


Dateien schnell und einfach lesen
(Java Datei Tutorial)
Für das Lesen und Schreiben von Dateien in Java gibt es in den Packages java.io und java.nio.file zahlreiche Klassen. Seit der Einführung der Java NIO.2 (New I/O) File API verliert man – nicht nur als Einsteiger – leicht den Überblick. Viele Datei-Operationen lassen sich seither auf mehrere Arten durchführen.
Diese Artikelserie stellt zuerst einfache Utility-Methoden vor, um Dateien zu lesen und zu schreiben. In späteren Teilen werden komplexere und fortgeschrittene Methoden behandelt: über Channels und Buffers bis hin zu Memory-Mapped I/O (es macht nichts, wenn dir das an dieser Stelle noch nichts sagt).
Der erste Artikel behandelt das Lesen von Dateien. Du lernst zunächst, wie man Dateien einliest, die komplett in den Arbeitsspeicher passen:
- Wie liest man am einfachsten eine Textdatei in einen String (oder eine String-Liste)?
- Wie liest man eine Binärdatei in ein Byte-Array?
Danach geht es weiter zu größeren Dateien und den dafür zuständigen Klassen:
- Wie liest man größere Dateien und verarbeitet sie gleichzeitig weiter (um nicht die komplette Datei im Speicher halten zu müssen)?
- Wann verwendet man
FileReader,FileInputStream,InputStreamReader,BufferedInputStreamundBufferedReader? - Wann verwendet man
Files.newInputStream()undFiles.newBufferedReader()?
Außerdem (und das gilt sowohl für kleine als auch für große Dateien):
- Was muss man beachten, damit der Dateizugriff auf jedem Betriebssystem funktioniert?
Wie liest man in Java am einfachsten eine Datei?
Bis einschließlich Java 6 musste man für das Lesen einer Datei mehrere Zeilen Programmcode um einen FileInputStream herum schreiben. Dabei musste man darauf achten, dass man diesen nach dem Lesen – und auch im Fehlerfall – wieder korrekt schließt. "Try-with-resources" (also das automatische Schließen aller im try-Block geöffneten Resourcen) gab es damals noch nicht.
Nur über Drittanbieter-Libraries (z. B. Apache Commons oder Guava) konnte man auf komfortablere Möglichkeiten zurückgreifen.
Mit Java 7 kam dann die über das JSR 203 die langersehnte "NIO.2 File API" (NIO steht für New I/O). Mit der neuen API kam unter anderem die Utility-Klasse java.nio.file.Files, über die du mit einem einzigen Methoden-Aufruf Text- sowie Binärdateien komplett einlesen kannst.
Welche Methoden das im Detail sind, erfährst du in den folgenden Abschnitten.
Laden einer Binärdatei in ein Byte-Array
Du kannst den kompletten Inhalt einer Datei über die Methode Files.readAllBytes() in ein Byte-Array einlesen:
String fileName = ...;
byte[] bytes = Files.readAllBytes(Path.of(fileName));Code-Sprache: Java (java)Die Klasse Path ist dabei eine Abstraktion von Datei- und Verzeichnisnamen, deren Details hier erstmal nicht relevant sind. Auf diese gehe ich in einem späteren Artikel näher ein. Zunächst genügt es zu wissen, dass du ein Path-Objekt über Paths.get() oder – seit Java 11 etwas eleganter – über Path.of() erstellen kannst.
Laden einer Textdatei in einen String
Möchtest du den Inhalt einer Textdatei in einen String laden, geht das – seit Java 11 – über die Methode Files.readString() wie folgt:
String fileName = ...;
String text = Files.readString(Path.of(fileName));Code-Sprache: Java (java)Die Methode readString() ruft dabei intern wiederum readAllBytes() auf und wandelt danach die Binärdaten in die gewünschte Zeichenkette um.
Zeilenweises Laden einer Textdatei in eine String-Liste
Der Inhalt von Textdateien ist in den allermeisten Fällen auf mehrere Zeilen verteilt. Möchtest du den Text zeilenweise verarbeiten, brauchst du dir nicht selbst die Mühe zu machen, den eingelesenen Text aufzusplitten. Dies kann direkt beim Laden erfolgen, in dem du die – seit Java 8 verfügbare – Methode readAllLines() verwendest:
String fileName = ...;
List<String> lines = Files.readAllLines(Path.of(fileName));Code-Sprache: Java (java)Danach kannst du leicht über die erhaltene String-Liste iterieren und diese weiterverarbeiten.
