz eines Knotens berechnen, wird dieser in der
PriorityQueuenicht automatisch umsortiert. Stattdessen muss man den Knoten entfernen und wieder einfügen. Da für alle entdeckten Knoten die Gesamtdistanz kleiner als unendlich sein wird, werden wir dementsprechend auch alle Knoten wieder aus der Queue entfernen und sie neu einfügen müssen. Auch dies können wir uns sparen, wenn wir die Knoten in der Vorbereitungsphase gar nicht erst einfügen.
Wir verpacken also zunächst nur unseren Startknoten in ein NodeWrapper-Objekt (mit Gesamtdistanz 0 und ohne Vorgänger) und fügen dieses in die Lookup-Map und die Tabelle ein:
NodeWrapper<N> sourceWrapper = new NodeWrapper<>(source, 0, <strong>null</strong>);
nodeWrappers.put(source, sourceWrapper);
queue.add(sourceWrapper);Code-Sprache: Java (java)Iteration über alle Knoten
Kommen wir zum Herzen des Algorithmus: der schrittweisen Abarbeitung der Tabelle (bzw. der Queue, die wir als Datenstruktur für die Tabelle gewählt haben):
while (!queue.isEmpty()) {
NodeWrapper<N> nodeWrapper = queue.poll();
N node = nodeWrapper.getNode();
shortestPathFound.add(node);
// Have we reached the target? --> Build and return the path
if (node.equals(target)) {
return buildPath(nodeWrapper);
}
// Iterate over all neighbors
Set<N> neighbors = graph.adjacentNodes(node);
for (N neighbor : neighbors) {
// Ignore neighbor if shortest path already found
if (shortestPathFound.contains(neighbor)) {
continue;
}
// Calculate total distance to neighbor via current node
int distance =
graph.edgeValue(node, neighbor).orElseThrow(IllegalStateException::new);
int totalDistance = nodeWrapper.getTotalDistance() + distance;
// Neighbor not yet discovered?
NodeWrapper<N> neighborWrapper = nodeWrappers.get(neighbor);
if (neighborWrapper == <strong>null</strong>) {
neighborWrapper = new NodeWrapper<>(neighbor, totalDistance, nodeWrapper);
nodeWrappers.put(neighbor, neighborWrapper);
queue.add(neighborWrapper);
}
// Neighbor discovered, but total distance via current node is shorter?
// --> Update total distance and predecessor
else if (totalDistance < neighborWrapper.getTotalDistance()) {
neighborWrapper.setTotalDistance(totalDistance);
neighborWrapper.setPredecessor(nodeWrapper);
// The position in the PriorityQueue won't change automatically;
// we have to remove and reinsert the node
queue.remove(neighborWrapper);
queue.add(neighborWrapper);
}
}
}
// All reachable nodes were visited but the target was not found
return <strong>null</strong>;Code-Sprache: Java (java)Der Code sollte dank der Kommentare keiner weiteren Erklärung bedürfen.
Backtrace: Bestimmung des Weges vom Start zum Ziel
Wenn der aus der Queue entnommene Knoten der Zielknoten ist (Block "Have we reached the target?" in der while-Schleife oben), wird die Methode buildPath() aufgerufen. Diese folgt dem Pfad entlang der Vorgänger rückwärts vom Ziel- zum Startknoten, schreibt dabei die Knoten in eine Liste und gibt diese in umgekehrter Reihenfolge zurück:
private static <N> List<N> buildPath(NodeWrapper<N> nodeWrapper) {
List<N> path = new ArrayList<>();
while (nodeWrapper != <strong>null</strong>) {
path.add(nodeWrapper.getNode());
nodeWrapper = nodeWrapper.getPredecessor();
}
Collections.reverse(path);
return path;
}Code-Sprache: Java (java)Die vollständige findShortestPath()-Methode findest Du in der Klasse DijkstraWithPriorityQueue im GitHub-Repository. Aufrufen kannst Du die Methode dann beispielsweise so:
ValueGraph<String, Integer> graph = createSampleGraph();
List<String> shortestPath = DijsktraWithPriorityQueue.findShortestPath(graph, "D", "H");Code-Sprache: Java (java)Die createSampleGraph()-Methode hatte ich am Anfang dieses Kapitels gezeigt.
