


Bellman-Ford-Algorithmus
(mit Java-Beispiel)
In den ersten zwei Teilen dieser Serie über Shortest-Path-Algorithmen hast du den Dijkstra- und den A*-Algorithmus kennengelernt.
Beide Algorithmen sind nur auf Graphen anwendbar, die keine negativen Kantengewichte haben. Was das bedeutet – und wie der Bellman-Ford-Algorithmus damit umgeht, erfährst du in diesem Artikel.
Folgende Fragen werden geklärt:
- Was bedeutet "negatives Kantengewicht"?
- Wo kommen negative Kantengewichte in der Praxis vor?
- Warum sind Dijkstra und A* bei negativen Kantengewichten nicht anwendbar?
- Wie funktioniert der Bellman-Ford-Algorithmus (Schritt für Schritt an einem Beispiel erklärt)?
- Was ist ein "negativer Zyklus", und wie geht man damit um?
- Wie implementiert man den Bellman-Ford-Algorithmus in Java?
- Wie bestimmt man die Zeitkomplexität des Bellman-Ford-Algorithmus?
Den Quellcode der gesamten Artikelserie über Pathfinding-Algorithmen findest du in diesem GitHub-Repository.
Was ist ein negatives Kantengewicht?
In den vorangegangenen Teilen habe ich beispielhaft gezeigt, wie eine Straßenkarte auf einen gewichteten Graphen abgebildet wird:

In diesem Graphen geben die Gewichte (die Zahlen an den Kanten) an, wie hoch die Kosten für einen bestimmten Pfad sind. Dies kann beispielsweise die Zeit in Minuten sein, die man für das Zurücklegen dieses Weges mit einem bestimmten Fortbewegungsmittel benötigt.
Der Graph ist ein mathematisches Modell, und in der Mathematik können Zahlen auch negativ sein. Steht an einer Kante im Graph eine Zahl kleiner als Null, dann sprechen wir demzufolge von einem negativen Kantengewicht.
Beispiel für negative Kantengewichte
Hier ein Beispiel:

In diesem Beispiel hat der Pfad von E nach B ein negatives Kantengewicht von -3, und der Pfad von C nach F hat ein negatives Kantengewicht von -2.
Dieser Graph unterscheidet sich von den vorherigen nicht nur durch die negativen Kantengewichte, sondern auch durch die Pfeile. Diese geben die Richtungen an, in denen man den Pfaden folgen kann.
Gerichtete Kanten in einem gerichteten Graph
Wir sprechen hier von gerichteten Kanten. Ein Graph, der gerichtete Kanten enthält, ist ein gerichteter Graph.
In einem gerichteten Graphen können wir – im Gegensatz zum ungerichteten Graphen – auch Pfade darstellen, die nur in einer Richtung verlaufen (z. B. von Knoten A nach B oder von Knoten E nach F) – sowie Verbindungen, deren Gewicht je nach Richtung unterschiedlich ist (z. B. zwischen Knoten A und D und zwischen C und F).
Für beides gibt es naheliegende Anwendungsbeispiele:
- Verbindung in nur einer Richtung: Einbahnstraßen.
- Verbindung mit unterschiedlichen Gewichten je Richtung: Straßen, die in einer Richtung zweispurig sind und in der anderen einspurig. Oder Autobahnen, auf der in einer Richtung ein Stau herrscht, auf der anderen aber freie Fahrt.
Aber negative Kantengewichte?
Wo kommen negative Kantengewichte in der Praxis vor?
Ein Graph mit negativen Kantengewichten erscheint auf den ersten Blick wie ein realitätsfernes, mathematisches Modell. