


Java 24 Features
(mit Beispielen)
Java 24 wurde am 18. März 2025 veröffentlicht. Du kannst es hier herunterladen.
In Java 24 wurden ... Trommelwirbel ... exakt 24 JEPs umgesetzt – nach Java 11 (18 JEPs) ein neuer Rekord! Das hört sich erstmal nach viel an, mit einem Großteil der Änderungen werden allerdings die meisten von uns im Programmier-Alltag nicht direkt konfrontieren werden.
Hier sind meine persönlichen Highlights:
- Die Stream Gatherers API, mit der wir unsere eigenen intermediären Stream-Operationen schreiben können, wurde finalisiert.
- Synchronize Virtual Threads without Pinning: In virtuellen Threads dürfen wir um blockierenden Code endlich auch
synchronizedverwenden! - Mit Ahead-of-Time Class Loading & Linking soll die Startzeit insbesondere von kurzlebigen Java-Programmen erheblich verkürzt werden.
- Mit Compact Object Headers wird (aktuell noch experimentell) der Objekt-Header von (in der Regel) 12 Byte auf 8 Byte verkürzt und damit der Speicherbederf pro Objekt auf dem Heap um 4 Bytes reduziert. Für Anwendungen mit Millionen von Objekten auf dem Heap ist das in Summe eine signifikante Ersparnis.
Für alle JEPs und sonstigen Änderungen verwende ich wie immer die originalen, englischen Bezeichnungen.
Stream Gatherers – JEP 485
Vor über zehn Jahren wurde in Java 8 die Stream API eingeführt. Aufgrund der recht begrenzten Auswahl an intermediären Operationen – filter, map, flatMap, mapMulti, distinct, sorted, peak, limit, skip, takeWhile und dropWhile – gibt es in der Java-Community laute Rufe nach zusätzlichen Operationen wie z. B. window oder fold.
Doch anstatt all diese Feature-Requests umzusetzen, entschieden sich die JDK-Developer zu einer anderen Lösung: Sie implementierten eine API, mit der sowohl die JDK-Developer als auch alle anderen Developer selbst intermediäre Stream-Operationen implementieren können.
Diese neue API heißt „Stream Gatherers”. Sie wurde erstmals in Java 22 als Preview-Version vorgestellt und ging in Java 23 ohne Änderungen in eine zweite Preview-Runde.
In Java 24 wird die Stream Gatherers API durch JDK Enhancement Proposal 485 finalisiert – erneut ohne Änderungen.
Der folgende Code zeigt beispielsweise, wie wir die intermediäre Stream-Operation „filter” als Stream Gatherer implementieren und verwenden können. Das kurze Programm zeigt all diejenigen Strings an, die mindestens 3 Zeichen lang sind:
void main() {
List<String> words = List.of("the", "be", "two", "of", "and", "a", "in", "that");
List<String> list = words.stream()
.gather(filtering(string -> string.length() >= 3))
.toList();
System.out.println(list);
}
private <T> Gatherer<T, Void, T> filtering(Predicate<T> predicate) {
return Gatherer.of(Gatherer.Integrator.ofGreedy(
(_, element, downstream) -> {
if (predicate.test(element)) {
return downstream.push(element);
} else {
return true;
}
}));
}Code-Sprache: Java (java)Was sind die Komponenten dieses Programms, und wie funktionieren sie?
Wie implementiert man komplexere Stream Gatherer, und welche Einschränkungen gibt es dabei?
Welche vordefinierten Stream Gatherer liefert Java 24 mit?
All das erfährst du im Hauptartikel über Stream Gatherers ... oder bei meinem Stream-Gatherers-Vortrag auf der JavaLand 2025 :-)

Synchronize Virtual Threads without Pinning – JEP 491
Seit ihrer Einführung in Java 21 wurden virtuelle Threads beim Aufruf von blockierendem Code innerhalb eines synchronized-Blocks an ihren Carrier Thread „gepinnt“, d. h. der Carrier Thread wurde blockiert und konnte währenddessen keine anderen virtuellen Threads bedienen. Das konnte ganze Anwendungen einfrieren lassen, wie z. B. in dem hier anschaulich beschriebenen Fall bei Netflix.
Ab Java 24 gehört dieses Problem der Vergangenenheit an. Beim Aufruf von blockierendem Code innerhalb eines synchronized-Blocks wird der virtuelle Thread nun vom Carrier Thread gelöst, und dieser kann andere virtuelle Threads ausführen.
Warum wurden virtuelle Threads „gepinnt“?
Zum einen wurde beim sogenannten Legacy Stack Locking beim Aufruf eines synchronized-Blocks das Mark Word des Objekt-Headers durch einen Pointer auf eine Speicheradresse auf dem Thread-Stack ersetzt. Da der Stack beim Unmounten eines virtuellen Threads auf den Heap verschoben wird und beim Mounten zurück auf den Stack – möglicherweise aber auf den Stack eines anderen Carrier Threads – wäre diese Speicheradresse dadurch ungültig geworden.
Dieses Problem wird durch das seit Java 23 standardmäßig aktivierte Lightweight Locking gelöst, das ohne Änderung des Mark Words auskommt.
Zum anderen merkt sich die JVM beim Aufruf eines synchronized-Blocks, welcher Plattform-Thread sich in dem Block befindet, nicht welcher virtuelle Thread. Wenn nun der virtuelle Thread vom Carrier Thread genommen und ein anderer virtueller Thread auf diesen Carrier gemounted wird, dann könnte dieser andere virtuelle Thread ebenfalls den synchronized-Block betreten.
Warum merkt sich die JVM den Plattform-Thread und nicht den virtuellen Thread? Ganz einfach: der JVM-Code ist komplex, und die JDK-Entwickler hatten es bis zur Veröffentlichung von Java 21 einfach nicht rechtzeitig geschafft, ihn anzupassen.
Pinning bei Aufruf von nativem Code
Auch nativer Code (aufgerufen via JNI oder FFM-API) könnte mit Pointern auf den Thread-Stack arbeiten, die nach dem Unmounten und Mounten eines virtuellen Threads auf einem anderen Carrier Thread ungültig werden würden. Daher wird beim Aufruf von nativem Code ein virtueller Thread weiterhin an seinen Carrier Thread gepinnt.
Daran ändert sich durch diesen JEP und vermutlich auch zukünftig nichts.
Die Diagnose-Property jdk.tracePinnedThreads wird entfernt
Mit der System Property jdk.tracePinnedThreads konnte man sich einen Stacktrace ausgeben lassen, sobald ein virtueller Thread einen synchronized Block betreten hat und dadurch an seinen Carrier gepinnt wurde. Da die Ausgabe innerhalb des synchronized Blocks erfolgte, wurde die Dauer des Pinnings dadurch noch verlängert.
Die Property wurde in Java 24 ersatzlos entfernt.
Ahead-of-Time Class Loading & Linking – JEP 483
Java-Anwendungen sind extrem flexibel und performant:
- Klassen können dynamisch ge- und entladen werden.
- Durch dynamische Compilierung, Optimierung und Re-Optimierung laufen sie teilweise schneller als C-Code.
- Reflection ermöglicht Enterprise-Frameworks wie Jakarta EE und Spring Boot.
Doch dafür müssen beim Start Tausende von Klassen gelesen, geparst, geladen und gelinkt werden, was besonders bei großen Backend-Anwendungen zu langen Startzeiten führen kann.
Innerhalb von Project Leyden wird seit langem an Lösungen dafür gearbeitet, möglichst viele dieser vorbereitenden Aufgaben bereits vor dem Start einer Anwendung auszuführen. Durch JDK Enhancement Proposal 483 wird in Java 24 die erste dieser Lösungen vorgestellt: Ahead-of-Time Class Loading & Linking.
Dabei werden in einer Vorbereitungsphase alle von der Anwendung benötigten Klassen gelesen, geparst, geladen und gelinkt und dann in diesem Zustand in einem Cache gespeichert. Beim Start der Anwendung müssen diese Schritte dann nicht mehr ausgeführt werden; die Anwendung kann auf die geladenen und gelinkten Klassen direkt über den Cache zugreifen.
Weitere Details zur Funktionsweise, eine Schritt-für-Schritt-Anleitung zum Ausprobieren und eine Gegenüberstellung mit AppCDS (Application Class Data Sharing) findest du im Hauptartikel Ahead-of-Time Class Loading & Linking.
Neue Preview- und Experimental Features in Java 24
In Java 24 gibt es ein neues Preview-Feature und zwei experimentelle Previews.
