


Java 27 Features
(mit Beispielen)
Java 27 befindet sich seit dem 4. Juni 2026 in der sogenannten „Rampdown Phase One“, d. h. es werden keine weiteren JDK Enhancement Proposals (JEPs) in das Release aufgenommen. Das Feature-Set steht also fest. Es werden nur noch Bugs gefixt und ggf. kleinere Verbesserungen durchgeführt.
Als Veröffentlichungsdatum ist der 14. September 2026 angepeilt. Die aktuelle Early-Access-Version kannst du hier herunterladen.
Java 27 ist – wie schon Java 26 – ein sehr überschaubares Release: Es enthält lediglich neun JEPs. Mehr als die Hälfte davon sind wiedervorgelegte Preview- und Incubator-Features: drei mit kleinen Änderungen (Lazy Constants, Structured Concurrency und PEM Encodings) und zwei ganz ohne Änderungen (Primitive Type Patterns und die Vector API).
Vier Features sind neu: Compact Object Headers sind ab Java 27 standardmäßig aktiviert; G1 ist auch auf kleinen Instanzen der Default Garbage Collector; TLS unterstützt jetzt quantensichere Verschlüsselung, und der Java Flight Recorder kann vertrauliche Informationen in Umgebungsvariablen, System Properties und Programmargumenten schwärzen.
Für alle JEPs und Änderungen aus den Release Notes verwende ich wie immer die originalen, englischen Bezeichnungen.
Compact Object Headers by Default – JEP 534
Compact Object Headers (von 96 auf 64 Bit komprimierte Objekt-Header) wurden in Java 24 als experimentelles Feature eingeführt. In Java 25 wurden sie zu einem produktiven Feature, mussten aber noch explizit mit -XX:+UseCompactObjectHeaders aktiviert werden.
In Java 27 werden sie durch JDK Enhancement Proposal 534 standardmäßig aktiviert. Sie können aktuell noch mit -XX:-UseCompactObjectHeaders deaktiviert werden – diese Option wird aber in einer zukünftigen Java-Version entfernt werden.
Herkömmliche Objekt-Header: 96 Bit / 12 Byte
Jedes Java-Objekt besteht im Speicher aus zwei Teilen: dem Objekt-Header und den eigentlichen Nutzdaten. Der Objekt-Header war bisher in zwei Teile aufgeteilt: das Mark Word (auch als Lock Word bezeichnet) und das Class Word.
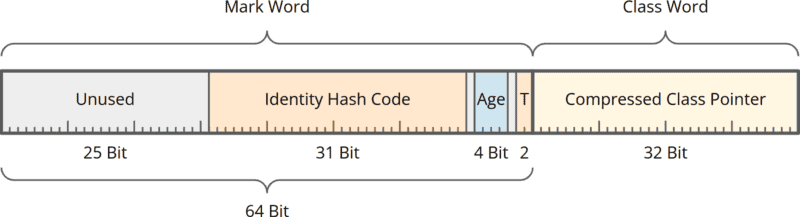
Das Mark Word enthielt:
- den Identity Hash Code (der von
System.identityHashCode()zurückgegebene Wert), - das Objekt-Alter (vom Garbage Collector verwendet, um zu entscheiden, wann ein Objekt von der Young Generation in die Old Generation verschoben wird),
- zwei Lock-Bits, die u. a. für das
synchronized-Locking verwendet werden, - insgesamt 27 ungenutzte Bits (25 am Anfang und je eines vor und nach den vier Age-Bits).
Das Class Word enthielt einen 32-Bit-Offset zu den Klassen-Metadaten im sogenannten Compressed Class Space. Durch das Class Word weiß die JVM von welcher Klasse ein Objekt ist.
Compact Object Headers: 64 Bit / 8 Byte
Im neuen kompakten Objekt-Header sind Mark Word und Class Word zu einem einzigen 64-Bit-Wert verschmolzen.
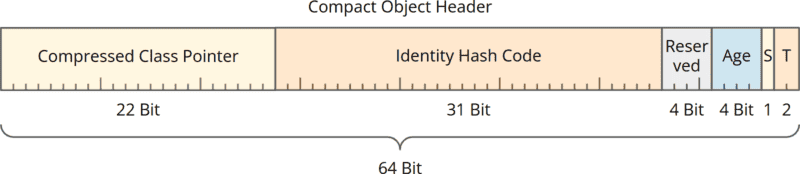
Dieser enthält unverändert:
- 31 Bit für den Identity Hash Code,
- 4 Bit für das Objekt-Alter,
- und die zwei Lock-Bits.
Die 27 zuvor ungenutzten Bits werden im kompakten Header wie folgt belegt:
- 22 Bit durch einen komprimierten Class Pointer (dadurch fällt das Class Word weg; wie genau der Class Pointer von 32 Bit auf 22 Bit gekürzt werden konnte, kannst du im Hauptartikel über Compact Object Headers nachlesen),
- 1 Bit für das neue Self-Forwarded-Bit (auch darüber erfährst du mehr im zuvor genannten Hauptartikel)
- 4 Bit werden für Project Valhalla (Value Classes) reserviert.
Durch die standardmäßige Aktivierung von Compact Object Headers wird der Heap-Verbrauch bei einem Upgrade auf Java 27 – insbesondere bei Anwendungen mit vielen kleinen Objekten – um ca. 10–20 % reduziert und der Durchsatz um ca. 5–10 % erhöht.
JFR In-Process Data Redaction – JEP 536
Wird eine Java-Anwendung mit aktiviertem JDK Flight Recorder gestartet (dem in die JVM integrierten Monitoring- und Profiling-Tool), zeichnet dieser u. a. die Umgebungsvariablen, die System Properties und die Programm-Argumente mit auf.