Kommen wir als nächstes zur Zeitkomplexität.
Zeitkomplexität von Dijkstras Algorithmus
Um die Zeitkomplexität des Algorithmus zu bestimmen, schauen wir uns den Code blockweise an. Im folgenden bezeichnen wir mit m die Anzahl der Kanten und mit n die Anzahl der Knoten.
- Einfügen des Startknotens in die Tabelle: Der Aufwand ist unabhängig von der Größe des Graphen, also konstant: O(1).
- Entnehmen der Knoten aus der Tabelle: Jeder Knoten wird maximal einmal aus der Tabelle entnommen. Der Aufwand hierfür hängt von der verwendeten Datenstruktur ab; wir bezeichnen ihn mit Tem ("extract minimum"). Der Aufwand für alle Knoten ist somit O(n · Tem).
- Prüfen, ob der kürzeste Pfad zu einem Knoten bereits gefunden wurde: Diese Prüfung erfolgt für jeden Knoten und alle Kanten, die von diesen wegführen. Da jede Kante an zwei Knoten anschließt, geschieht dies also maximal zweimal pro Kante, also 2m mal. Da wir für die Prüfung ein Set verwenden, erfolgt dies mit konstantem Aufwand; für 2m Knoten beträgt der Gesamtaufwand damit O(m).
- Berechnung der Gesamtdistanz: Die Gesamtdistanz wird maximal einmal pro Kante berechnet, da wir maximal einmal pro Kante einen neuen Weg zu einem Knoten finden. Die Berechnung selbst erfolgt mit konstantem Aufwand, der Gesamtaufwand für diesen Schritt ist somit auch O(m).
- Zugriff auf NodeWrapper: Auch dies passiert mit konstantem Aufwand maximal einmal pro Kante; somit haben wir auch hier O(m).
- Einfügen in die Tabelle: Jeder Knoten wird maximal einmal in die Queue eingetragen. Der Aufwand für das Eintragen hängt von der verwendeten Datenstruktur ab. Wir bezeichnen ihn mit Ti ("insert"). Der Gesamtaufwand für alle Knoten ist also O(n · Ti).
- Aktualisieren der Gesamtdistanz in der Tabelle: Dies geschieht für jede Kante maximal einmal; es gilt die gleiche Begründung wie bei der Berechnung der Gesamtdistanz. Wir haben dies im Quellcode durch Entfernen und Neueinfügen gelöst. Es gibt allerdings auch Datenstrukturen, die das in einem Schritt optimiert ausführen können. Wir bezeichnen daher den Aufwand hierfür allgemein Tdk ("decrease key"). Für m Kanten also O(m · Tdk).
Fügen wir alle Punkte zusammen, kommen wir auf:
O(1) + O(n · Tem) + O(m) + O(m) + O(m) + O(n · Ti) + O(m · Tdk)
Den konstantem Aufwand O(1) können wir vernachlässigen; ebenso wird O(m) gegenüber O(m · Tdk) vernachlässigbar. Der Term verkürzt sich somit auf:
O(n · (Tem+Ti) + m · Tdk)
Wie die Werte für Tem, Ti, Tdk für die PriorityQueue und andere Datenstrukturen lauten – und was das für die Gesamtkomplexität bedeutet, erfährst du in den folgenden Abschnitten.
Dijkstra-Algorithmus mit PriorityQueue
Für die Java-PriorityQueue gelten folgende Werte, die man der Dokumentation der Klasse entnehmen kann. (Für ein leichteres Verständnis gebe ich die T-Parameter hier mit voller Schreibweise an.)