Diese Features sind zum Ausprobieren und Feedback geben gedacht. Sie sollten nicht unbedingt in Produktivcode eingesetzt werden, da sie sich noch ändern oder – wie im Fall von String Templates – auch wieder komplett entfernt werden können.
Preview-Features müssen im Java-Compiler javac mit --enable-preview --source 24 aktiviert werden. Beim Start eines Programms mit dem java-Kommando genügt --enable-preview.
Experimentelle Features werden zur Laufzeit mit -XX:+UnlockExperimentalVMOptions aktiviert.
Key Derivation Function API (Preview) – JEP 478
Eine Key Derivation Function (KDF, deutsch: Schlüsselableitungsfunktion) ist eine Methode, um aus einem geheimen Wert wie einem Passwort, einer Passphrase oder einem kryptographischen Schlüssel einen oder mehrere neue kryptographische Schlüssel abzuleiten.
Damit Sicherheitsanbieter KDF-Algorithmen implementieren und anbieten können und wir sie in Anwendungen einsetzen können, bedarf es einer einheitlichen API.
Solch eine API wird durch JDK Enhancement Proposal 478 bereitgestellt: über die neue Klasse javax.crypto.KDF können Key Derivation Functions geladen und aufgerufen werden.
Der folgende Beispielcode zeigt, wie du über den KDF-Algorithmus "HKDF-SHA256" aus einem Passwort bzw. einer Passphrase und einem Salt einen AES-Key erzeugen kannst.
void main() throws InvalidAlgorithmParameterException, NoSuchAlgorithmException {
// 1. Get the implementation of the specified KDF algorithm
KDF hkdf = KDF.getInstance("HKDF-SHA256");
// 2. Specify the derivation parameters
AlgorithmParameterSpec params =
HKDFParameterSpec.ofExtract()
// 2.1. The password / passphrase
.addIKM("the super secret passphrase".getBytes(StandardCharsets.UTF_8))
// 2.2. The salt value
.addSalt("the salt".getBytes(StandardCharsets.UTF_8))
// 2.3. Optional application-specific information
.thenExpand("my derived key".getBytes(StandardCharsets.UTF_8), 32);
// 3. Derive a 32-byte AES keys
SecretKey key = hkdf.deriveKey("AES", params);
System.out.println("key = " + HexFormat.of().formatHex(key.getEncoded()));
}Code-Sprache: Java (java)Falls du dich über die fehlende Klassendeklaration, fehlende Imports und das kurze void main() statt des gewohnten public static void main(String[] args) wunderst – diese Vereinfachungen werden im Abschnitt Simple Source Files and Instance Main Methods beschrieben.
Im Quellcode finden sich eine ganze Menge Abkürzungen. Eine Erläuterung dieser Konzpete würde den Rahmen dieses Artikels sprengen, daher habe ich dir ein paar Links zu Wikipedia-Artikeln zusammengestellt:
- HKDF steht für HMAC Key Derivation Function.
- HMAC wiederum steht für Hash-based Message Authentication Code.
- IKM steht für „input key material“ – das kann ein Passwort, eine Passphrase oder auch ein anderer kryptografischer Schlüssel sein.
- AES steht für Advanced Encryption Standard.
Wenn du den oben gezeigten Quellcode in der Datei KDFTest.java speicherst, kannst du ihn mit Java 24 wie folgt aufrufen:
java --enable-preview KDFTest.javaCode-Sprache: Klartext (plaintext)Bei mir führt das zum Beispiel zu folgender Ausgabe:
key = 7ee15549ddce956194ca1d6df5aa34c1a1334d15c875e67ea67fb5850ee48b0cCode-Sprache: Klartext (plaintext)Dieser Key kann dann z. B. als Session Key für die verschlüsselte Datenübertragung verwendet werden.
Die Key Derivation Function API wird in Java 25 finalisiert.
Generational Shenandoah (Experimental) – JEP 404
In Java 15 wurden mit ZGC und Shenandoah zwei neue Garbage Collectoren eingeführt. Beide versprechen extrem niedrige Pausenzeiten von weniger als 10 Millisekunden.
Zum Zeitpunkt ihrer Einführung machten diese GCs keinen Unterschied zwischen „alten” und „neuen” Objekten. Somit machten sie sich nicht die sogenannte „Schwache Generationshypothese” (englisch: „Weak Generational Hypothesis”) zunutze, die besagt, dass die meisten Objekte kurz nach ihrer Entstehung wieder sterben, und dass diejenigen Objekte, die bereits ein gewisses Alter erreicht haben, in der Regel auch noch länger leben werden.
Ein „Generational Garbage Collector” nutzt diese Hypothese, in dem er den Heap in zwei logische Bereiche aufteilt: eine „junge Generation” und eine „alte Generation”. In der jungen Generation werden neue Objekte angelegt, und wenn diese einige GC-Zyklen überstanden haben, werden sie in die alte Generation verschoben. Da die Wahrscheinlichkeit hoch ist, dass die Objekte in der alten Generation länger leben, kann der Garbage Collector die Leistung einer Anwendung erhöhen, indem er die alte Generation seltener aufräumt.
In Java 21 wurde dann ein „Generational Mode” für den ZGC vorgestellt, der seit Java 23 standardmäßig aktiviert ist.
Ursprünglich war in Java 21 dieser Modus auch für Shenandoah eingeplant, doch das Shenandoah-Team zog den JEP kurz vor der Veröffentlichung zurück, da die Implementierung noch nicht ausgereift war.
Jetzt ist es endlich so weit: In Java 24 wird nun auch für Shenandoah der „Generational Mode” eingeführt. Dieser Modus befindet sich aktuell noch im Versuchsstadium und kann wie folgt aktiviert werden:
-XX:+UnlockExperimentalVMOptions -XX:ShenandoahGCMode=generational
Die Änderungen werden in JDK Enhancement Proposal 404 beschrieben – allerdings recht oberflächlich. Falls du dich für die Funktionsweise eines Generational Garbage Collectors interessierst, empfehle ich dir den sehr detaillierten JEP 439 (Generational ZGC) zu lesen.
Compact Object Headers (Experimental) – JEP 450
Der Java-Objekt-Header ist aktuell in der Regel 12 Byte groß (bzw. 16 Byte, wenn Compressed Class Pointers ausgeschaltet sind). Um den Speicherbedarf von Java-Anwendungen zu reduzieren, arbeiten die JDK-Entwickler im Rahmen von Project Lilliput an Möglichkeiten, um den Header auf 8 Byte – und im nächsten Schritt auf 4 Byte – zu komprimieren.
In Java 24 wurde das erste, vielversprechende Resultat aus Project Lilliput vorgestellt: Durch JDK Enhancement Proposal 450 kann der Objekt-Header auf 8 Byte komprimiert werden (aktuell noch im „Experimental“-Status).
Wie haben die JDK-Developer das erreicht?
Status Quo
Ein 12-Byte-Object-Header besteht aus einem 64-Bit Mark Word und einem 32-Bit Class Word:
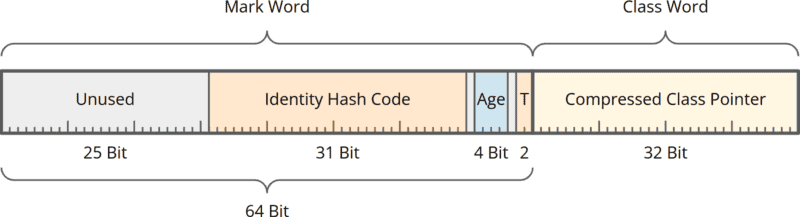
Das Mark Word enthält:
- 27 ungenutzte Bits (25 am Anfang und je eines vor und nach dem „Age Tag“),
- den 31 Bit langen Identity Hash Code,
- 4 Bits, in denen der Garbage Collector das Alter eines Objekts speichert,
- 2 „Tag Bits“, die anzeigen, ob und wie das Objekt gelockt ist.
Das Class Word enthält:
- einen 32-Bit-Pointer auf die sogenannte Klass-Datenstruktur, in der die Informationen der Klasse gespeichert sind, von der das Objekt eine Instanz ist.
Komprimierung des Objekt-Headers
Das Mark Word enthält 27 ungenutzte Bits. Von den insgesamt 96 Bits werden also nur 69 Bits benötigt. Um auf 64 Bit zu kommen, müssen wir fünf Bits einsparen. Folgendes kam dabei heraus:
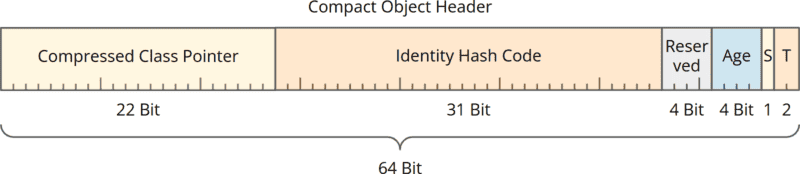
Wir haben nun einen 64 Bit-Header, der nicht mehr in Mark Word und Class Word unterteilt ist. Der Header enthält:
- einen auf 22 Bit komprimierten Class Pointer,
- den 31-Bit Identity Hash Code (unverändert),
- 4 für Project Valhalla reservierte Bits (neu),
- 4 Bits für das Alter des Objekts (unverändert),
- 1 Bit für das sogenannte „Self Forwarded Tag“,
- 2 Tag Bits (unverändert).
Der Class Pointer wurde also um 10 Bits verkleinert. Da wir nur fünf Bits einsparen mussten, stehen nun fünf zusätzliche Bits zur Verfügung. Vier davon wurden für Projekt Valhalla reserviert, und in einem Bit wird das neue „Self Forwarded Tag“ gespeichert.
Wie es den JDK-Developern gelang, den Class Pointer von 32 Bit auf 22 Bit zu komprimieren und was das „Self Forwarded Tag“ ist, erfährst du im Hauptartikel über Compact Object Headers.
Compact Object Headers befinden sich in Java 24 noch im experimentellen Stadium und müssen mit folgender VM-Option aktiviert werden:
-XX:+UnlockExperimentalVMOptions -XX:+UseCompactObjectHeaders
Wiedervorgelegte Preview und Incubator-Features
Ganze sieben Preview- und Incubator-JEPs wurden in Java 24 wiedervorgelegt – vier davon ohne Änderungen gegenüber Java 23, eines mit Änderungen nur in der Terminologie und zwei mit kleineren Änderungen. Welche das sind, erfährst du in den nächsten Abschnitten.
Primitive Types in Patterns, instanceof, and switch (Second Preview) – JEP 488
In Java 16 wurde Pattern Matching mit instanceof eingeführt und in Java 21 Pattern Matching mit switch.
Das folgende switch-Statement prüft beispielsweise, ob das Objekt obj ein mindestens fünf Zeichen langer String ist und gibt diesen dann, in Großbuchstaben umgewandelt aus. Wenn das Objekt hingegen ein Integer ist, wird die Zahl quadriert und ausgegeben:
switch (obj) {
case String s when s.length() >= 5 -> System.out.println(s.toUpperCase());
case Integer i -> System.out.println(i * i);
case null, default -> System.out.println(obj);
}Code-Sprache: Java (java)Auf diese Weise konnten wir bisher nur Objekte mit Mustern abgleichen, nicht jedoch primitive Datentypen wie int, long oder double.
Was wir allerdings schon immer in einem switch machen konnten (wenn auch nicht in der modernen Pfeil-Notation), war z. B. eine int-Variable mit Konstanten zu vergleichen:
int code = . . .
switch (code) {
case 200 -> System.out.println("OK");
case 400 -> System.out.println("Bad Request");
case 404 -> System.out.println("Not Found");
. . .
}Code-Sprache: Java (java)Aber Achtung: das funktionierte bisher nur mit den primitiven Datentypen byte, short, char und int – nicht hingegen mit long,float, double und boolean.
Durch „Primitive Types in Patterns, instanceof, and switch“ – erstmals in Java 23 durch JDK Enhancement Proposal 455 vorgestellt und in Java 24 durch JDK Enhancement Proposal 488 ohne Änderungen wiedervorgelegt – werden sich zwei Dinge ändern:
- Im Pattern Matching mit instanceof und switch können wir in Zukunft auch primitive Typen verwenden.
- In switch dürfen wir alle primitiven Typen verwenden, also auch
long,float,double– und sogarboolean.
Pattern Matching mit primitiven Typen unterscheidet sich allerdings vom Pattern Matching mit Referenztypen:
- Beim Pattern Matching mit Referenztypen prüfen wir, ob ein Objekt eine Instanz eines bestimmten Typs (Klasse oder Interface) ist oder Instanz eines von diesem Typen direkt oder indirekt abgeleiteten Typen. Eine Variable vom Typ
Integerbeispielsweise würde auf das PatternInteger i, aber auch auf die PatternNumber n,Object ooder sogarComparable coderSerializable smatchen. - Beim Pattern Matching mit primitiven Typen hingegen prüfen wir, ob sich eine Variable ohne Präzisionsverlust im zu matchenden Typen speichern lässt.
Das hört sich erstmal kompliziert an, ist aber an einem Beispiel schnell erklärt:
int i = . . .
if (i instanceof byte b) {
. . .
}Code-Sprache: Java (java)Der Code ist wie folgt zu lesen: Wenn sich der Inhalt der int-Variablen i auch in einem byte darstellen lässt, dann matcht die Variable das Pattern und wird im „then“-Block in der byte-Variablen b verfügbar gemacht.
Für beispielsweise a = 50 würde die Prüfung true ergeben, für a = 500 hingegen false, da ein byte lediglich Werte im Bereich -128 bis +127 speichern kann.
Hier ein zweites Beispiel:
double d = . . .
if (d instanceof float f) {
. . .
}Code-Sprache: Java (java)Hier gilt: Wenn sich der Inhalt der double-Variablen d ohne Präzisionsverlust in einem float darstellen lässt, dann matcht die Variable das Pattern.
Für beispielsweise d = 1.5 würde die Prüfung true ergeben, für d = Math.PI hingegen false, da Math.PI (vereinfacht gesagt) mehr Nachkommastellen hat als ein float aufnehmen kann.
Auch in switch können wir primitive Typ-Pattern verwenden:
double value = ...
switch (value) {
case byte b -> System.out.println(value + " instanceof byte: " + b);
case short s -> System.out.println(value + " instanceof short: " + s);
case char c -> System.out.println(value + " instanceof char: " + c);
case int i -> System.out.println(value + " instanceof int: " + i);
case long l -> System.out.println(value + " instanceof long: " + l);
case float f -> System.out.println(value + " instanceof float: " + f);
case double d -> System.out.println(value + " instanceof double: " + d);
}Code-Sprache: Java (java)Für value = 5 würde hier beispielsweise das Pattern byte b matchen, für value = 500 das Pattern short s, für value = 5000000 das Pattern int i und für value = 1.5 das Pattern float f.
Auch bei switch mit primitiven Typen müssen wir das Prinzip der dominierenden und dominierten Typen sowie die Vollständigkeitsprüfung beachten.
Mehr dazu und weitere Beispiele findest du im Hauptartikel Primitive Typen in Patterns, instanceof und switch.
Module Import Declarations (Second Preview) – JEP 494
Seit jeher können wir mit dem import-Statement einzelne Klassen oder ganze Pakete importieren.
Mit import module, erstmals in Java 23 durch JDK Enhancement Proposal 476 als Preview-Feature vorgestellt, können wir nun auch ganze Module importieren – und somit alle Klassen, die sich innerhalb des Moduls befinden, direkt verwenden.
Im folgenden Beispiel importieren wir das Modul java.base und können dadurch die Klassen List, Map, Stream und Collectors verwenden, ohne sie einzeln importieren zu müssen:
import module java.base;
public static Map<Character, List<String>> groupByFirstLetter(String... values) {
return Stream.of(values).collect(
Collectors.groupingBy(s -> Character.toUpperCase(s.charAt(0))));
}Code-Sprache: Java (java)Mehrdeutige Klassennamen auflösen
Wenn ein Klassenname in mehreren importierten Modulen vorkommt, z. B. List im Modul java.base und im Modul java.desktop, dann weiß der Compiler nicht, welche Klasse gemeint ist, wie im folgenden Beispiel:
import module java.base;
import module java.desktop;
. . .
List list = new ArrayList(); // Compiler error: "reference to List is ambiguous"
. . .Code-Sprache: Java (java)Diese Mehrdeutigkeit kann durch einen Import der gewünschten Klasse aufgelöst werden:
import module java.base;
import module java.desktop;
import java.util.List; // ⟵ This resolves the ambiguity
. . .
List list = new ArrayList();
. . .Code-Sprache: Java (java)Was in Java 23 noch nicht möglich war und in Java 24 im zweiten Preview dieses Features durch JDK Enhancement Proposal 494 hinzugekommen ist, ist die Möglichkeit, die Mehrdeutigkeit auch durch ein Package-Import aufzulösen, und zwar wie folgt:
import module java.base;
import module java.desktop;
import java.util.*; // ⟵ This resolves the ambiguity (since Java 24)
. . .
List list = new ArrayList();
. . .Code-Sprache: Java (java)Transitive Imports
Wenn ein importiertes Modul ein anderes Modul transitiv importiert, dann sind auch alle Klassen der exportierten Pakete des transitiv importierten Moduls ohne explizite Imports nutzbar.
Ein Beispiel dazu findest du im Hauptartikel über Module Imports.
Dieses Feature führte in Java 23 zu Verwirrung in der Java-Community:
Durch den Import des Moduls java.se (ein Aggregator-Modul, das Abhängigkeiten auf alle Module der Java Standard Edition „Java SE“ definiert) wurde das Modul java.base nicht mit importiert. Das lag daran, dass Java-Module bisher keine transitive Abhängigkeit auf java.base definieren durften.
Durch JDK Enhancement Proposal 494 wird diese Einschränkung in der Sprachspezifikation aufgehoben und die Abhängigkeit von java.se auf java.base als transitiv markiert, so dass nun durch import module java.se auch alle Klassen des java.base-Moduls verfügbar sind.
Anpassungen an JShell und Simple Source Files
JShell und Simple Source Files importieren, wenn Preview-Features aktiviert sind, automatisch das java.base-Modul.
Weitere Beispiele zur Auflösung mehrdeutiger Klassennamen und zu transitiven Modul-Abhängigkeiten findest du im Hauptartikel Module importieren in Java: Module Import Declarations.
Flexible Constructor Bodies (Third Preview) – JEP 492
Bisher war es in Java-Konstruktoren nicht erlaubt, Code vor dem Aufruf von super() oder this() aufzurufen. Wenn wir z. B. vor dem Aufruf von super() einen Parameter überprüfen wollten, dann war das nur über einen Aufruf einer statischen Methode innerhalb der Klammern des super-Aufrufs möglich:
public class ChildClass extends SuperClass {
public ChildClass(String parameter) {
super(verifyParameter(parameter));
}
private static String verifyParameter(String parameter) {
if (parameter == null || parameter.isEmpty()) {
throw new IllegalArgumentException();
}
return parameter;
}
}Code-Sprache: Java (java)Bei mehreren Parametern wird das schnell unübersichtlich.
Durch „Flexible Constructor Bodies“ – erstmals in Java 22 als Preview-Feature unter dem Namen „Statements before super(…)“ durch JDK Enhancement Proposal 447 vorgestellt – kann der Code wie folgt umgeschrieben werden:
public class ChildClass extends SuperClass {
public ChildClass(String parameter) {
if (parameter == null || parameter.isEmpty()) {
throw new IllegalArgumentException();
}
super(parameter);
}
}
Code-Sprache: Java (java)Vor dem Aufruf von super(...) durfte dadurch lesend und schreibend auf Parameter und Variablen des Konstruktors zugegriffen werden, nicht aber auf die Felder der Klasse.
In Java 23 wurde das Feature durch JDK Enhancement Proposal 482 in „Flexible Constructor Bodies“ umbenannt. Die im vorherigen Absatz genannte Einschränkung wurde dahingehend aufgelockert, dass nun auf Felder der Klasse schreibend zugegriffen werden darf, diese also vor Aufruf des Super-Konstruktors initialisiert werden können.
Das ist insbesondere hilfreich in Fällen, in denen der Super-Konstruktor Methoden aufruft, die in der abgeleiteten Klasse überschrieben sind und hier lesend auf Felder zugreifen.
Hier ein Beispiel dazu:
public class SuperClass {
public SuperClass() {
logCreation();
}
protected void logCreation() {
System.out.println("SuperClass created");
}
}
public class ChildClass extends SuperClass {
private final String parameter;
public ChildClass(String parameter) {
this.parameter = parameter;
}
@Override
protected void logCreation() {
System.out.println("ChildClass created, parameter = " + parameter);
}
}Code-Sprache: Java (java)Was würde nun die Erzeugung eines neuen ChildClass-Objekts z. B. mit new ChildClass("foo") ausgeben?
Wir würden vermutlich folgende Ausgabe erwarten:
ChildClass created, parameter = fooCode-Sprache: Klartext (plaintext)Tatsächlich bekommen wir aber Folgendes zu sehen (null anstelle von foo):
ChildClass created, parameter = nullCode-Sprache: Klartext (plaintext)Woran liegt das?
Der ChildClass-Konstruktor ruft als erstes super() auf (dieser Aufruf wird vom Compiler am Anfang des ChildClass-Konstruktors eingefügt). Daraufhin ruft der SuperClass-Konstruktor die logCreation()-Methode auf, die durch ChildClass überschrieben wurde. Allerdings wurde zu diesem Zeitpunkt das Feld parameter noch nicht zugewiesen und ist daher noch null.
Unabhängig von der Frage, ob wir im Konstruktor überhaupt nicht-finale, also überschreibbare Methoden aufrufen sollten, können wir das Problem in Java 23 beheben, indem wir den ChildClass-Konstruktor wie folgt abändern:
public ChildClass(String parameter) {
this.parameter = parameter; // ⟵ First assign the parameter,
super(); // ⟵ then call super()
}Code-Sprache: Java (java)Dadurch wird der Super-Konstruktor (und damit auch die logCreation()-Methode) erst nach der Zuweisung des parameter-Felds aufgerufen. Und logCreation() wird dementsprechend das initialisierte Feld anzeigen und nicht mehr null.
In Java 24 werden „Flexible Constructor Bodies“ durch JDK Enhancement Proposal 492 ohne Änderungen wiedervorgelegt – lediglich die Formulierungen des JEPs wurde etwas überarbeitet. Flexible Constructor Bodies werden in Java 25 finalisiert.
Weitere Use-Cases und Besondernheiten, die es zu beachten gibt, kannst du im Hauptartikel Flexible Constructor Bodies in Java: Code vor super() aufrufen nachlesen.
Structured Concurrency (Fourth Preview) – JEP 499
Structured Concurrency („Strukturierte Nebenläufigkeit“) ist eine moderne Herangehensweise für die Aufteilung von Aufgaben in kleinere, in virtuellen Threads parallel ausführbare Teile innerhalb eines im Quellcode klar erkennbaren Code-Blocks.
Dabei sind Start und Ende aller Teilaufgaben klar ersichtlich, und sobald der Code-Block der strukturierten Nebenläufigkeit verlassen wird, ist sichergestellt, dass alle Threads erfolgreich oder fehlerhaft beendet oder abgebrochen sind und dass der Status aller Teilaufgaben bekannt ist.
Structured-Concurrency-Blöcke können dabei ineinander verschachtelt werden, wie die folgende Grafik zeigt:

Durch verschiedene Strategien kann darüberhinaus festgelegt werden, ob z. B. die erfolgreiche oder fehlerhafte Beendigung einer Teilaufgabe direkt zum Abbruch aller anderen Teilaufgaben und zur erfolgreichen oder fehlerhaften Beendigung der Gesamt-Aufgabe führten soll.
Das folgende Code-Beispiel zeigt, wie eine Anwendung Wetterinformationen aus drei Quellen parallel ausliest und bei der ersten Antwort die anderen Anfragen abbricht und die Antwort zurückgibt:
WeatherResponse getWeatherFast(Location location)
throws InterruptedException, ExecutionException {
try (var scope = new ShutdownOnSuccess<AddressVerificationResponse>()) {
scope.fork(() -> weatherService.readFromStation1(location));
scope.fork(() -> weatherService.readFromStation2(location));
scope.fork(() -> weatherService.readFromStation3(location));
scope.join();
return scope.result();
}
}Code-Sprache: Java (java)Ohne Structured Concurrency würde diese Aufgabe deutlich längeren und komplexeren und dadurch auch fehleranfälligeren Code erfordern.
Eine ausführliche Beschreibung und zahlreiche weitere Beispiele findest du im Hauptartikel über Structured Concurrency.
Structured Concurrency wurde in Java 21 als Preview-Feature eingeführt und in Java 22 und Java 23 ohne Änderungen wiedervorgelegt. In Java 24 wird das Feature durch JDK Enhancement Proposal 499 erneut ohne Änderungen wiedervorgelegt.
Scoped Values (Fourth Preview) – JEP 487
Mit Scoped Values können wir Werte an direkte oder indirekte Methodenaufrufe übergeben, ohne sie als Methoden-Parameter definieren und ggf. durch eine lange Aufrufkette hindurchschleusen zu müssen.
Das klassische Beispiel ist der in einer Web-Anwendung eingeloggte User:
Anstatt ein User-Objekt an alle Methoden innerhalb der Webanwendung als Parameter zu übergeben, kann dieses in einem Scoped Value gespeichert werden. Alle Methoden, die innerhalb desselben Request-Bearbeitungs-Threads aufgerufen werden, können dann das User-Objekt aus diesem Scoped Value abrufen.
Das kommt dir bekannt vor?
Das liegt daran, dass wir solche Use-Cases bisher mit ThreadLocal-Variablen implementiert haben. Scoped Values haben jedoch eine ganze Reihe Vorteile, die ich im Hauptartikel über Scopes Values detailliert beschreibe.
Wie implementiert man nun so ein Scoped Value als Java-Code?
Nachdem wir den User authentifiziert haben, hinterlegen wir diesen mit ScopedValue.where() in einem Scoped Value und rufen dann im Kontext dieses Scoped Values mit run() den Anwendungscode auf:
public class Server {
public final static ScopedValue<User> LOGGED_IN_USER = ScopedValue.newInstance();
private void serve(Request request) {
. . .
User loggedInUser = authenticateUser(request);
ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.run(() -> restAdapter.processRequest(request));
. . .
}
}Code-Sprache: Java (java)Die innerhalb der run()-Methode aufgerufene Methode – und wiederum jede von dieser Methode direkt oder indirekt aufgerufene Methode – kann nun über ScopedValue.get() auf das User-Objekt zugreifen:
public class ApplicationService {
public void doSomethingSmart() {
User loggedInUser = Server.LOGGED_IN_USER.get();
. . .
}
}Code-Sprache: Java (java)Scoped Values wurden erstmals in Java 21 als Preview-Feature vorgestellt.
In Java 23 wurde das generische und funktionale Interface ScopedValue.CallableOp eingeführt, um Exception-Handling beim Aufruf von ScopedValue.call() und ScopedValue.callWhere() typsicher – und damit lesbarer und wartbarer – zu gestalten.
In Java 24 wurden durch JDK Enhancement Proposal 487 die Methoden ScopedValue.callWhere() und ScopedValue.runWhere() entfernt, um die Schnittstelle komplett „fluent“ zu gestalten. Diese Convenience-Methoden waren in Java 23 wie folgt definiert:
public static <T, R, X extends Throwable> R callWhere(
ScopedValue<T> key, T value, CallableOp<? extends R, X> op) throws X {
return where(key, value).call(op);
}
public static <T> void runWhere(ScopedValue<T> key, T value, Runnable op) {
where(key, value).run(op);
}Code-Sprache: Java (java)Statt callWhere() bzw. runWhere() musst du nun entsprechend where() gefolgt von call() bzw. run() aufrufen.
Simple Source Files and Instance Main Methods (Fourth Preview) – JEP 495
Wenn Java-AnfängerInnen ihr erstes Java-Programm schreiben, sieht das meist in etwas so aus:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Code-Sprache: Java (java)Hier werden eine ganze Menge Konzepte auf einmal vermittelt: Klassen, Sichtbarkeitsmodifikatoren, static, und (ungenutzte) Methodenargumente. Das kann schnell zu Überforderung führen.
Wäre es nicht schön, wenn wir das gleiche einfach wie folgt ausdrücken könnten?
void main() {
println("Hello world!");
}Code-Sprache: Java (java)Genau das wird durch Simple Source Files and Instance Main Methods ermöglicht!
- Ein Simple Source File – also eine einfache Quelldatei – ist eine .java-Datei, die keine explizite Klassenangabe enthält. Der Compiler erzeugt stattdessen eine sogenannte implizite Klasse.
- Eine Instance Main Method muss weder public noch static sein, noch muss sie Parameter haben.
Außerdem wird die neue Klasse java.io.IO mit den statischen Methoden print(), println() und readln() eingeführt. Diese Klasse liegt im java.base-Modul, welches in einfachen Quelldateien automatisch importiert wird (s. Abschnitt Module Import Declarations). Dadurch kann println() ohne vorangestelltes System.out und ohne import-Statement verwendet werden.
Weitere Einzelheiten und Beispiele sowie zu beachtende Einschränkungen und Regelungen zu überladenen main()-Methoden findest du im Hauptartikel über die Java-main()-Methode.
Feature-Historie
Dieses Feature wurde erstmals in Java 21 als „Unnamed Classes and Instance Main Methods“ veröffentlicht. In Java 22 wurde dann das Konzept der „impliziert deklarierten Klasse“ eingeführt, und in Java 23 kam die java.io.IO-Klasse hinzu.
In Java 24 wurde schließlich durch JDK Enhancement Proposal 495 der Begriff „Simple Source Files“ eingeführt und das Feature in „Simple Source Files and Instance Main Methods“ umbenannt.
Vector API (Ninth Incubator) – JEP 489
Die Vector API ist eine neue API, mit der mathematische Vektorrechnungen wie die folgende durchgeführt werden können:
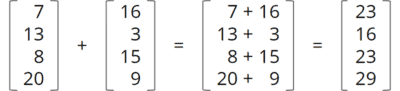
Das besondere an der neuen API ist, dass diese Berechnungen optimiert auf Vektor-Instruktionen moderner CPUs abgebildet werden. Dadurch können diese Berechnungen bis zu einer bestimmten Vektor-Größe in einem einzigen CPU-Zyklus durchgeführt werden.
Die Vector-API wird durch JDK Enhancement Proposal 489 zum neuten Mal im Incubator-Stadium vorgestellt. Sie wird so lange ein Incubator-Feature bleiben, bis dafür notwendige Funktionen aus Projekt Valhalla das Preview-Stadium erreicht haben.
Sobald die Vector-API ebenfalls das Preview-Stadium erreicht, werde ich sie detaillierter beschreiben.
Deprecations, Warnungen, Löschungen
Auch in Java 24 werden wieder Funktionalitäten als „deprecated” markiert, einige Funktionen führen zu Warnungen zur Laufzeit und andere wurden endgültig entfernt. Um welche Funktionalitäten es sich handelt, erfährst du in den nächsten Abschnitten.
Warn upon Use of Memory-Access Methods in sun.misc.Unsafe – JEP 498
Die in Java 1.4 (also vor über 20 Jahren) eingeführte sun.misc.Unsafe-Klasse war ein mächtiges, aber auch gefährliches Werkzeug, um direkt auf den Arbeitsspeicher (sowohl Heap als auch nativen, also nicht durch den Garbage Collector verwalteten Speicher) zuzugreifen.
Diese Klasse sollte eigentlich nie von EntwicklerInnen direkt verwendet werden. Doch zum einen konnte es (durch ein damals noch nicht existierendes Modulsystem) nicht verhindert werden, und zum anderen standen uns keine Alternativen zur Verfügung.
Doch heute gibt es diese Alternativen:
Als sicherer Ersatz stehen seit Java 9 VarHandles für den Zugriff auf den Java-Heap und seit Java 22 die Foreign Function & Memory API für den Zugriff auf nativen Speicher zur Verfügung.
Deshalb werden die Speicherzugriffsmethoden aus sun.misc.Unsafe Schritt für Schritt entfernt:
- Im ersten Schritt wurden in Java 23 die entsprechenden Methoden als deprecated for removal markiert.
- In Java 24 wird, durch JDK Enhancement Proposal 498 definiert, die Benutzung dieser Methoden zu Warnungen zur Laufzeit führen.
- Voraussichtlich in Java 26 wird die Benutzung dieser Methoden zu einer
UnsupportedOperationExceptionführen. - Und in einem späteren, noch nicht festgelegten Release werden die Methoden vollständig entfernt werden.
Was bedeutet das für uns?
Wir müssen mittelfristig unsere Anwendungen daraufhin überprüen, ob sie die betroffenen Methoden aus java.misc.Unsafe verwenden, und falls ja, auf die sichereren Alternativen VarHandles und die Foreign Function & Memory API umstellen.
Durch die VM-Einstellung --sun-misc-unsafe-memory-access=allow können wir die Warnungen in Java 24 deaktivieren. Das empfehle ich aber nicht, da wir die Änderung früher oder später ohnehin durchführen müssen, wenn wir auf neue Java-Versionen upgraden wollen. Außerdem wird es mit der nächsten Stufe, also voraussichtlich in Java 26, diese Option nicht mehr geben.
