


Compact Object Headers in Java
(JEP 519)
Jedes Java-Objekt hat im Speicher einen den eigentlichen Daten vorangestellten Objekt-Header. Dieser enthält vor allem den Hash-Code des Objekts und die Information, von welcher Klasse das Objekt eine Instanz ist.
Der Objekt-Header ist zum Stand von Java 26 standardmäßig 96 Bit (12 Byte) groß – oder 128 Bit (16 Byte), wenn Compressed Class Pointers ausgeschaltet werden (wozu es aber nahezu keinen Grund gibt – weshalb diese Option in Java 25 als deprecated markiert und in Java 27 abgeschafft wurde).
Im Rahmen von Project Lilliput tüfteln die JDK-Entwickler:innen seit vielen Jahren an Möglichkeiten, um den Header auf insgesamt 64 Bit oder sogar auf 32 Bit zu komprimieren.
Im Jahr 2025 war es dann so weit: In Java 24 wurden Compact Object Headers durch JDK Enhancement Proposal 450 als experimentelles Feature eingeführt – und in Java 25 durch JDK Enhancement Proposal 519 finalisiert. Compact Object Headers ermöglichen es, den Objekt-Header von 96 Bit auf 64 Bit zu komprimieren und damit die Heap-Größe bestehender Anwendungen deutlich zu reduzieren.
In diesem Artikel erfährst du:
- Wie funktioniert die Header-Komprimierung?
- Warum wird dadurch nicht nur der Speicherbedarf reduziert, sondern auch die Anwendungsperformance erhöht?
- Was es mit dem neuen „Self Forwarded Tag" auf sich hat
- Wie du Compact Object Headers aktivierst – und ab welcher Java-Version sie standardmäßig aktiv sind
Status Quo vor Compact Object Headers
Eine detaillierte Beschreibung des Aufbaus von Objekt-Headern findest du im Hauptartikel über Java Objekt-Header. Hier das Wichtigste zusammengefasst:
In der Regel besteht der Objekt-Header aus einem 64-Bit „Mark Word“ und einem 32-Bit „Class Word“. Mark Word und Class Word sind wie folgt aufgebaut:
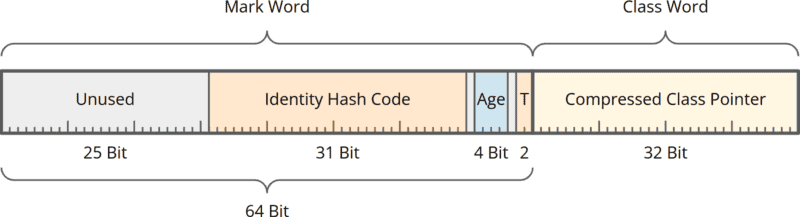
Das Mark Word enthält:
- einen 31-Bit Identity Hash Code (der beim Aufruf von
System.identityHashCode(Object)zurückgegeben wird), - 4 Bits, in denen der Garbage Collector das Alter eines Objekts speichert (anhand dessen er entscheidet, wann ein Objekt von der jungen in die alte Generation verschoben wird),
- 2 „Tag Bits“, die anzeigen, ob das Objekt nicht, uncontended (ohne wartende Threads) oder contended (mit wartenden Threads) gelockt ist.
Das Class Word enthält einen 32-Bit-Offset in den maximal 4 GB großen Compressed Class Space, der auf die sogenannte Klass-Datenstruktur zeigt, welche alle relevanten Daten über die Klasse enthält.
Vom Compressed Class Pointer zum Compact Object Header
Wie können wir den Objekt-Header weiter komprimieren?
Zunächst einmal enthält das Mark Word (wie man oben sieht) aktuell 27 ungenutzte Bits (25 am Anfang und jeweils eines vor und nach den „Age Bits“). Von den 96 Bits des gesamten Objekt-Headers werden also nur 96 - 27 = 69 Bits benötigt. Um auf 64 Bit zu kommen, müssen wir also irgendwie fünf Bits einsparen.