- Kleinsten Eintrag entnehmen mit
poll(): TextractMinimum = O(log n) - Wert einfügen mit
offer(): Tinsert = O(log n) - Gesamtdistanz verringen mit
remove()undoffer(): TdecreaseKey = O(n) + O(log n) = O(n)
Setzen wir diese Werte in die Formel von oben ein – Tem+Ti = log n + log n können wir dabei zu einmal log n zusammenfassen – dann ergibt sich:
O(n · log n + m · n)
Für den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist – in Landau-Notation: m ∈ O(n) – können m und n bei der Betrachtung der Zeitkomplexität gleichgesetzt werden. Dann vereinfacht sich die Formel zu O(n · log n + n²). Der quasilineare Anteil kann neben dem quadratischen vernachlässigt werden, und es bleibt:
O(n²) – für m ∈ O(n)
Genug der Theorie ... im nächsten Abschnitt prüfen wir unsere Annahme in der Praxis!
Laufzeit mit PriorityQueue
Um zu prüfen, ob die theoretisch bestimmte Zeitkomplexität korrekt ist, habe ich das Programm TestDijkstraRuntime geschrieben. Dieses erstellt zufällige Graphen verschiedener Größen von 10.000 bis etwa 300.000 Knoten und sucht darin den kürzesten Weg zwischen zwei zufällig ausgewählten Knoten.
Die Graphen enthalten jeweils viermal so viele Kanten wie Knoten. Dies soll einer Straßenkarte nahe kommen, auf der im Mittel grob geschätzt vier Straßen von jeder Kreuzung wegführen.
Jeder Test wird 50 mal wiederholt; folgende Grafik zeigt den Median der gemessenen Zeiten im Verhältnis zur Graphengröße:
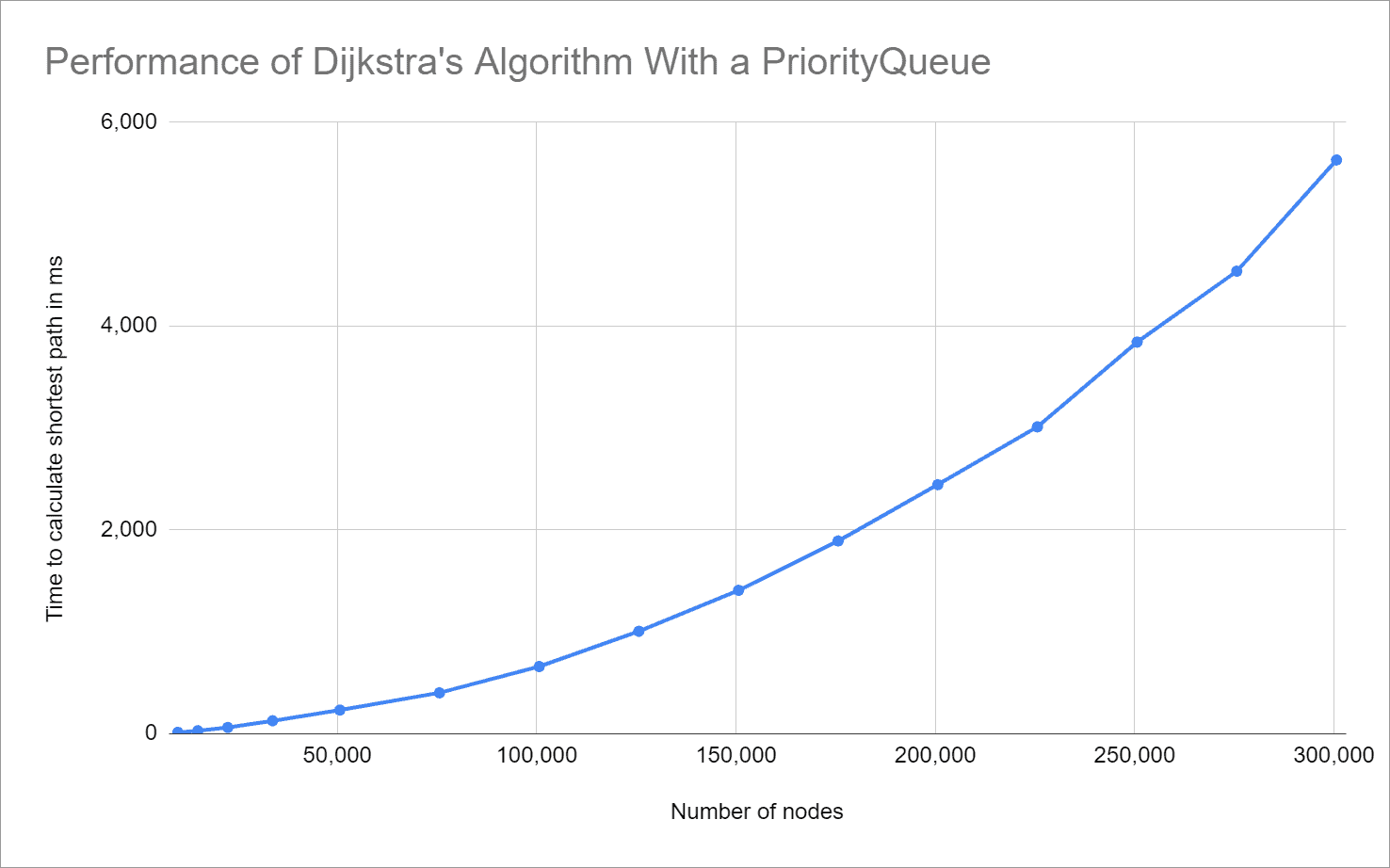
Das vorhergesagte quadratische Wachstum ist gut zu erkennen – unsere Herleitung der Zeitkomplexität von O(n²) war also korrekt.