Oft werden jedoch vertrauliche Informationen – wie Access Tokens für APIs oder Passwörter für Datenbanken oder Keystores – über Umgebungsvariablen, System Properties oder Programm-Argumente an die Anwendung übergeben, wie in folgendem Beispiel:
$ export ACCESS_TOKEN=SECRET_ACCESS_TOKEN
$ java -XX:StartFlightRecording:filename=recording.jfr \
-Djavax.net.ssl.keyStorePassword=SECRET_KEYSTORE_PASSWORD \
-jar application.jar \
--dbpassword SECRET_DATABASE_PASSWORDCode-Sprache: Bash (bash)Ein Angreifer mit Zugriff auf die Flight-Recorder-Aufzeichnung könnte Token und Passwörter problemlos aus der Aufzeichnung extrahieren.
Um das zu verhindern, wird ab Java 27 alles, was wahrscheinlich ein Token oder ein Passwort ist, automatisch in der JFR-Aufzeichnung geschwärzt (englisch: redacted) und erscheint als [REDACTED].
Woher weiß der Flight Recorder, was ein Token oder ein Passwort ist?
Standardkonfiguration
Standardmäßig schwärzt der Flight Recorder alle Umgebungsvariablen oder System Properties mit einem Key, der auf eines der folgenden Pattern matcht (Groß-/Kleinschreibung wird dabei ignoriert, und das Sternchen ist ein Platzhalter für beliebige andere Zeichen):
*api*key*
*auth*
*client*secret*
*credential*
*jaas*config*
*jwt*
*passphrase*
*passwd*
*password*
*private*key*
*pwd*
*secret*
*token*Code-Sprache: Klartext (plaintext)Zudem werden alle Programm-Argumente (oder Paare von Programm-Argumenten) geschwärzt, die auf eines der folgenden Pattern matchen (ein Leerzeichen steht dabei für das Leerzeichen zwischen zwei aufeinanderfolgenden Argumenten):
-*api*key *
-*client*secret *
-*credential *
-*jaas*config *
-*jwt *
-*passphrase *
-*passwd *
-*password *
-*private*key *
-*pwd *
-*secret *
-*token *
*api*key*
*client*secret*
*credential*
*jaas*config*
*passphrase*
*passwd*
*password*
*private*key*
*pwd*
*secret*
*token*Code-Sprache: Klartext (plaintext)Im Beispiel zu Beginn des Abschnitts wurden die folgenden sensitiven Informationen beim Programmstart angegeben:
- eine Umgebungsvariable mit dem Key
ACCESS_TOKEN– diese matcht auf*token*und wird daher ab Java 27 geschwärzt, - die System Property
javax.net.ssl.keyStorePassword– diese matcht auf*password*und wird daher geschwärzt - und das Programm-Argument-Paar
--dbpassword SECRET_DATABASE_PASSWORD– dieses matcht auf-*password *und wird daher ebenfalls geschwärzt.
Diese Pattern matchen bewusst großzügig – im Zweifel wird lieber zu viel als zu wenig geschwärzt. Das kann auch harmlose Werte treffen: Eine Umgebungsvariable namens TOKEN_REFRESH_INTERVAL etwa enthält kein Geheimnis, matcht aber auf *token* und erscheint dementsprechend als [REDACTED]. Falls dich die Schwärzung eines konkreten, unkritischen Werts stört, kannst du die beiden Listen über die im Folgenden gezeigten Parameter redact-key und redact-argument gezielt einschränken.
Änderung der Standardkonfiguration
Die Konfiguration, was geschwärzt werden soll, kann auch geändert werden:
- Mit dem JFR-Parameter
redact-keykönnen wir die erste der zwei oben gezeigten Listen (die Pattern für Environment Variablen und System Properties) überschreiben oder erweitern. - Mit dem JFR-Parameter
redact-argumentkönnen wir die zweite der oben gezeigten Listen (die Pattern für Programm-Argumente) überschreiben oder erweitern.
Wenn wir beispielsweise nur den Key ACCESS_TOKEN und die System Property javax.net.ssl.keyStorePassword schwärzen wollten, könnten wir den Flight Recorder wie folgt starten:
java -XX:FlightRecorderOptions:'redact-key=ACCESS_TOKEN;*keyStorePassword' ...
Alternativ könnten wir eine Text-Datei erstellen, die die zwei Keys in je einer Zeile enthält. Hieße diese Datei beispielsweise keys.txt, dann könnten wir auch den Namen dieser Datei – mit einem @ voran – angeben:
java -XX:FlightRecorderOptions:'redact-key=@keys.txt' ...
Wenn wir die Standard-Schwärzungslisten nicht ersetzen, sondern erweitern wollen, können wir der Liste von Keys (oder dem Dateinamen) ein + voranstellen, z. B. so:
java -XX:FlightRecorderOptions:'redact-key=+*confidential*' ...
In diesem Fall würden alle Environment Variablen oder System Properties geschwärzt werden, die entweder auf ein Pattern aus der Standardliste matchen oder die den Begriff „confidential“ enthalten.
Schwärzen ausschalten
Um das vorherige Verhalten wiederherzustellen, können wir das Schwärzen durch Angabe von „none“ vollständig deaktivieren:
java -XX:FlightRecorderOptions:'redact-key=none,redact-argument:none' ...
Damit werden Umgebungsvariablen, System Properties und Programm-Argumente wieder uneingeschränkt aufgezeichnet.
Die JFR In-Process Data Redaction ist in JDK Enhancement Proposal 536 spezifiziert.
Post-Quantum Hybrid Key Exchange for TLS 1.3 – JEP 527
In Java 24 wurden Algorithmen zur quantensicheren Schlüsselkapselung (Key Encapsulation) und für quantensichere digitale Signaturen eingeführt.