Zeilenweises Laden einer Textdatei in einen String-Stream
In Java 8 wurden Streams eingeführt. Entsprechend wurde in derselben Java-Version die Klasse Files um die Methode lines() erweitert, die die Zeilen einer Textdatei nicht als String-Liste zurückzuliefert, sondern als Stream von Strings:
String fileName = ...;
Stream<String> lines = Files.lines(Path.of(fileName));Code-Sprache: Java (java)So könntest du beispielsweise mit nur einem Code-Statement alle Zeilen einer Textdatei ausgeben, die die Zeichenkette "foo" enthalten:
Files.lines(Path.of(fileName))
.filter(line -> line.contains("foo"))
.forEach(System.out::println);Code-Sprache: Java (java)java.nio.file.Files – Zusammenfassung
Mit den vier gezeigten Methoden lassen sich viele Anwendungsfälle abdecken. Allerdings sollten die gelesenen Dateien nicht zu groß sein, da diese komplett in den Arbeitsspeicher geladen werden. Mit einem HD-Film solltest du das also nicht versuchen. Doch auch für kleinere Dateien gibt es gute Gründe diese nicht komplett in den RAM zu laden:
- Eventuell möchte man die gelesenen Daten so schnell wie möglich weiterverarbeiten, und zwar bevor die Datei komplett geladen wurde.
- Läuft deine Software in Containern oder als "Function-as-a-Service", könnte Arbeitsspeicher u. U. relativ teuer sein.
Wie du Dateien Stück für Stück einlesen und dabei direkt verarbeiten kannst, wird im folgenden Kapitel beschrieben.
Wie verarbeitet man große Dateien, ohne sie komplett im Arbeitsspeicher halten zu müssen?
Und damit kommen wir zu den Funktionen, die schon vor Java 7 verfügbar waren – also diejenigen, die das "mal eben einlesen" einer kleinen Datei zu einer komplizierten Angelegenheit gemacht haben.
Lesen großer Binärdateien mit FileInputStream
Im einfachsten Fall lesen wir eine Binärdatei Byte für Byte und verarbeiten diese Bytes weiter. Diese Aufgabe erledigt die Klasse FileInputStream. Im folgenden Beispiel wird sie verwendet, um den Inhalt einer Datei Byte für Byte auf der Konsole auszugeben.
String fileName = ... ;
try (FileInputStream is = new FileInputStream(fileName)) {
int b;
while ((b = is.read()) != -1) {
System.out.println("Byte: " + b);
}
}Code-Sprache: Java (java)Die Methode FileInputStream.read() liest dabei jeweils ein Byte aus der Datei. Ist das Ende der Datei erreicht, wird -1 zurückgegeben. Die Funktionalität dieser Klasse ist zum größten Teil nativ (also nicht in Java) implementiert, da sie direkt auf die I/O-Funktionalität des Betriebssystem zugreift.
Dieser Zugriff ist relativ teuer: Das Laden einer 100 Millionen Byte großen Testdatei über einen FileInputStream dauert auf meinem System knapp 190 Sekunden. Das sind nur etwa 0,5 MB pro Sekunde.
Lesen großer Binärdateien mit dem NIO.2 InputStream
Mit der NIO.2 File API in Java 7 kam mit Files.newInputStream() eine zweite Methode hinzu, um einen InputStream zu erzeugen:
String fileName = ...;
try (InputStream is = Files.newInputStream(Path.of(fileName))) {
int b;
while ((b = is.read()) != -1) {
System.out.println("Byte: " + b);
}
}Code-Sprache: Java (java)Diese Methode liefert einen ChannelInputStream anstatt eines FileInputStreams, da NIO.2 unter der Haube mit sogenannten Channels arbeitet. An der Geschwindigkeit ändert sich dadurch in meinen Tests nichts.
Schneller lesen mit dem BufferedInputStream
Beschleunigt werden kann der Zugriff mit dem BufferedInputStream. Dieser wird sozusagen um den FileInputStream gelegt und lädt die Daten vom Betriebssystem nicht Byte für Byte, sondern in Blöcken von standardmäßig 8 KB und speichert diese zwischen. Die Bytes können dann wiederum nach und nach ausgelesen werden. Dieses mal aber aus dem Arbeitsspeicher, was um ein Vielfaches schneller geht.