Dijkstra-Algorithmus mit TreeSet
Wir haben bei der Bestimmung der Zeitkomplexität erkannt, dass die PriorityQueue.remove()-Methode eine Zeitkomplexität von O(n) hat. Dies führt für den Gesamtalgorithmus zu quadratischem Aufwand.
Eine besser geeignete Datenstruktur ist das TreeSet. Dieses bietet uns mit der pollFirst()-Methode ebenfalls eine Möglichkeit das kleinste Element zu entnehmen. Für das TreeSet gelten laut Dokumentation folgende Laufzeiten:
- Kleinsten Eintrag entnehmen mit
pollFirst(): TextractMinimum = O(log n) - Wert einfügen mit
add(): Tinsert = O(log n) - Gesamtdistanz verringen mit
remove()undadd(): TdecreaseKey = O(log n) + O(log n) = O(log n)
Setzen wir diese Werte in die allgemeine Formel O(n · (Tem+Ti) + m · Tdk) ein, erhalten wir:
O(n · log n + m · log n)
Betrachten wir wieder den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist, m und n also gleichgesetzt werden können, kommen wir auf:
O(n · log n) – für m ∈ O(n)
Bevor wir dies in der Praxis überprüfen, zunächst noch ein paar Anmerkungen zum TreeSet.
Nachteil des TreeSet
Das TreeSet ist beim Hinzufügen und Entnehmen von Elementen etwas langsamer als die PriorityQueue, da es intern eine TreeMap verwendet. Diese wiederum arbeitet mit einem Rot-Schwarz-Baum, welcher mit Knotenobjekten und Referenzen arbeitet, während der in der PriorityQueue verwendete Heap auf ein Array gemappt ist.
Bei ausreichend großen Graphen fällt dies jedoch nicht mehr ins Gewicht, wie wir in den folgenden Messungen sehen werden.
TreeSet verletzt die Interface-Definition!