Warum schon jetzt? Es gibt zwar aktuell noch keine Quantencomputer, die heutige Verschlüsselungsverfahren brechen können – aber ein Angreifer könnte schon heute verschlüsselten Datenverkehr mitschneiden und speichern – um ihn Jahre später, sobald ausreichend leistungsfähige Quantencomputer bereitstehen, zu entschlüsseln. Dieses Szenario nennt man „Harvest now, decrypt later“. Alles, was du heute klassisch verschlüsselt überträgst, ist damit potenziell gefährdet.
Java 27 fügt nun quantensichere Verschlüsselung für TLS (den Nachfolger von SSL) hinzu – und zwar in Form von sogenanntem hybridem Schlüsselaustausch (englisch: hybrid key exchange). Hybrider Schlüsselaustausch bedeutet, dass mehrere Schlüsselaustauschverfahren kombiniert werden – und der Schlüsselaustausch selbst dann noch sicher ist, wenn alle der verwendeten Verfahren bis auf eines geknackt wurden.
In der Java-Implementierung wird je ein ECDHE-Algorithmus (nicht quantensicher) mit einem ML-KEM-Algorithmus (quantensicher) kombiniert – in drei Varianten mit jeweils unterschiedlichen Schlüssellängen.
Sofern vom Server unterstützt, setzt Java 27 den neuen, quantensicheren Schlüsselaustausch automatisch ein – ohne dass es einer speziellen Konfiguration bedarf. So lässt sich aufgezeichneter Datenverkehr auch mit einem künftigen Quantencomputer nicht mehr entschlüsseln.
Welche Varianten der Algorithmen genau eingesetzt werden – und wie du beim Aufbau einer TLS-Verbindung die Standard-Algorithmen-Auswahl von Java überschreiben kannst, kannst du in JDK Enhancement Proposal 527 nachlesen.
Make G1 the Default Garbage Collector in All Environments – JEP 523
Der G1 Garbage Collector ist seit Java 9 der Default-Garbage-Collector – in der Regel. Eine Ausnahme galt bisher für leistungsschwache Maschinen mit entweder nur einer CPU oder weniger als 1.792 MB RAM. Auf solchen Maschinen wurde standardmäßig der Serial GC aktiviert, da dieser mit diesen begrenzten Ressourcen einen signifikant höheren Durchsatz und niedrigeren Speicherverbrauch hatte als der G1.
Durch die kontinuierlichen Verbesserungen am G1 – zuletzt durch die Verbesserungen des Durchsatzes in Java 26 – erreicht der G1 auch auf leistungsschwächeren Maschinen nun annähernd den Durchsatz des Serial GC.
Da die Latenzen des G1 grundsätzlich besser sind als die des Serial GC, entschied das JDK-Team nun, die Ausnahmeregel für leistungsschwache Maschinen zu entfernen und den G1 in allen Umgebungen – unabhängig von CPU-Anzahl und Speichergröße – zum Default-Garbage-Collector zu machen.
Es ist nicht geplant, den Serial GC zu entfernen; dieser kann (genau wie zuvor dort, wo er nicht standardmäßig ausgewählt wurde) über -XX:+UseSerialGC aktiviert werden.
Die Änderung ist in JDK Enhancement Proposal 523 spezifiziert.
Wiedervorgelegte Preview- und Incubator-Features
In Java 27 werden die folgenden vier Preview-Features sowie ein Incubator-Feature wiedervorgelegt – teilweise mit kleineren Änderungen, teilweise ganz ohne Änderungen.
Lazy Constants (Third Preview) – JEP 531
Lazy Constants kennst du vielleicht noch unter einem anderen Namen: In Java 25 wurden sie als Stable Values eingeführt. In Java 26 hat das JDK-Team die API nach reichlich Feedback deutlich abgespeckt und in Lazy Constants umbenannt (JEP 526).
Wenn du Lazy Constants bereits aus den Vorgängerversionen kennst und nur wissen willst, was sich in Java 27 ändert, springe direkt zum Abschnitt Lazy Constants – Änderungen in Java 27.
Welches Problem lösen Lazy Constants?
Konstanten – also Werte, die sich nach ihrer Initialisierung nicht mehr ändern – bringen gleich mehrere Vorteile mit: Der Code wird einfacher und sicherer, denn eine Konstante kennt nur einen einzigen Zustand und lässt sich gefahrlos aus mehreren Threads heraus lesen. Zudem kann die JVM den Zugriff auf sie durch sogenanntes Constant Folding optimieren.
Bisher gibt es nur einen Weg, eine Konstante zu definieren – über ein finales Feld:
- ein finales statisches Feld, das beim Laden der Klasse gesetzt wird, oder
- ein finales Instanzfeld, das beim Erzeugen des Objekts gesetzt wird.
Was aber, wenn du einen unveränderlichen Wert erst dann berechnen willst, wenn er wirklich gebraucht wird – etwa weil seine Initialisierung aufwändig ist? Dann bleibt dir nur die „Lazy Initialization“. Und damit die in einer nebenläufigen Anwendung korrekt funktioniert, musstest du sie bislang mühsam mit dem Double-Checked-Locking oder dem Initialization-on-Demand-Holder-Idiom absichern. Wer das einmal von Hand geschrieben hat, weiß: Dabei schleichen sich selbst bei erfahrenen Entwickler:innen schnell Fehler ein.
Die Lazy-Constants-API
Genau hier setzt die API an. Eine Lazy Constant ist ein Container für genau einen Wert, der höchstens einmal berechnet und danach wie eine echte Konstante behandelt wird.
Im folgenden Beispiel definieren wir eine LazyConstant, die beim ersten Zugriff einen Bean-Validation-Validator erzeugt – ein Objekt, dessen Erzeugung teuer ist, weshalb wir es nicht direkt beim Programmstart erzeugen wollen:
private final LazyConstant<Validator> validator =
LazyConstant.of(this::createValidator);
private Validator createValidator() {
return Validation.buildDefaultValidatorFactory().getValidator();
}
public Set<ConstraintViolation<Order>> validate(Order order) {
return validator.get().validate(order); // <-- Hier greifen wir auf die Lazy Constant zu
}Code-Sprache: Java (java)Erst der erste Aufruf von validator.get() führt createValidator() aus. Das Ergebnis wird in der LazyConstant abgelegt; jeder weitere Aufruf von validator.get() liefert den gespeicherten Validator zurück. Um die Threadsicherheit musst du dich nicht kümmern: Selbst wenn mehrere Threads gleichzeitig auf validator.get() zugreifen, wird createValidator() garantiert höchstens einmal ausgeführt.