String fileName = ...;
try (FileInputStream is = new FileInputStream(fileName);
BufferedInputStream bis = new BufferedInputStream(is)) {
int b;
while ((b = bis.read()) != -1) {
System.out.println("Byte: " + b);
}
}Code-Sprache: Java (java)Dieselbe Datei wird durch diesen Code in nur 270 ms eingelesen, also um den Faktor 700 schneller. Das sind 370 MB pro Sekunde, ein hervorragender Wert.
Man sollte also fast immer einen BufferedInputStream verwenden. Die einzige Ausnahme ist, wenn man die Daten über den FileInputStream nicht Byte für Byte liest, sondern in größeren Blöcken, deren Größe möglichst an die Blockgröße des Dateisystems angepasst ist. Wenn du dir unsicher bist, ob sich der BufferedInputStream für deinen speziellen Einsatzbereich lohnt, dann probier es einfach aus.
Lesen großer Textdateien mit dem FileReader
Textdateien sind letztendlich auch Binärdateien. Beim Laden werden Bytes in Zeichen umgewandelt. Diese Aufgabe übernimmt die Klasse InputStreamReader. Wenn du diese um einen FileInputStream legst, kannst du anstelle von Bytes Zeichen lesen und ausgeben:
String fileName = ...;
try (FileInputStream is = new FileInputStream(fileName);
InputStreamReader reader = new InputStreamReader(is)) {
int c;
while ((c = reader.read()) != -1) {
System.out.println("Char: " + (char) c);
}
}Code-Sprache: Java (java)Etwas komfortabler geht es mit dem FileReader: Dieser kombiniert FileInputStream und InputStreamReader, so dass folgender Code entsteht, der äquivalent ist zu dem oben:
String fileName = ...;
try (FileReader reader = new FileReader(fileName)) {
int c;
while ((c = reader.read()) != -1) {
System.out.println("Char: " + (char) c);
}
}Code-Sprache: Java (java)Der InputStreamReader verwendet intern ebenfalls einen 8 KB-Puffer. Das Einlesen der 100 Millionen Byte großen Textdatei dauert Zeichen für Zeichen etwa 3,8 s.
Textdateien schneller lesen mit dem BufferedReader
Obwohl der InputStreamReader schon ziemich schnell ist, kann das Einlesen von Texten noch weiter beschleunigt werden – mit dem BufferedReader:
String fileName = ...;
try (FileReader reader = new FileReader(fileName);
BufferedReader bufferedReader = new BufferedReader((reader))) {
int c;
while ((c = bufferedReader.read()) != -1) {
System.out.println("Char: " + (char) c);
}
}Code-Sprache: Java (java)Dadurch wird die Zeit für das Einlesen der Testdatei auf etwa 1,3 s reduziert. Dies erreicht der BufferedReader, indem er dem 8 KB-Puffer des InputStreamReaders noch einen Puffer für dekodierte 8192 Zeichen zur Seite stellt.
Ein weiterer Vorteil des BufferedReader ist, dass dieser die zusätzliche Methode readLine() anbietet, mit der du die Textdatei nicht nur Zeichen für Zeichen, sondern auch Zeile für Zeile einlesen und verarbeiten kannst:
String fileName = ...;
try (FileReader reader = new FileReader(fileName);
BufferedReader bufferedReader = new BufferedReader((reader))) {
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println("Line: " + line);
}
}Code-Sprache: Java (java)Das Einlesen kompletter Zeilen reduziert die Gesamtzeit für das Einlesen der Testdatei weiter auf etwa 600 ms.
Textdateien schneller lesen mit dem NIO.2 BufferedReader
Die NIO.2 File API bietet mit Files.newBufferedReader() eine Methode, um direkt einen BufferedReader zu erzeugen:
String fileName = ...;
try (BufferedReader reader = Files.newBufferedReader(Path.of(fileName))) {
int c;
while ((c = reader.read()) != -1) {
System.out.println("Char: " + (char) c);
}
}Code-Sprache: Java (java)Dieser entspricht von der Geschwindigkeit dem "klassisch" erstellten BufferedReader und benötigt wie dieser etwa 1,3 Sekunden, um die gesamte Datei einzulesen.