Eine Sache müssen wir beim Einsatz des TreeSets beachten: Es verletzt die Schnittstellendefinition der remove()-Methode sowohl des Collection- als auch des Set-Interfaces!
Und zwar prüft das TreeSet auf Gleichheit zweier Objekte nicht – wie in Java sonst üblich und wie in der Interface-Methode spezifiziert – mittels der equals()-Methode, sondern über Comparable.compareTo() – bzw. Comparator.compare() bei Verwendung eines Comparators. Zwei Objekte werden als gleich angesehen, wenn compareTo() bzw. compare() 0 zurückliefert.
Dies ist beim Löschen von Elementen in zweierlei Hinsicht relevant:
- Wenn es mehrere Knoten mit derselben Gesamtdistanz gibt, könnte beim Versuch solch einen Knoten zu entfernen "versehentlich" ein anderer Knoten mit gleicher Gesamtdistanz entfernt werden.
- Wichtig ist außerdem, dass wir den Knoten entfernen, bevor wir dessen Gesamtdistanz ändern. Ansonsten wird die
remove()-Methode ihn nicht mehr finden.
Implementierung: NodeWrapperForTreeSet
Deshalb müssen wir für die Verwendung eines TreeSets die compareTo()-Methode dahingehend erweitern, dass sie bei gleicher Gesamtdistanz auch noch den Knoten vergleicht.
Da dazu auch die Knoten (und damit der Typparameter N) das Interface Comparable implementieren müssen, legen wir eine neue Klasse NodeWrapperForTreeSet an (Klasse im GitHub-Repository):
class NodeWrapperForTreeSet<N extends Comparable<N>>
implements Comparable<NodeWrapperForTreeSet<N>> {
// fields, constructors, getters, setters
@Override
public int compareTo(NodeWrapperForTreeSet<N> o) {
int compare = Integer.compare(this.totalDistance, o.totalDistance);
if (compare == 0) {
compare = node.compareTo(o.node);
}
return compare;
}
// equals(), hashCode()
}Code-Sprache: Java (java)Des weiteren müssen wir sicherstellen, dass wir als Knotentyp nur solche Klassen verwenden, bei denen compareTo() genau dann 0 liefert, wenn auch equals() die Objekte als gleich wertet. In unseren Beispielen verwenden wir String, was diese Forderung erfüllt.
Vollständiger Code in GitHub
Den Algorithmus mit TreeSet findest du in der Klasse DijkstraWithTreeSet im GitHub-Repository. Dieser unterscheidet sich in nur wenigen Punkten von DijkstraWithPriorityQueue:
- Der Knotentyp
NerweitertComparable<N>. - Statt der
PriorityQueuewird einTreeSeterstellt. - Das erste Element wird mit
pollFirst()entnommen anstatt mitpoll(). - Statt
NodeWrapperwirdNodeWrapperForTreeSetverwendet.
Sollten wir nicht Code-Duplikation vermeiden und die gemeinsame Funktionalität in einer einzigen Klasse unterbringen? Ja, wenn beide Varianten in der Praxis eingesetzt werden sollen. Hier sollen aber lediglich beide Ansätze verglichen werden.
Laufzeit mit TreeSet
Um die Laufzeit zu messen, brauchen wir nur in TestDijkstraRuntime in Zeile 71 die Klasse DijkstraWithPriorityQueue durch DijkstraWithTreeSet zu ersetzen.
Der folgende Graph zeigt das Testergebnis im Vergleich zur vorherigen Implementierung:

Das erwartete quasilineare Wachstum ist gut zu erkennen, die Zeitkomplexität ist wie vorhergesagt O(n · log n).