Wo können wir die hernehmen?
Die JDK-Entwickler:innen haben lange experimentiert, bis sie zu folgender Lösung kamen (ich habe für eine bessere Darstellung den Maßstab geändert – die 64 Bit ziehen sich jetzt über die gesamte Breite):
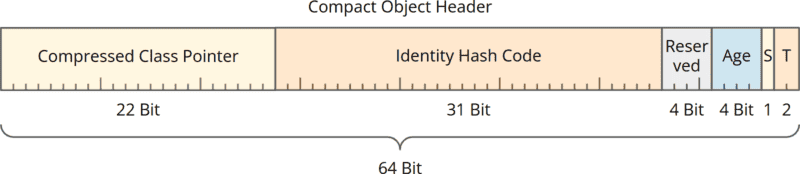
Der neue 64 Bit-Header wird nicht mehr in Mark Word und Class Word aufgeteilt, sondern enthält direkt die folgenden Informationen:
- einen von 32 Bit auf 22 Bit weiter komprimierten Class Pointer (wird unten erklärt),
- den 31-Bit Identity Hash Code (unverändert),
- 4 für Project Valhalla reservierte Bits (neu),
- 4 Bits für das Alter des Objekts (unverändert),
- 1 Bit für das sogenannte „Self Forwarded Tag“ (wird unten erklärt),
- 2 Tag Bits (unverändert).
Der Class Pointer wurde also um 10 Bits verkleinert. Da wir nur fünf Bits einsparen mussten, stehen nun fünf zusätzliche Bits zur Verfügung. Vier davon wurden für Project Valhalla reserviert, und in einem Bit wird das neue „Self Forwarded Tag“ gespeichert.
Wie konnte der Class Pointer auf 22 Bit komprimiert werden?
Mit den bisherigen 32 Bit konnte jede Position innerhalb des 4 GB großen Compressed Class Space einzeln adressiert werden.
Der Einfachheit halber stelle ich das in der folgenden Grafik mit einem 256 Byte großen Speicherbereich dar:

Wie du siehst, brauchen wir die Zahlen 0 bis 255, um jede einzelne Position des Speicherbereichs zu adressieren. Dafür brauchen wir einen 8-Bit-Pointer (28 = 256).
Doch müssen wir wirklich jede einzelne Position adressieren können? Nein, das müssen wir nicht!
Genau wie eine Festplatte (egal ob eine herkömmliche oder eine SSD) in sogenannte (in der Regel 4 KB große) Blöcke aufgeteilt ist, können wir auch den Speicherbereich für die Klassendaten in Blöcke aufteilen. So muss nicht mehr jedes einzelne Byte adressiert werden, sondern nur noch jeder Block. Und so können wir mit deutlich weniger Bits den gleichen Speicherbereich adressieren.
Hier wieder das vereinfachte Beispiel, in dem ich den 256 Byte großen Speicherbereich in 32 Blöcke zu je 8 Byte aufteile:

Jetzt brauchen wir nur noch die Zahlen 0 bis 31, um den gleichen Speicherbereich zu adressieren. Dafür brauchen wir nur noch 5 Bit große Pointer (25 = 32). Durch Aufteilung in Blöcke konnten wir den Speicherbedarf pro Pointer von 8 Bit auf 5 Bit reduzieren.
Und das funktioniert auch mit dem Speicherbereich, in dem die Klassen-Informationen liegen.
Bei der Verwendung von Compact Object Headers wird dieser Speicherbereich in 1.024 (= 210) Byte große Blöcke aufgeteilt. Dieser Wert wurde gewählt, da die meisten Klassen zwischen einem halben und einem Kilobyte belegen.
Zur Erinnerung: der Bereich ist 4 GB groß. Entsprechend ergeben sich 4 × 1.024 × 1.024 × 1.024 / 1.024 Blöcke, also 4 × 1.024 × 1.024, das sind 4.194.304, oder 222 Blöcke. Und diese können wir mit 22 Bit adressieren!
Um aus einer 22-Bit-Blocknummer einen Pointer zu machen, müssen wir die 22 Bit lediglich um 10 Bit nach links schieben und die hinteren 10 Bit mit Nullen auffüllen, und damit haben wir wieder einen 32-Bit-Pointer in den 4 GB großen Speicherbereich:

Die Aufteilung in Blöcke führt nun zu einer Fragmentierung bei den Klassendaten. Doch auch das haben die JDK-Entwickler:innen bedacht: der zwischen den Klassen liegende Speicher kann auch von anderen Datenstrukturen des Metaspace genutzt werden.
Was ist das „Self Forwarded Tag“?
Wenn ein Garbage Collector ein Objekt an eine neue Speicheradresse kopiert, ersetzt er im ursprünglichen Objekt die oberen 62 Bit des Mark Words durch einen Pointer auf die neue Speicheradresse und setzt die Tag-Bits auf 0b11. Das ursprüngliche Mark Word findet er dann an der neuen Adresse.
Wenn der Kopiervorgang fehlschlägt, wird das Mark Word durch einen Pointer auf das Objekt selbst ersetzt. Dadurch gehen Identity Hash Code und Alter des Objekts verloren, das scheint aber verschmerzbar zu sein (ich konnte leider keine verlässliche Information darüber finden, warum das der Fall ist, werde diesen Absatz aber aktualisieren, sollte ich eine Aussage hierzu finden).
Wenn wir allerdings einen Compact Object Header durch eine Selbst-Referenz ersetzen würden, dann würde auch der Class-Pointer verloren gehen. Da dieser essentiell ist, darf ein Compact Object Header eben nicht durch solch eine Selbst-Referenz ersetzt werden.
Stattdessen wird das neue „Self Forwarded Tag“-Bit gesetzt.
Fazit zu Compact Object Headers
Compact Object Headers reduzieren den Speicherbedarf eines Java-Programms signifikant, indem die Objekt-Header von 96 Bits (12 Bytes) auf 64 Bit (8 Bytes) reduziert werden. Der JEP selbst spricht von einer Reduktion des Heap-Verbrauchs um 10–20 %, Amazon spricht sogar von 22 %, Alibaba nennt Werte zwischen 5 und 10 %.
Und nicht nur das – dadurch, dass die Objekte kleiner sind, passen auch mehr Objekte in den CPU-Cache. So kommt es zu weniger Cache-Misses – und das wirkt sich zusätzlich positiv auf die Performance aus. Amazon hat 8 bis 11 % mehr Durchsatz gemessen, Reddit-Nutzer „plokhotnyuk“ hat in einem JSON-Benchmark 10 % mehr Durchsatz gemessen, und Alibaba berichtet von 6-9 % mehr Durchsatz.
Ab Java 25 können Compact Object Headers mit folgender VM-Option aktiviert werden:
-XX:+UseCompactObjectHeaders
In Java 24 befanden sich Compact Object Headers noch im experimentellen Stadium und mussten wie folgt aktiviert werden:
-XX:+UnlockExperimentalVMOptions -XX:+UseCompactObjectHeaders
Ausblick
In Java 27 werden Compact Object Headers per JEP 534 standardmäßig aktiviert sein; bei Bedarf werden sie sich dann mit -XX:-UseCompactObjectHeaders abschalten lassen.
Als nächstes arbeiten die Project-Lilliput-Entwickler:innen an 4-Byte-Headern – also einer weiteren Halbierung der Header-Größe! Für diese weitere Reduzierung müssen wir wahrscheinlich Leistungseinbußen in Kauf nehmen. Der JEP-Entwurf „4-byte Object Headers“ strebt eine maximale Durchsatz- und Latenzreduzierung von 5 % an. Wie die Komprimierung auf vier Byte erreicht werden soll, ist im JEP-Entwurf noch nicht beschrieben.
Hast du Compact Object Headers bereits getestet? Hat es die erwarteten Verbesserungen gebracht? Teile deine Erfahrung in den Kommentaren!