Übersicht Performance
Das folgende Diagramm zeigt noch einmal alle vorgestellten Methoden und die Zeit, die diese jeweils für das Einlesen einer 100 Millionen Byte großen Datei benötigen:
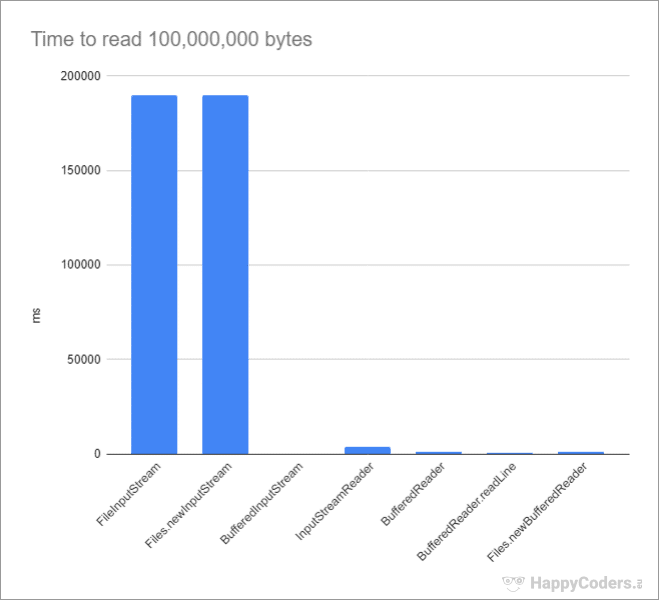
Der große Abstand zwischen "unbuffered" und "buffered" führt dazu, dass die "buffered" Methoden im Diagramm oben kaum erkennbar sind. Daher hier ein zweites Diagramm, das nur die "buffered" Methoden darstellt:

Übersicht FileInputStream, FileReader, InputStreamReader, BufferedInputStream, BufferedReader
In den letzten Abschnitten wurden zahlreiche Klassen zum Lesen von Dateien aus dem java.io-Paket vorgestellt. Die folgende Grafik zeigt dir noch einmal den Zusammenhang all dieser Klassen. Falls dieses Thema neu für dich ist, hilft es hier immer wieder einmal draufzuschauen.

Die durchgezogenen Linien stellen den Fluss von Binärdaten dar, die gestrichelten Linien zeigen den Fluss von Zeichen-Daten, also Characters oder Strings. Der FileReader ist die Kombination aus FileInputStream und InputStreamReader.
Betriebssystem-Unabhängigkeit
Im letzten Kapitel haben wir sorglos Textdateien eingelesen. Leider ist es nicht immer ganz so einfach: Zeichenkodierungen, Zeilenumbrüche und Pfad-Trennzeichen machen auch erfahrenen Programmierern immer wieder das Leben schwer.
Zeichenkodierung
Hast Du schon einmal folgendes gesehen?

Oder so etwas?

Das passiert, wenn beim Lesen und Schreiben einer Datei unterschiedliche Zeichenkodierungen verwendet werden.
Bei der Vorstellung der Klasse InputStreamReader habe ich kurz erwähnt, dass diese die eingelesenen Bytes (Zahlen) in Zeichen (Buchstaben, Sonderzeichen, etc.) umwandelt. Die sogenannte Zeichenkodierung bestimmt, welches Zeichen durch welche Zahl kodiert wird.
Eine kurze Geschichte der Zeichenkodierungen
Aus historischen Gründen gibt es verschiedene Zeichenkodierungen. 1963 wurde mit ASCII die erste Zeichenkodierung standardisiert. Diese konnte zunächst nur 128 (Steuer-)Zeichen darstellen. Deutsche Umlaute waren genauso wenig enthalten wie z. B. kyrillische oder griechische Buchstaben. Daher wurden zunächst mit ISO-8859 15 zusätzliche, jeweils 256 Zeichen enthaltende, Zeichenkodierungen für verschiedene Zwecke geschaffen, z. B. ISO-8859-1 für westeuropäische Sprachen, ISO-8859-5 für Kyrillisch oder ISO-8859-7 für Griechisch. Microsoft hat für Windows ISO-8859-1 leicht abgewandelt und Windows-1252 erschaffen.
Um dieses Chaos zu beseitigen, wurde 1991 mit ein weltweit einheitlicher Standard geschaffen: Unicode. Aktuell (November 2019) enthält Unicode 137.994 verschiedene Zeichen. Durch ein einzelnes Byte können maximal 256 Zeichen repräsentiert werden. Daher wurden verschiedene Kodierungen entwickelt, um alle Unicode-Zeichen auf ein oder mehrere Bytes abzubilden. Die am meisten verbreitete ist UTF-8. Aktuell wird sie auf 94,3 % aller Webseiten verwendet (laut der zuvor verlinkten Wikipedia-Seite).