Dijkstra-Algorithmus mit Fibonacci-Heap
Eine noch besser geeignete, im JDK allerdings nicht verfügbare Datenstruktur ist der Fibonacci-Heap. Dessen Operationen weisen folgenden Laufzeiten auf:
- Kleinsten Eintrag entnehmen: TextractMinimum = O(log n)
- Wert einfügen: Tinsert = O(1)
- Gesamtdistanz verringen: TdecreaseKey = O(1)
In die allgemeine Formel O(n · (Tem+Ti) + m · Tdk) eingesetzt, ergibt das:
O(n · log n + m)
Für den Spezialfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist, kommen wir wie beim TreeSet auf quasilinearen Aufwand:
O(n · log n) – für m ∈ O(n)
Laufzeit mit Fibonacci-Heap
Mangels passender Datenstruktur im JDK, habe ich die Fibonacci-Heap-Impementierung von Keith Schwarz verwendet. Da ich den Code nicht einfach kopieren wollte, habe ich den entsprechenden Test nicht in mein GitHub-Repository hochgeladen. Das Ergebnis siehst du hier im Vergleich zu den zwei vorherigen Tests:

Dijkstras Algorithmus ist mit Fibonacci-Heap also noch einmal einen Tick schneller als mit dem TreeSet.
Zeitkomplexität – Zusammenfassung
In der folgenden Tabelle findest du eine Übersicht der Zeitkomplexität von Dijkstras Algorithmus in Abhängigkeit der verwendeten Datenstruktur. Dijkstra selbst hatte den Algorithmus übrigens mit einem Array implementiert, dieses habe ich der Vollständigkeithalber ebenfalls mit aufgeführt:
| Datenstruktur | Tem | Ti | Tdk | Zeitkomplexität allgemein | Zeitkomplexität für m ∈ O(n) |
|---|---|---|---|---|---|
| Array | O(n) | O(1) | O(1) | O(n² + m) | O(n²) |
| PriorityQueue | O(log n) | O(log n) | O(n) | O(n · log n + m · n) | O(n²) |
| TreeSet | O(log n) | O(log n) | O(log n) | O(n · log n + m · log n) | O(n · log n) |
| FibonacciHeap | O(log n) | O(1) | O(1) | O(n · log n + m) | O(n · log n) |
Zusammenfassung und Ausblick
Dieser Artikel hat an einem Beispiel, mit einer informellen Beschreibung und mit Java-Quellcode gezeigt, wie Dijkstras Algorithmus funktionert.
Für die Zeitkomplexität wurde zunächst eine allgemeine Landau-Notation hergeleitet, und diese wurde für die Datenstrukturen PriorityQueue, TreeSet und FibonacciHeap konkretisiert.
Nachteil des Dijkstra-Algorithmus
Der Algorithmus hat allerdings ein Manko: Er folgt den Kanten in alle Richtungen, unabhängig davon, in welcher Richtung der Zielknoten liegt. Das Beispiel in diesem Artikel war recht klein, so dass dies nicht aufgefallen ist.
Schau dir einmal folgende Straßenkarte an:

Die Strecken von A nach D und von D nach H sind Schnellstraßen; von D nach E führt ein schwer passierbarer Feldweg. Wenn wir jetzt von D nach E kommen wollen, sehen wir sofort, dass wir keine andere Wahl haben als diesen Feldweg zu nehmen.
Doch was macht der Dijkstra-Algorithmus?
Da dieser sich ausschließlich an Kantenlängen orientiert, prüft er die Knoten C und F (Gesamtdistanz 2), B und G (Gesamtdistanz 4) und A und H (Gesamtdistanz 6), bevor er sicher ist, keinen kürzeren Weg zu H zu finden als den direkten Weg mit der Länge 5.
Vorschau: A*-Suchalgorithmus
Es gibt eine Weiterentwicklung des Dijkstra-Algorithmus, die mit Hilfe einer Heuristik das Prüfen von Pfaden in die falsche Richtung vorzeitig beendet und trotzdem deterministisch den kürzesten Weg findet: der A*-Algorithmus (ausgesprochen "A Stern" oder englisch "A Star"). Diesen stelle ich im nächsten Teil der Artikelserie vor.