Sobald die Lazy Constant initialisiert ist, betrachtet die JVM sie als unveränderlich und optimiert den Zugriff per Constant Folding – als hättest du den Wert von Anfang an in ein finales Feld geschrieben.
Lazy Lists
Du kannst nicht nur einzelne Lazy Constants definieren, sondern auch ganze Listen davon – Listen also, bei denen jedes Element eine eigene Lazy Constant ist. Das folgende Beispiel legt für ein Dokument pro Seite ein Vorschaubild an, von denen jedes aber erst beim ersten Zugriff darauf gerendert wird:
private final List<Thumbnail> thumbnails =
List.ofLazy(document.pageCount(), this::renderThumbnail);Code-Sprache: Java (java)renderThumbnail() wird also nicht für alle Seiten des Dokuments auf einmal aufgerufen, sondern separat pro Element der thumbnails-Liste – etwa beim direkten Zugriff über get(int index) oder beim Iterieren über die Liste. Greifst du nur auf die ersten drei Seiten zu, werden auch nur drei Vorschaubilder gerendert. Auch hier ist die Initialisierung threadsicher – und nach dem ersten Zugriff behandelt die JVM auch hier die Werte wie Konstanten.
Lazy Maps
Auch Maps lassen sich verzögert initialisieren. Bei einer Lazy Map stehen die Schlüssel beim Erzeugen bereits fest, die zugehörigen Werte werden aber erst bei Bedarf berechnet. Das folgende Beispiel ordnet Währungscodes ihre Wechselkurse zu, die wir über einen externen Dienst abrufen:
Set<String> currencies = Set.of("USD", "GBP", "JPY", "CHF");
Map<String, BigDecimal> exchangeRates =
Map.ofLazy(currencies, this::fetchExchangeRate);Code-Sprache: Java (java)Erst beim ersten Zugriff auf einen bestimmten Währungscode – z. B. über exchangeRates.get("JPY") – wird fetchExchangeRate() für diesen Key aufgerufen und das Ergebnis als Konstante in der Map abgelegt. Fragst du nie einen Yen-Kurs ab, wird er auch nie geladen. Wie schon bei Lazy Constants und Lazy Lists ist auch die Lazy Map threadsicher.
Lazy Sets
Und damit zur eigentlichen Neuerung in Java 27: Lazy Sets. Bei einem Lazy Set übergibst du eine Menge möglicher Kandidaten sowie eine Funktion, die für jeden Kandidaten entscheidet, ob er tatsächlich zur Menge gehört. Diese Funktion wird erst beim ersten Test eines Elements ausgeführt.
Das folgende Beispiel prüft, welche Features für die aktuelle Anwendung freigeschaltet sind. Die möglichen Features stehen fest; ob ein Feature aktiv ist, klärt eine (möglicherweise teure) Abfrage gegen einen Feature-Flag-Service:
Set<String> candidates =
Set.of("dark-mode", "beta-export", "ai-assistant", "live-collab");
Set<String> enabledFeatures =
Set.ofLazy(candidates, this::isFeatureEnabled);
if (enabledFeatures.contains("ai-assistant")) { // ⟵ erst hier wird isFeatureEnabled("ai-assistant") aufgerufen
// ...
}Code-Sprache: Java (java)Die Methode isFeatureEnabled() wird nur für diejenigen Features ausgeführt, die du auch wirklich abfragst – und das pro Element höchstens einmal – und das ganze wiederum threadsicher.
Lazy Constants – Änderungen in Java 27
In Java 27 werden durch JDK Enhancement Proposal 531 zwei Änderungen vorgenommen:
- Die Low-Level-Methoden
isInitialized()undorElse()entfallen. Sie verleiteten dazu, Lazy Constants gegen ihre eigentliche Designidee einzusetzen – etwa, um abhängig vom Initialisierungszustand unterschiedlich zu reagieren. Genau das soll eine Lazy Constant aber nicht leisten. - Zweitens kommt – wie oben gezeigt – die neue Factory-Methode
Set.ofLazy()hinzu. Damit gibt es nun für alle drei grundlegenden Collection-Typen –List,Setund `Map` – eine Lazy-Variante.
Mehr Beispiele und Details findest du im Hauptartikel über Lazy Constants.
Primitive Types in Patterns, instanceof, and switch (Fifth Preview) – JEP 532
Pattern Matching mit primitiven Typen wurde in Java 23 als Preview-Feature vorgestellt. In Java 26 gab es einige Verbesserungen in der Dominanzprüfung. In Java 27 wird das Feature durch JDK Enhancement Proposal 532 – erneut ohne Änderungen – in eine fünfte Preview-Runde geschickt.