Bei UTF-8 werden die ersten 128 Zeichen (also z. B. 'A' bis 'Z', 'a' bis 'z' und '0' bis '9') durch die gleichen Bytes dargestellt, wie in ASCII. Das ist der Grund, warum diese Zeichen – auch bei falsch eingestellter Kodierung – immer lesbar sind. Deutsche Umlaute werden durch jeweils zwei Bytes repräsentiert. Deshalb stehen im ersten Beispiel oben (in dem ich den Text als UTF-8 gespeichert und dann als ISO-8559-1 geladen habe) an den Stellen der Umlaute jeweils zwei Sonderzeichen. Im zweiten Beispiel habe ich den Text als ISO-8859-1 gespeichert und dann als UTF-8 geladen. Da die Ein-Byte-Repräsentation der Umlaute aus ISO-8859-1 in UTF-8 keinen Sinn ergibt, hat der InputStreamReader an den entsprechenden Stellen Fragezeichen eingefügt.
Es muss also sichergestellt werden, dass beim Einlesen einer Datei der gleiche Zeichensatz verwendet wird wie beim Speichern.
Welche Zeichenkodierung verwendet Java standardmäßig zum Lesen von Textdateien?
Gibt man (wie in den vorangegangenen Beispielen) keine Zeichenkodierung an, wird eine Standard-Kodierung verwendet. Und jetzt wird es gefährlich: Diese kann unterschiedlich sein, je nachdem welche Java-Version und welche Methode man zum Lesen der Datei verwendet:
- Verwendet man
FileReaderoderInputStreamReader, wird intern die MethodeStreamDecoder.forInputStreamReader()aufgerufen, welche bei nicht angegebener ZeichenkodierungCharset.defaultCharset()verwendet. Diese Methode wiederum liest die Kodierung aus der System-Property "file.encoding". Ist diese nicht angegeben, wird bis Java 5 ISO-8859-1 verwendet und ab Java 6 UTF-8. - Verwendet man hingegen
Files.readString(),Files.readAllLines(),Files.lines()oderFiles.newBufferedReader()ohne Zeichenkodierung, wird direkt UTF-8 verwendet, ohne die o. g. System-Property zu prüfen.
Um auf Nummer Sicher zu gehen, sollte man also immer eine Zeichenkodierung angeben. Wenn möglich (d. h. wenn keine Kompatibilität zu alten Dateien sichergestellt werden muss) sollte man die am weitesten verbreitete Kodierung, UTF-8, verwenden.
Wie gebe ich die Zeichenkodierung beim Lesen einer Textdatei an?
Alle bisher vorgestellten Methoden bieten eine Variante an, bei der die Zeichenkodierung mit übergeben werden kann. Die Kodierung wird als Objekt der Klasse Charset übergeben. Konstanten für Standard-Kodierungen findet man in der Klasse StandardCharsets. Im Folgenden findest Du alle Methoden mit der expliziten Angabe von UTF-8 als Kodierung:
Files.readString(path, StandardCharsets.UTF_8)Files.readAllLines(path, StandardCharsets.UTF_8)Files.lines(path, StandardCharsets.UTF_8)new FileReader(file, StandardCharsets.UTF_8)// diese Methode gibt es erst seit Java 11new InputStreamReader(is, StandardCharsets.UTF_8)Files.newBufferedReader(path, StandardCharsets.UTF_8)
Zeilenumbrüche
Eine weitere Hürde beim Laden von Textdateien ist die Tatsache, dass unter Windows Zeilenumbrüche anders kodiert werden als unter Linux und Mac.
- Unter Linux und Mac wird ein Zeilenumbruch durch das "Line Feed"-Zeichen (Escape-Sequenz "\n", ASCII-Code 10, hexadezimal
0A) dargestellt. - Windows benutzt die Kombination "Carriage Return"+"Line Feed" (Escape-Sequenz "\r\n", ASCII-Codes 13 und 10, bzw. hexadezimal
0D0A).
Glücklicherweise können heutzutage die meisten Programme mit beiden Kodierungen umgehen. Das war nicht immer so. Früher passierte es beim Austausch von Textdateien zwischen verschiedenen Betriebssystemen regelmäßig, dass entweder alle Zeilenumbrüche verschwanden und der komplette Text in einer Zeile stand, oder aber dass am Ende jeder Zeile ein Sonderzeichen erschien.