Folgende Werte stehen für diese VM-Option --sun-misc-unsafe-memory-access zur Verfügung:
allow– schaltet, wie eben erklärt, die Warnungen aus.warn– das ist die Default-Einstellung in Java 24, d. h. die Benutzung der Methoden ist nach wie vor erlaubt, führt aber zu einer Warnung zur Laufzeit beim ersten Aufruf einer solchen Methode.debug– führt bei jedem Aufruf (also nicht nur beim ersten) zu Warnungen sowie der Ausgabe eines Stacktraces.deny– führt beim Aufruf einer solchen Mehode zu einerUnsupportedOperationException. Dies wird voraussichtlich in in Java 26 die Standardeinstellung sein.
Eine vollständige Liste der betroffenen Methoden findest du übrigens im Abschnitt sun.misc.Unsafe memory-access methods and their replacements von JEP 471, durch den in Java 23 die Methoden als deprecated markiert wurden.
Permanently Disable the Security Manager – JEP 486
Der ursprünglich für die Absicherung von Java Applets entwickelte – und für heutige Java-Anwendungen nahezu irrelevante „Security Manager” wurde in Java 17 als „deprecated for removal” markiert. Dadurch sollten die Resourcen, die für die Wartung des Security Managers aufgebracht wurden, wichtigeren Projekten zugewiesen werden.
In Java 24 kann der Security Manager nicht mehr aktiviert werden, weder beim Start einer Anwendung noch während der Laufzeit. Der Versuch führt zu einer Fehlermeldung.
Die Deaktiverung des Security Managers ist in JDK Enhancement Proposal 486 dokumentiert.
In einer zukünftigen Java-Version wird der Security Manager dann vollständig entfernt werden.
ZGC: Remove the Non-Generational Mode – JEP 490
In Java 21 wurde der „Generational Mode” für den Z Garbage Collector (ZGC) eingeführt. Dieser teilt Objekte in kurzlebige (junge Generation) und langlebige (alte Generation) ein, um dadurch die Speicherbereinigung zu optimieren.
Seit Java 23 ist dieser Modus standardmäßig aktiviert, wenn ZGC ausgewählt wird. Er konnte allerdings durch die VM-Option -XX:+UseZGC -XX:-ZGenerational wieder deaktiviert werden.
Um nicht zwei Modi maintainen zu müssen, wird durch JDK Enhancement Proposal 490 der „Non-Generational Mode” in Java 24 entfernt.
Die VM-Option -XX:-ZGenerational hat keinen Effekt mehr und führt zu einer Warnung. In einer zukünftigen Java-Version wird sie entfernt werden und zu einer Fehlermeldung führen.
Remove the Windows 32-bit x86 Port – JEP 479
In Java 21 wurde die 32-Bit-Java-Version für Windows als „deprecated for removal” markiert. Zum einen gab es kaum noch Bedarf für diese Version, zum anderen war die Wartung aufwendig, und z. B. virtuelle Threads wurden in dieser Version gar nicht erst implementiert.
Konsequenterweise wird in Java 24 durch JDK Enhancement Proposal 479 die 32-Bit-Portierung für Windows vollständig entfernt.
Deprecate the 32-bit x86 Port for Removal – JEP 501
Mit der Entfernung der 32-Bit-Portierung für Windows (s. vorheriger Abschnitt) ist die 32-Bit-Portierung für Linux die letzte verbleibende 32-Bit-Portierung – und damit die letzte Portierung, für die die JDK-Entwickler Fallbacks für die 32-Bit-Architektur implementieren müssen.
Um diesen Extraaufwand in Zukunft vollständig zu eliminieren, wird durch JDK Enhancement Proposal 501 auch die Linux-32-Bit-Portierung als „deprecated for removal” markiert.
In einer zukünftigen Java-Version wird auch diese Portierung vollständig entfernt werden.
Sonstige Änderungen in Java 24
Nicht alle Features der neuen Java-Version werden uns im täglichen Programmieralltag begegnen. In diesem Kapitel findest du Änderungen, die nur für spezielle Anwendungsfälle relevant sind. Als fortgeschrittener Java-Entwickler solltest du von diesen Änderungen aber auf jeden Fall wenigstens einmal gehört haben.
Class-File API – JEP 484
Mit der Class-File API enthält Java 24 eine offizielle Schnittstelle, um kompilierten Java-Bytecode (also .class-Dateien) aus Java-Code heraus zu lesen und zu schreiben.
Die Class-File API ersetzt das im JDK weit verbreitete Bytecode-Manipulations-Frameworks ASM. Grund für die Eigenentwicklung ist der schnelle JDK-Release-Zyklus sowie die Tatsache, dass ASM der aktuellen Java-Version immer mindestens um eine Version hinterherhinkt, d. h. dass die in einem aktuellen JDK enthaltene ASM-Version maximal mit .class-Dateien der vorherigen Java-Version umgehen kann.
Mit der Veröffentlichung der Class-File API entfällt nun diese zyklische Abhängigkeit, und Java 24 kann nun auch von Java 24 erzeugte .class-Dateien inspizieren und modifizieren.
Das Class-File-API wurde in Java 22 erstmals als Preview-Feature vorgestellt und in Java 23 mit kleineren Verbesserungen in eine zweite Preview-Runde geschickt.
In Java 24 wird die neue API durch JDK Enhancement Proposal 484 – noch einmal mit kleineren Verbesserungen – finalisiert.
Da die meisten Java-EntwicklerInnen nur indirekt über Tools mit der Class-File-API arbeiten und diese nie direkt aufrufen werden, verzichte ich an dieser Stelle auf eine detaillierte Beschreibung der Schnittstelle. Falls du jedoch Interesse hast, findest du alle Details in JEP 484.
Prepare to Restrict the Use of JNI – JEP 472
Jegliche Interaktion zwischen Java-Code und nativem Code ist riskant, da sie zu undefiniertem Verhalten und Abstürzen führen kann (C-Code kann beispielsweise über die Grenzen eines Arrays hinaus in den Speicher schreiben). Das gilt sowohl für das Java Native Interface (JNI) als auch die Foreign Function & Memory API (FFM-API), welche JNI langfristig ablösen soll.
Status Quo
In der FFM-API wurden potentiell gefährliche Methoden von Beginn an als „restricted“ eingestuft, und ihre Benutzung musste explizit über die VM-Option --enable-native-access erlaubt werden. Andernfalls wurde zur Laufzeit eine IllegalCallerException ausgelöst.
Das heißt nicht, dass von der Verwendung dieser Methoden abgeraten wird, sondern lediglich, dass man sich über die Verwendung potentiell gefährlicher Funktionen bewusst sein soll – und sie dementsprechend explizit erlaubt muss.
Ausweitung auf JNI in Java 24
Durch JDK Enhancement Proposal 472 wird in Java 24 die Verwendung entsprechender JNI-Methoden zu Laufzeit-Warnungen führen. Diese Warnungen können – wie bisher die Exceptions bei der FFM-API – durch die VM-Option --enable-native-access verhindert werden.
Wie genau funktioniert --enable-native-access?
Du kannst den Zugriff auf nativen Code entweder uneingeschränkt für die gesamte Anwendung erlauben:
java --enable-native-access=ALL-UNNAMED ...
Oder, besser, du erlaubst nativen Zugriff nur auf bestimmte Module:
java --enable-native-access=MODUL1,MODUL2,MODUL3,... ...
Bei nicht explizit erlaubtem Zugriff würden sich nun – ohne weitere Anpassung – JNI und FFM-API unterschiedlich verhalten: JNI würde eine Warnung ausgeben, die FFM-API würde eine IllegalCallerException werfen.
Anpassung der FFM-API
Aus Konsistenzgründen entschieden sich die JDK Developer, das Verhalten der FFM-API zunächst aufzuweichen und die FFM-API standardmäßig ebenfalls Warnungen ausgeben zu lassen anstatt Exceptions auszulösen.
Konfiguration
Dieses Verhalten kann angepasst werden – und zwar für beide APIs einheitlich mit dem Kommandozeilenparameter --illegal-native-access. Dieser bietet folgende Optionen:
| VM-Option | Beschreibung |
|---|---|
--illegal-native-access=allow | Jeglicher Zugriff auf nativen Code wird erlaubt; es werden keine Warnungen ausgegeben und keine Exceptions geworfen. |
--illegal-native-access=warn | Zugriff auf nativen Code ist erlaubt, es werden allerdings Warnungen ausgegeben, sofern der Zugriff nicht explizit mit --enable-native-access erlaubt wurde. Dies ist die Standard-Einstellung in Java 24. |
--illegal-native-access=deny | Zugriff auf nativen Code führt zu einer IllegalCallerException, sofern der Zugriff nicht explizit mit --enable-native-access erlaubt wurde. |
Der Modus deny wird in einer zukünftigen Version zur Standard-Einstellung werden; dann werden sowohl JNI als auch FFM-API standardmäßig eine IllegalCallerException werfen.