Pattern Matching und switch mit primitiven Typen – Status quo
Pattern Matching funktioniert bislang ausschließlich mit Referenztypen, etwa so:
Object obj = . . .
switch (obj) {
case String s when s.length() > 10 -> IO.println("langer String");
case Character c -> IO.println(Character.toUpperCase(c));
case null, default -> IO.println(obj);
}Code-Sprache: Java (java)Ein switch über primitive Typen gibt es auch – aber bisher nur für byte, short, char und int. Und in den case-Labels dürfen ausschließlich Konstanten stehen:
int port = . . .
switch (port) {
case 80 -> IO.println("HTTP");
case 443 -> IO.println("HTTPS");
}Code-Sprache: Java (java)Pattern Matching und switch mit primitiven Typen – was sich ändert
Künftig sollen sich alle primitiven Typen im switch verwenden lassen, also auch long, double, float und sogar boolean. Außerdem sollen in den case-Labels nicht mehr nur Konstanten, sondern auch Patterns erlaubt sein. Damit könnten wir beispielsweise einen int-Wert auf bestimmte Bereiche prüfen:
int score = . . .
switch (score) {
case int s when s >= 90 -> IO.println("sehr gut");
case int s when s >= 75 -> IO.println("gut");
case int s when s >= 60 -> IO.println("befriedigend");
case int s when s >= 50 -> IO.println("ausreichend");
default -> IO.println("nicht bestanden");
}Code-Sprache: Java (java)Patterns mit Referenztypen matchen auch auf Untertypen – ein case Number n würde also genauso ein Integer-Objekt erfassen. Bei primitiven Typen gibt es jedoch keine Vererbung. Die JDK-Entwickler:innen haben sich für diesen Fall daher etwas anderes überlegt:
Wir können künftig mit switch – und genauso mit instanceof – prüfen, ob sich der Wert einer primitiven Variablen ohne Präzisionsverlust in einem anderen primitiven Typ darstellen lässt:
double value = . . .
switch (value) {
case byte b -> IO.println(value + " instanceof byte: " + b);
case short s -> IO.println(value + " instanceof short: " + s);
case char c -> IO.println(value + " instanceof char: " + c);
case int i -> IO.println(value + " instanceof int: " + i);
case long l -> IO.println(value + " instanceof long: " + l);
case float f -> IO.println(value + " instanceof float: " + f);
case double d -> IO.println(value + " instanceof double: " + d);
}Code-Sprache: Java (java)Hätte value hier den Wert 100, würde das Pattern byte b matchen, denn 100 passt verlustfrei in ein byte. Bei 40_000 würde char c matchen, bei 100_000 das Pattern int i. Ein Wert wie 0.25 matcht auf float f – denn diese Zahl lässt sich exakt als float darstellen. 0.1 hingegen matcht nur auf double d, weil sich dieser Wert eben nicht präzise in einem float darstellen lässt.
Auch bei primitiven Typen gilt das Dominanzprinzip: Die Reihenfolge der case-Label im obigen Beispiel ist nicht beliebig. Würden wir sie ändern, wären einzelne Labels nicht mehr erreichbar. int i dürfte zum Beispiel nicht vor byte b stehen, denn jeder mögliche Byte-Wert würde bereits auf int i matchen.
Mehr zu den genauen Regeln und weitere Beispiele und Besonderheiten findest du im Hauptartikel Primitive Typen in Patterns, instanceof und switch.
Structured Concurrency (Seventh Preview) – JEP 533
Structured Concurrency geht mittlerweile in die siebte Preview-Runde. Falls du die API bereits kennst und nur wissen möchtest, was sich in Java 27 geändert hat, springst du am besten direkt zum Abschnitt „Structured Concurrency – Änderungen in Java 27“.
Was ist Unstructured Concurrency?
Wer früher mit GOTO programmiert hat, weiß, was unstrukturierte Programmierung ist: Mit GOTO konnten wir an eine beliebige Stelle im Programmcode springen – ohne jemals wieder an die aufrufende Stelle zurückzukehren. Das resultierte in der Regel in schlecht lesbarem, sogenannten Spaghetti-Code. Durch die Einführung von strukturierter Programmierung wurde GOTO eliminiert und durch Schleifen, If-Then-Else-Blöcke und Methodenaufrufe ersetzt – Kontrollstrukturen mit klar erkennbaren Einstiegs- und Ausstiegspunkten.
Unstructured Concurrency überträgt dieses Modell auf die Nebenläufigkeit: Wir starten Threads, wobei oft im Code nicht klar erkennbar ist, wann diese Threads wieder enden. Manchmal warten wir mit join() darauf, dass ein Thread endet, manchmal nicht. Manchmal fahren wir einen ExecutorService sauber mit shutdown() und awaitTermination() herunter, manchmal nicht.
Grafisch lässt sich das etwa so darstellen:

Was ist Structured Concurrency?
Structured Concurrency überträgt das Prinzip der strukturierten Programmierung auf die Nebenläufigkeit: Sämtliche Ausführungspfade, die beim Starten nebenläufiger Tasks aufgespannt werden, laufen an einer einzigen Stelle im Code wieder zusammen. Und an dieser Stelle ist garantiert, dass kein verwaister Thread mehr im Hintergrund weiterarbeitet:

Structured Concurrency in Java
Im Ansatz war das in Java schon möglich – etwa mit einem ExecutorService und einem anschließenden Aufruf von close() bzw. shutdown() und awaitTermination() – oder seit Java 19 durch das Öffnen eines ExecutorService in einem Try-with-Resources-Block (welcher am Ende wiederum automatisch close() aufruft).
Doch die Structured-Concurrency-API StructuredTaskScope geht spürbar weiter: Sie kann einen Scope beim Eintreten bestimmter Ereignisse vorzeitig beenden und alle noch laufenden Tasks abbrechen. Mit einem ExecutorService ließ sich das nur über eine extrem aufwändige und fehleranfällige Orchestrierung nachbilden, in der Geschäftslogik, Thread-Handling und Error-Handling so miteinander verzahnt waren, dass die Geschäftslogik kaum noch erkennbar war.