Wenn du mit Files.readAllLines() oder Files.lines() eine Textdatei zeilenweise einliest, erkennt Java die Zeilenumbrüche automatisch richtig. Möchtest du einen Text mit eigenem Programmcode in Zeilen aufsplitten, kannst du das wie folgt mit String.split() machen:
String[] lines = text.split("r?n");Code-Sprache: Java (java)Beim Schreiben von Dateien (s. Artikel "Dateien schnell und einfach schreiben") empfehle ich grundsätzlich die Linux-Variante zu verwenden, da heutzutage so gut wie jedes Windows-Programm (seit 2018 sogar Notepad!) damit umgehen kann.
Beim Erstellen eines formatierten Strings mit String.format() musst Du darauf achten, wie Du den Zeilenumbruch angibst:
String.format("Hallo%n")fügt einen Betriebssystem-spezifischen Zeilenumbruch ein. Das Ergebnis unterscheidet sich also je nach Betriebssystem, auf dem dein Programm ausgeführt wird.String.format("Hallo\n")fügt unabhängig vom Betriebssystem immer einen Linux-Zeilenumbruch ein.
Du kannst das mit folgendem Programm ausprobieren:
public class LineBreaks {
public static void main(String[] args) {
System.out.println(String.format("Hallo%n").length());
System.out.println(String.format("Hallon").length());
}
}Code-Sprache: Java (java)Unter Linux / Mac gibt es 6 und 6 aus. Unter Windows hingegen 7 und 6, da der mit "%n" für Windows generierte Zeilenumbruch aus einem Zeichen mehr besteht.
Falls du den Zeilentrenner des aktuellen Systems benötigst, erhälst du diesen über System.lineSeparator().
Pfadnamen
Auch bei Pfadnamen müssen wir Unterschiede zwischen den Betriebssystemen berücksichtigen. Während unter Windows absolute Pfade mit einem Laufwerksbuchstaben und einem Doppelpunkt (z. B. "C:") beginnen und Verzeichnisse durch einen Backslash ('\') getrennt werden, werden diese unter Linux durch einen regulären Schrägstrich ('/') getrennt, welcher auch am Anfang von absoluten Pfaden steht.
Beispielsweise lautet der Pfad meiner Maven-Konfigurationsdatei:
- ... unter Windows:
C:\Users\sven\.m2\settings.xml - ... unter Linux:
/home/sven/.m2/settings.xml
Das im aktuellen Betriebssystem verwendete Trennzeichen bekommst Du über die Konstante File.separator oder die Methode FileSystems.getDefault().getSeparator().
Im Normalfall solltest Du das Trennzeichen nicht direkt benötigen. Java stellt Dir die Klassen java.io.File und, ab Java 7, java.nio.file.Path zur Verfügung, um Verzeichnis- und Dateipfade zu konstruieren, ohne das Trennzeichen angeben zu müssen.
An dieser Stelle gehe ich nicht weiter ins Detail. Datei- und Verzeichnisnamen, relative und absolute Pfadangaben, alte API und NIO.2 machen die Thematik recht komplex. Ich werde das Thema daher in einem separaten Artikel behandeln.
Zusammenfassung und Ausblick
In diesem Artikel hast du verschiedene Methoden kennengelernt, um in Java Text- und Binärdateien zu lesen. Außerdem haben wir uns angesehen, was zu beachten ist, wenn deine Software auch auf anderen Betriebssystemen als deinem lauffähig sein soll.
Im zweiten Teil wirst du die entsprechenden Methoden zum Schreiben von Dateien in Java kennenlernen.
Im Anschluss daran werden folgende Themen behandelt:
- Konstruieren von Datei- und Verzeichnispfaden mit den Klassen
File,PathundPaths - Verzeichnis-Operationen, wie z. B. das Einlesen der Dateiliste eines Verzeichnisses
- Kopieren, Verschieben und Löschen von Dateien
- Erstellen von temporären Dateien
- Laden und Schreiben strukturierter Daten mit
DataOutputStreamundDataInputStream
Und zum Abschluss der Serie kommen wir zu fortgeschrittenen Themen:
- Die in Java 1.4 eingeführten NIO-Channels und Buffer, um insbesondere das Arbeiten mit großen Dateien zu beschleunigen
- Memory-mapped I/O für rasend schnellen Dateizugriff ohne Streams
- File Locking, um parallel – also aus mehreren Threads oder Prozessen – konfliktfrei auf dieselben Dateien zuzugreifen
Wenn du informiert werden willst, wenn der zweite Teil veröffentlicht wird, dann klicke hier, um dich für den HappyCoders-Newsletter anzumelden. Und natürlich würde ich mich auch freuen, wenn du den Artikel über einen der Buttons am Ende teilst.