In einer spätereren Version wird der --illegal-native-access-Parameter entfernt werden, und es wird nur noch den deny-Modus geben.
Quantum-Resistant Module-Lattice-Based Key Encapsulation Mechanism – JEP 496
Zukünftige Quantencomputer stellen eine Gefahr für die traditionellen kryptografischen Algorithmen wie RSA und Diffie-Hellman dar. Der Einsatz von ML-KEM (Module-Lattice-Based Key Encapsulation Mechanism – der Link führt zur Beschreibung des Verfahrens auf der Webseite des National Institute of Standards and Technology) soll es in Zukunft ermöglichen, Schlüssel auch im Zeitalter von Quantencomputern sicher auszutauschen.
Das folgende Beispiel zeigt, wie...
- der Empfänger ein ML-KEM-Schlüsselpaar erzeugt,
- der Sender durch Schlüsselkapselung mit dem öffentlichen Schlüssel des Empfängers einen geheimen Sitzungsschlüssel erzeugt und diesen verkapselt
- und der Empfänger den Sitzungsschlüssel wieder entkapselt.
Danach können Sender und Empfänger mit Hilfe des quantensicher übertragenen Sitzungsschlüssels sicher Nachrichten austauschen.
void main() throws GeneralSecurityException {
// Step 1 (Receiver): Create a ML-KEM public/private key pair:
KeyPairGenerator generator = KeyPairGenerator.getInstance("ML-KEM");
KeyPair keyPair = generator.generateKeyPair();
PublicKey receiverPublicKey = keyPair.getPublic();
PrivateKey receiverPrivateKey = keyPair.getPrivate();
// Step 2 (Sender, has the receiver's public key):
// Create a session key and encapsulate it:
KEM kem = KEM.getInstance("ML-KEM");
KEM.Encapsulator encapsulator = kem.newEncapsulator(receiverPublicKey);
KEM.Encapsulated encapsulated = encapsulator.encapsulate();
SecretKey sessionKey = encapsulated.key();
System.out.println(HexFormat.of().formatHex(sessionKey.getEncoded()));
byte[] keyEncapsulationMessage = encapsulated.encapsulation();
// Step 3 (Receiver, has the sender's key encapsulation message):
// Decapsulate the session key:
KEM kr = KEM.getInstance("ML-KEM");
KEM.Decapsulator decapsulator = kr.newDecapsulator(receiverPrivateKey);
SecretKey decapsulatedSessionKey = decapsulator.decapsulate(keyEncapsulationMessage);
System.out.println(HexFormat.of().formatHex(decapsulatedSessionKey.getEncoded()));
// Now sender and receiver can exchange messages
// using the securely transmitted session key.
// . . .
}Code-Sprache: Java (java)Wenn ich das Programm bei mir starte, erhalte ich z. B. folgende Ausgabe, die belegt, dass verkapselter und entkapselter Sitzungsschlüssel übereinstimmen:
7fac6ccf466d3ce0412cb8080280bb3c8cfb2fca630042aee2bf17a213ca82fe
7fac6ccf466d3ce0412cb8080280bb3c8cfb2fca630042aee2bf17a213ca82feCode-Sprache: Klartext (plaintext)Das Implementierung des quantensicheren ML-KEM-Verfahrens im JDK ist in JDK Enhancement Proposal 496 beschrieben. Dort findest du auch weitere Anwendungsbeispiele.
Quantum-Resistant Module-Lattice-Based Digital Signature Algorithm – JEP 497
Analog zu dem im vorherigen Abschnitt beschriebenen ML-KEM-Verfahren wird das ebenfalls quantensichere ML-DSA-Verfahren (Module-Lattice-Based Digital Signature Algorithm – auch dieser Link führt zum National Institute of Standards and Technology) ins JDK aufgenommen.
Das folgende Beispiel zeigt, wie...
- der Sender ein ML-DSA-Schlüsselpaar erzeugt,
- der Sender seine Nachricht mit seinem privaten Schlüssel signiert,
- und der Empfänger die Signatur mit dem öffentlichen Schlüssel des Senders verifiziert.
Der Empfänger kann somit sicherstellen, dass die Nachricht tatsächlich vom Sender kommt und nicht unterwegs modifiziert wurde.
import java.security.Signature;
void main() throws GeneralSecurityException {
// Step 1 (Sender): Create a ML-KEM public/private key pair:
KeyPairGenerator generator = KeyPairGenerator.getInstance("ML-DSA");
KeyPair keyPair = generator.generateKeyPair();
PublicKey senderPublicKey = keyPair.getPublic();
PrivateKey senderPrivateKey = keyPair.getPrivate();
// Step 2 (Sender): Sign a message using the private key:
byte[] message = "Roses bloom nightly.".getBytes(StandardCharsets.UTF_8);
Signature signer = Signature.getInstance("ML-DSA");
signer.initSign(senderPrivateKey);
signer.update(message);
byte[] signature = signer.sign();
// Step 3 (Receiver): Verify the message using the sender's public key:
Signature signatureVerifier = Signature.getInstance("ML-DSA");
signatureVerifier.initVerify(senderPublicKey);
signatureVerifier.update(message);
boolean verified = signatureVerifier.verify(signature);
. . .
}Code-Sprache: Java (java)Das Implementierung des quantensicheren ML-DSA-Verfahrens im JDK ist in JDK Enhancement Proposal 497 beschrieben.
Linking Run-Time Images without JMODs – JEP 493
Eine JDK-Installation besteht aus zwei Komponenten:
- einem Laufzeit-Image (das ausführbare Java-System)
- und einem Satz von Java-Modul-Dateien im jmod-Verzeichnis.
Die Java-Module sind allerdings auch im Laufzeit-Image enthalten, in der Datei lib/modules.
Warum diese Doppelung?
Die Datei lib/modules wird zur Laufzeit einer Java-Anwendung verwendet; die Modul-Dateien im jmod-Verzeichnis werden benötigt, um mit dem jlink-Tool ein benutzerdefiniertes Laufzeit-Image zu generieren.
Durch JDK Enhancement Proposal 493 wird es in Zukunft möglich sein, ein JDK ohne jmod-Dateien zu erstellen; das jlink-Tool wird dann die Modulinformationen aus dem Laufzeit-Image entnehmen.
Dadurch kann die Größe eines JDKs um etwa 25 % reduziert werden – das ist insbesondere im Cloud-Umfeld relevant, wo erhöhter Speicherbedarf und höherer Traffic (durch das Übertragen der Images) zu höheren Kosten führt.
Die neue Option ist standardmäßig deaktiviert; die JDK-Anbieter müssen sich also bei der Generiereung ihres JDKs proaktiv für diese Option entscheiden.
In einer zukünftigen Java-Version könnte die Option standardmäßig aktiviert werden.
Late Barrier Expansion for G1 – JEP 475
Um diesen JEP zu verstehen, muss man zunächst einmal wissen, was „Barrier“ und „Expansion“ bedeuten.
Garbage Collector Barrier
Im Kontext der Garbage Collection bezeichnet eine „Barrier“ ein Stück Code, das vor und/oder nach dem Zugriff auf Java-Objekte ausgeführt wird.
So wird z. B. über Write Barriers protokolliert, welche Referenzen von Objekten der alten Generation auf Objekte der jungen Generation existieren, so dass die junge Generation aufgeräumt werden kann, ohne dabei jedes Mal die alte Generation vollständig scannen zu müssen.
Und wenn der Garbage Collector beim Defragmentieren ein Objekt im Heap verschoben hat, dann sorgt eine Read Barrier dafür, dass beim Zugriff auf dieses Objekt der Pointer darauf aktualisiert wird.
Diese Barriers werden beim Laden eines Java-Programms durch die JVM automatisch in den Maschinencode eingefügt.
Bytecode Expansion
Wenn ein Java-Programm kompiliert wird, entsteht daraus zunächst Plattform-unabhänger Bytecode. Beim Start einer Java-Anwendung wird dieser Bytecode dann in hoch-optimierten Maschinencode umgewandelt.
Zum Beispiel können Methoden inlined werden, d. h. der Code innerhalb der Methode wird an jede Stelle kopiert, an der die Methode aufgerufen wird – das erspart den Overhead des Methodenaufrufs. Zudem können Schleifen entrollt werden, d. h. eine Schleife wird durch mehrmalige Wiederholung desselben Maschinencodes ersetzt, um den Overhead der Überprüfung der Abbruchbedingung zu eliminieren.