Die StructuredTaskScope-API
Mit StructuredTaskScope geht das deutlich einfacher. Der folgende Code startet drei Subtasks parallel und wartet anschließend mit scope.join(), bis alle drei fertig sind. Schlägt einer der Subtasks fehl, werden die übrigen abgebrochen – und scope.join() wirft eine ExecutionException mit der ursprünglich aufgetretenen Exception als Cause:
ProductPage loadProductPage(long productId)
throws InterruptedException, ExecutionException {
try (var scope = StructuredTaskScope.open()) {
var detailsTask = scope.fork(() -> catalogService.getDetails(productId));
var priceTask = scope.fork(() -> pricingService.getPrice(productId));
var stockTask = scope.fork(() -> inventoryService.getStock(productId));
scope.join();
return ProductPage.assemble(
detailsTask.get(), priceTask.get(), stockTask.get());
}
}Code-Sprache: Java (java)Manchmal brauchen wir aber gar nicht die Ergebnisse aller Subtasks, sondern nur das erste, das eintrifft. Dafür können wir die Strategie des StructuredTaskScopes ändern, indem wir der open()-Methode einen sogenannten Joiner mitgeben. Im folgenden Beispiel fragen wir dieselbe Adresse bei drei redundanten Geocoding-Diensten ab – und sobald einer ein Ergebnis liefert, werden die beiden anderen abgebrochen:
GeoCoordinates resolveAddress(String address)
throws InterruptedException, ExecutionException {
try (var scope = StructuredTaskScope.open(
Joiner.<GeoCoordinates>anySuccessfulOrThrow())) {
scope.fork(() -> primaryGeocoder.lookup(address));
scope.fork(() -> backupGeocoder.lookup(address));
scope.fork(() -> offlineGeocoder.lookup(address));
return scope.join();
}
}Code-Sprache: Java (java)Das Joiner-Interface stellt noch weitere Strategien bereit – und du kannst auch eigene implementieren. Welche das sind und wie du dabei vorgehst, erfährst du im Hauptartikel über Structured Concurrency in Java.
Structured Concurrency – Änderungen in Java 27
Erstmals vorgestellt wurde Structured Concurrency als Incubator-Feature zusammen mit virtuellen Threads in Java 19. In Java 25 wurde die API grundlegend überarbeitet (Stichwort „Composition over Inheritance“), in Java 26 folgten einige kleinere Anpassungen. Mit Java 27 bringt JDK Enhancement Proposal 533 die folgenden Änderungen:
- Die Joiner
allSuccessfulOrThrow(),anySuccessfulOrThrow()undawaitAllSuccessfulOrThrow()werfen beim Fehlschlagen eines Subtasks nicht mehr die Preview-spezifischeFailedException, sondern eineExecutionException– also die gleiche Wrapper-Exception, die auchFuture.get()werfen kann. Die ursprüngliche Exception steckt wie gewohnt ingetCause(). StructuredTaskScopeundJoinerhaben einen dritten TypparameterR_Xbekommen, der für den Exception-Typ steht, denjoin()werfen kann. AusJoiner<T, R>wird damitJoiner<T, R, R_X>. Wenn du die mitgelieferten Joiner überopen()verwendest, leitet der Compiler die Typen in der Regel selbst ab – dein Code sieht unverändert aus. Sichtbar wird der Unterschied erst, wenn du eigene Joiner schreibst.- Die in Java 26 eingeführte
Joiner-MethodeonTimeout()heißt jetzttimeout(). Sie wird aufgerufen, wenn der Scope durch einen Timeout abgebrochen wird, und liefert dann entweder ein Ergebnis oder wirft eine Exception. - Der Joiner
awaitAll()wurde entfernt. - Es gibt eine neue
StructuredTaskScope.open()-Methode, die die Standard-Join-Strategie (alle Subtasks abwarten, beim ersten Fehler abbrechen) mit einem Konfigurations-Operator kombiniert. Bisher musstest du, um dem Scope beispielsweise einen Timeout und einen Namen mitzugeben, zusätzlich den Standard-Joiner übergeben. Das entfällt jetzt:
try (var scope = StructuredTaskScope.open(
cfg -> cfg.withTimeout(Duration.ofSeconds(2)).withName("checkout"))) {
scope.fork(() -> cartService.getCart(userId));
scope.fork(() -> profileService.getProfile(userId));
scope.join();
}Code-Sprache: Java (java)Code, der für Java 26 geschrieben wurde, lässt sich also mit überschaubarem Aufwand auf Java 27 übertragen – der häufigste Eingriff wird sein, ein catch (FailedException ...) auf catch (ExecutionException ...) umzustellen.
PEM Encodings of Cryptographic Objects (Third Preview) – JEP 538
PEM ist die Abkürzung für Privacy-Enhanced Mail – ein Kodierungsschema, mit dem sich kryptografische Objekte als Text darstellen lassen, der sich per Mail verschicken lässt. PEM-kodierte Objekte sind dir sicher schon einmal begegnet – etwa in Form eines Zertifikats wie diesem:
-----BEGIN CERTIFICATE-----
MIIDtzCCAz2gAwIBAgISBUCeYELtjMmr4FAIqHapebbFMAoGCCqGSM49BAMDMDIx
CzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQDEwJF
. . .
DBeMde1YpWNXpF9+B/OMKgn7RgXRj5b2QpBCnFsP92T4cK/Nn+xFIjYCMCCx4E79
toSQBlYnNHv0eXnWkI8TmXsU/A6rU4Gxdr9GbGixgRJvkw0C6zjL/lH2Vg==
-----END CERTIFICATE-----Code-Sprache: Klartext (plaintext)Bislang war es in Java überraschend mühsam, solche PEM-kodierten Objekte zu lesen oder zu schreiben. Das folgende Beispiel zeigt, wie viel Aufwand nötig war, um einen PEM-kodierten privaten Schlüssel einzulesen:
String encryptedPrivateKeyPemEncoded = . . .
String passphrase = . . .
String encryptedPrivateKeyBase64Encoded = encryptedPrivateKeyPemEncoded
.replace("-----BEGIN ENCRYPTED PRIVATE KEY-----", "")
.replace("-----END ENCRYPTED PRIVATE KEY-----", "")
.replaceAll("[\\r\\n]", "");
Base64.Decoder decoder = Base64.getDecoder();
byte[] encryptedPrivateKeyBytes = decoder.decode(encryptedPrivateKeyBase64Encoded);
EncryptedPrivateKeyInfo encryptedPrivateKeyInfo =
new EncryptedPrivateKeyInfo(encryptedPrivateKeyBytes);
String algorithmName = encryptedPrivateKeyInfo.getAlgName();
SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithmName);
PBEKeySpec pbeKeySpec = new PBEKeySpec(passphrase.toCharArray());
Key pbeKey = secretKeyFactory.generateSecret(pbeKeySpec);
Cipher cipher = Cipher.getInstance(algorithmName);
AlgorithmParameters algParams = encryptedPrivateKeyInfo.getAlgParameters();
cipher.init(Cipher.DECRYPT_MODE, pbeKey, algParams);
KeyFactory rsaKeyFactory = KeyFactory.getInstance("RSA");
KeySpec keySpec = encryptedPrivateKeyInfo.getKeySpec(cipher);
PrivateKey privateKey = rsaKeyFactory.generatePrivate(keySpec);Code-Sprache: Java (java)Mit Java 25 hielt eine eigene PEM-API Einzug – zunächst als Preview-Feature (JEP 470), das den Umgang mit PEM-kodierten Objekten spürbar vereinfachen sollte. In Java 26 ging die API in die zweite Preview-Runde (JEP 524), und in Java 27 folgt nun die dritte Preview (JEP 538).
Den verschlüsselten Private Key liest du damit in wenigen Zeilen:
PrivateKey privateKey = PEMDecoder.of()
.withDecryption(passphrase.toCharArray())
.decode(encryptedPrivateKeyPemEncoded, PrivateKey.class);Code-Sprache: Java (java)Für den umgekehrten Weg gibt es – analog zum PEMDecoder – auch einen PEMEncoder mit einer encodeToString()-Methode:
String encryptedPrivateKeyPemEncoded = PEMEncoder.of()
.withEncryption(passphrase.toCharArray())
.encodeToString(privateKey);Code-Sprache: Java (java)Änderungen in Java 27
In der dritten Preview-Runde wurden gegenüber Java 26 einige Klassen, Interfaces und Methoden angepasst. Für die hier gezeigten grundlegenden Anwendungsfälle sind diese Änderungen jedoch nicht relevant – das simple Beispiel oben funktioniert unverändert weiter.
Weitere Details zur PEM API und zu diesen Änderungen findest du im JDK Enhancement Proposal 538.
Vector API (Twelfth Incubator) – JEP 537
Und damit sind wir – inzwischen zum zwölften Mal – bei der Vector API angelangt. Die Vektor-API ermöglicht es uns, mathematische Vektoroperationen direkt über die Vektor-Befehlssätze moderner CPUs – Streaming SIMD Extensions (SSE) bzw. Advanced Vector Extensions (AVX) – auszuführen und dadurch deutlich performanter zu rechnen als mit klassischem, skalarem Code. Ein typisches Beispiel ist die Addition zweier Vektoren:
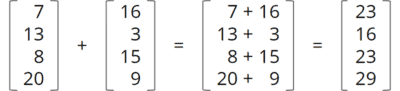
Mit der Vector API sieht eine solche Addition wie folgt aus – a und b sind die beiden Eingabe-Vektoren, c der Ergebnis-Vektor:
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void addVectors(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.add(vb);
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}Code-Sprache: Java (java)Für eine derart simple Rechenoperation ist das aktuell noch erstaunlich viel Boilerplate:
SPECIES.length()liefert die Anzahl der Vektor-Elemente, die die CPU in einem einzigen Zyklus parallel verarbeiten kann.SPECIES.loopBound(…)ermittelt, wie viele vollständige Teilvektoren dieser Länge sich aus dem Eingabe-Vektor bilden lassen.- Die erste Schleife addiert diese Teilvektoren.
- Geht die Länge des Eingabe-Vektors nicht glatt auf, bleibt am Ende ein Rest übrig – um diese Elemente zu verarbeiten, brauchen wir eine weitere Schleife.
Die zwölfte Incubator-Version der Vector API wird durch JDK Enhancement Proposal 537 definiert – und genau wie in Java 26 gibt es auch dieses Mal keine Änderungen.
Status der Vector API
Warum befindet sich die Vector API überhaupt noch im Incubator-Stadium?
Die Klasse Vector soll eine sogenannte „Value Class“ werden – das ist eine Klasse, deren Objekte ohne Identität auskommen. An Value Classes wird seit 2014 im Rahmen von Project Valhalla gearbeitet. Sobald der erste JEP aus Project Valhalla, JEP 401: Value Classes and Objects, als Preview im JDK enthalten sein wird, wird die Vector API auf Value Classes umgestellt und ebenso ins Preview-Stadium „befördert“ werden.
Zur Frage, wann es soweit sein wird, gibt es keine offiziellen Aussagen. Ich habe allerdings auf der JAlba Mitte Mai 2026 mit zwei hochrangigen Mitarbeitern von Oracle gesprochen, denen ich eine inoffizielle Aussage entlocken konnte: Demnach soll Java 28 eine erste Valhalla-Preview-Version enthalten.
Sonstige Änderungen in Java 27
Nicht alle Änderungen sind groß genug, um in einem JEP (JDK Enhancement Proposal) beschrieben zu werden – zahlreiche kleineren Änderungen findet ihr daher lediglich in den Release Notes. Ich habe für diesen Abschnitt einige erwähnenswerte Änderungen herausgepickt.
Predefined ISO-8601 Formatters Support Short Zone Offsets
Die DateTimeFormatter.parse()-Methode erkennt seit jeher Datumsangaben mit Zeitzonen-Offset, wie z. B. „2026-06-01T22:57:00+02:00“. Dies bedeutet: 1. Juni 2026, 22:57 Uhr mit einem Zeitzonen-Offset von plus 2 Stunden gegenüber UTC, also 20:57 Uhr UTC.