Aufgrund dieser und anderer Optimierungen belegt der Maschinencode in der Regel mehr Speicher als der Bytecode. Daher wird dieser Vorgang auch als „Bytecode Expansion“ oder nur „Expansion“ bezeichnet.
Barrier Expansion – Status Quo
Aktuell arbeitet G1 mit „Early Barrier Expansion“:
Der Barrier-Code liegt zunächst in einer plattformunabhängigen Zwischenstufe zwischen Bytecode und Maschinencode vor, der sogenannten „Intermediate Representation“ (IR).
Der Byte-Code der Anwendung wird ebenfalls zunächst in die „Intermediate Representation“ umgewandelt und dann mit dem Barrier-IR-Code kombiniert.
Danach wird der gesamte IR-Code über mehrere Optimierungsstufen in Maschinencode übersetzt:

Das hat zwei Vorteile:
- Der Barrier-Code kann, da er in der plattformunabhängigen Intermediate Representation vorliegt, ohne Anpassungen auf allen Plattformen verwendet werden.
- Der Compiler kann den kompletten Code optimieren, d. h. die Optimierung des Barrier-Codes kann im Kontext des Anwendungscodes erfolgen.
Early Expansion hat allerdings zwei signifikante Nachteile:
- Der Compiler muss mehr IR-Code (Anwendungs- und Barrier-Code) compilieren.
- Die Entwickler des Garbage Collectors können nicht vorhersehen, wie der Compiler den Barrier-Code optimiert und potentielle Fehler nur schwer reproduzieren.
Die JDK-Entwickler entschieden, dass die Nachteile schwerwiegender sind als die Vorteile und Implementierten daher im Rahmen von JDK Enhancement Proposal 475 die „Late Barrier Expansion“.
Late Barrier Expansion
Bei der „Late Barrier Expansion“ wird der Barrier Code nicht als IR-Code implementiert, sondern als bereits optimierter Maschinencode. Und dieser wird erst nach der Compilierung und Optimierung des Anwendungscodes in den Maschinencode der Anwendung integriert:

Dadurch, dass der Compiler nun weniger Code optimieren muss, werden Anwendungen nach Messungen der JDK-Entwickler um etwa 10–20 % schneller!
Der Z Garbage Collector (ZGC) arbeitet übrigens bereits seit seiner Einführung in Java 15 mit Late Barrier Expansion.
Deprecate LockingMode Option, along with LM_LEGACY and LM_MONITOR
In Java 21 wurde für das Objekt-Monitor-Locking (der Mechanimus zur Sperrung eines kritischen Bereichs für andere Threads) der neue „Lightweight Locking“-Modus eingeführt. Dieser kann bisher über die ebenfalls neu eingeführte VM-Option -XX:LockingMode=2 anstelle des bis dahin standardmäßig verwendeten „Stack Locking“-Modus aktiviert werden.
Es können seither folgende Locking-Modi ausgewählt werden:
-XX:LockingMode=0– Ausschließlich schwergewichtige Monitor-Objekte (LM_MONITOR)-XX:LockingMode=1– Stack Locking + Monitor-Objekte bei Contention (LM_LEGACY)-XX:LockingMode=2– Lightweight Locking + Monitor-Objekte bei Contention (LM_LIGHTWEIGHT)
In Java 22 wurde die experimentelle Option zu einer produktiven Option befördert.
In Java 23 wurde Lightweight Locking dann zum neuen Default-Modus.
In Java 24 werden die VM-Option -XX:LockingMode sowie die auswählbaren Modi LM_MONITOR und LM_LEGACY sowie der Stack-Locking-Mechanismus als „deprecated“ markiert.
Der Mechanismus „schwergewichtige Monitor-Objekte“ selbst ist nicht „deprecated“, sollte aber nicht mehr über -XX:LockingMode=0 ausgewählt werden, sondern – wie schon vor Java 21 – über die VM-Option -XX:+UseHeavyMonitors.
In Java 26 hat -XX:LockingMode keinen Effekt mehr, und in Java 27 wird die Option vollständig entfernt werden.
(Für diese Änderung gibt es kein JDK Enhancement Proposal; sie ist im Bug Tracker unter JDK-8334299 beschrieben.)
Support für Unicode 16.0
In Java 24 wird der Unicode-Support auf Version 16.0 angehoben.
Warum ist das relevant?
Alle zeichenverarbeitenden Klassen, wie String und Character, müssen mit den in der neuen Unicode-Version eingeführten Zeichen und Codeblöcken umgehen können.
Ein Beispiel findest du im Abschnitt Unicode 10 des Artikels über Java 11.
(Für die Abhebung der Unicode-Version auf 16.0 gibt es kein JDK Enhancement Proposal; die Änderung ist im Bug-Tracker unter JDK-8319993 aufgeführt.)
Vollständige Liste aller Änderungen in Java 24
In diesem Artikel habe ich dir alle JDK Enhancement Proposals (JEPs) sowie eine Auswahl weiterer Änderungen ohne JEP vorgestellt, die in Java 24 umgesetzt wurden. Eine vollständige Auflistung aller Änderungen findest du in den Java 24 Release Notes.
Fazit
Wow – was für ein umfangreiches Release!
Das waren sie also, die 24 JDK Enhancement Proposals und zwei kleinere Änderungen aus den Release Notes. Hier noch mal eine kurze Zusammenfassung:
- Mit der Stream Gatherers API können wir unsere eigenen, intermediären Stream-Operationen schreiben.
- In virtuellen Threads können wir jetzt
synchronizedum blockierende Aufrufe verwenden, ohne dass dadurch der virtuelle Thread an seinen Carrier gepinnt wird. - Mit Ahead-of-Time Class Loading & Linking, der logischen Weiterentwicklung von Class Data Sharing, starten Anwendungen (nach Aussage der JDK-Entwickler) um bis zu 42 % schneller.
- Mit der Key Derivation Function API und den quantensicheren Verschlüsselungsverfahren ist Java noch sicherer geworden.
- Die Gargabe Collectoren Shenandoah und G1 wurden optimiert: Shenandoah hat einen „Generational Mode“ bekommen, und im G1 wurde aus der „Early Barrier Expansion“ eine „Late Barrier Expansion“ gemacht. Im ZGC wurde der alte „Non-Generational Mode“ entfernt.
- Durch Compact Object Headers können die Header eines jeden Java Objects auf dem Heap um vier Bytes verkürzt und damit der Memory Footprint der gesamten Anwendung signifikant reduziert werden.
- Primitive Type Patterns, Flexible Constructor Bodies, Structured Concurrency und die Vector API wurden ohne Änderungen als Preview- bzw. Incubator-Features wiedervorgelegt.
- Implicitly Declared Classes and Instance Main Methods wurde in Simple Source Files and Instance Main Methods umgenannt.
- Bei der Verwendung von
import modulekönnen wir Mehrdeutigkeiten nun auch mit einem Package-Import auflösen. Und der Import des Modulsjava.semacht nun auch die Klassen desjava.base-Moduls ohne weitere Imports verfügbar. - Die Convenience-Methoden
ScopedValues.runWhere()undcallWhere()wurden im Sinne einer „Fluent API“ entfernt. - Die Verwendung der Speicherzugriffsmethoden in
sun.misc.Unsafeführt ab Java 24 zu Laufzeitwarnungen. - Der Security Manager wurde abgeschaltet.
- Die 32-Bit-Windows-Version von Java wurde entfernt, und die 32-Bit-Linux-Version wurde als „deprecated“ gekennzeichnet.
- Die finalisierte Class-File API ersetzt das Byte-Code-Manipulations-Framework ASM.
- Die Benutzung unsicherer JNI-Methoden führt zu Warnungen, sofern sie nicht beim Programmstart explizit erlaubt wurde.
- JDK-Images können auch ohne jmod-Dateien ausgeliefert werden, was ihre Größe um ca. 25 % reduziert.
- Die VM-Option
-XX:LockingModewurde als „deprecated“ markiert. - Der Unicode-Support wird auf Version 16.0 angehoben.
Java 24 kannst du hier herunterladen. Falls du zuvor eine Preview-Version installiert hattest: du brauchst mindestens Build 26, um alle in diesem Artikel gezeigten Quellcodes compilieren zu können.
Welche der neuen Java 24-Features findest du am spannendsten? Welches Feature vermisst du? Teile deine Meinung in den Kommentaren!