Das Format ist definiert in ISO 8601 und erlaubt die Angabe des Zeitzonen-Offsets auch in einer Kurzform, bei der nur die Stunden angegeben werden, also „2026-06-01T22:57:00+02“.
DateTimeFormatter.parse() hat dieses Format bisher als fehlerhaft abgewiesen und eine DateTimeParseException geworfen. Ab Java 27 wird das Format unterstützt.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8210336 registriert.)
Change the Default Values of MinHeapFreeRatio and MaxHeapFreeRatio for G1
Mit den VM-Argumenten -Xms und -Xmx legen wir den minimalen und maximalen Heap einer Java-Anwendung fest. Mit -XX:MinHeapFreeRatio und -XX:MaxHeapFreeRatio können wir zudem die Schwellen an freiem Heap festlegen unter bzw. über denen der Heap vergrößert bzw. verkleinert wird.
Diese Werte lagen bisher bei 40 % und 70 %, d. h. sobald weniger als 40 % Heap frei war, wurde der Heap vergrößert, und sobald mehr als 70 % frei war, wurde der Heap wieder verkleinert.
Da dies zu unnötig häufigen Heap-Größenänderungen führte, wurden diese Werte in Java 27 auf 0 % und 100 % gesetzt. Somit wird der Heap standardmäßig nur noch dann vergrößert, wenn er voll ist, und nur dann verkleinert, wenn er leer ist.
Sollte ein anderes Verhalten gewünscht sein, kann dies nach wie vor über -XX:MinHeapFreeRatio und -XX:MaxHeapFreeRatio konfiguriert werden.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8238686 registriert.)
Rename -XX:InitiatingHeapOccupancyPercent to -XX:G1IHOP
Für den Fall, dass du in deiner Anwendung die G1-Option -XX:InitiatingHeapOccupancyPercent gesetzt hast (diese konfigurert, wann G1 eine „Concurrent Start collection“ ausführt, solange G1 noch nicht ausreichend Daten für eigene Heuristiken gesammelt hat): Diese Option wurde umbenannt in -XX:G1IHOP. Der neue Name soll die Tatsache reflektieren, dass dieser Parameter G1-spezifisch ist. Der alte Name wird noch für einige Java-Versionen unterstützt werden.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8227106 registriert.)
Removal of the JVM Compiler Interface (JVMCI)
Das in Java 9 eingeführte JVM Compiler Interface (JVMCI) war eine experimentelle API, mit der die Hotspot-JVM einen in Java geschriebenen Just-In-Time-Compiler ansteuern konnte – anstelle des eingebauten C2-Compilers. Genau über diese Schnittstelle ließ sich beispielsweise der Graal-Compiler als C2-Ersatz in ein normales OpenJDK einklinken (per -XX:+UseGraalJIT bzw. -XX:+UseJVMCICompiler).
Den experimentellen Graal-Compiler selbst hatte das JDK-Team bereits in Java 17 entfernt; die JVMCI-Schnittstelle blieb damals jedoch erhalten, damit sich extern gebaute Compiler weiterhin einklinken ließen. Nach gut zehn Jahren wird nun auch die Schnittstelle selbst eingestellt, da sich ihr Pflege- und Testaufwand für die wenigen verbliebenen Use Cases nicht mehr rechnete.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8382582 registriert.)
Obsolete UseCompressedClassPointers
In Java 25 wurde die Option -XX:-UseCompressedClassPointers, mit der Compressed Class Pointers deaktiviert werden konnten, als deprecated markiert.
In Java 27 wurden umkomprimierte Class Pointer entfernt, und die Option hat keine Funktion mehr.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8372065 registriert.)
Vollständige Liste aller Änderungen in Java 27
Dieser Artikel hat alle JEPs vorgestellt, die in Java 27 veröffentlicht wurden – und zudem einige ausgewählte Änderungen aus den Release Notes. Die vollständige Liste aller Änderungen findest du in den offiziellen Java 27 Release Notes.
Fazit
In Java 27 gibt es keine großen neuen Sprachfeatures, aber dennoch einige nennenswerte Änderungen:
- Compact Object Headers sind standardmäßig aktiviert, was bei Anwendungen mit vielen kleinen Objekten bis zu 20 % Heap einsparen und den Durchsatz um bis zu 10 % erhöhen kann.
- Der Java Flight Recorder kann vertrauliche Informationen schwärzen, wodurch mögliche Angriffsvektoren geschlossen wurden.
- TLS verwendet – sofern der Server das unterstützt – automatisch quantensichere Verschlüsselung, wodurch sogenannte „Harvest now, decrypt later“-Angriffe unterbunden werden.
- G1 ist nun auch auf leistungsschwächeren Maschinen (nur eine CPU oder weniger als 1.792 MB RAM) der Default-Garbage-Collector.
- Bei Lazy Constants wurden – wie auch schon in Java 26 – weitere Low-Level-Methoden entfernt; zudem wurden der API Lazy Sets hinzugefügt.
StructuredTaskScopehat nun einen weitere Typ-Parameter für den Exception-Typ;join()wirft – wenn nicht anders angegeben – eineExecutionException(statt eineFailedException); derawaitAll()-Joiner wurde entfernt;Joiner.onTimeout()wurde durchtimeout()ersetzt.- Bei PEM Encodings of Cryptographic Objects wurde der
PEM-Record zu einer Klasse, und einige andere Klassen und Methoden wurden umbenannt. - Primitive Type Patterns und die Vector API wurden ohne Änderungen in die nächste Preview- bzw. Incubator-Runde geschickt.
Diverse sonstige Änderungen runden wie immer das Release ab. Das aktuelle Java-27-Early-Access-Release kannst du hier herunterladen.
Welche der Änderungen findest du am spannendsten? Ich freue mich auf deine Meinung in den Kommentaren!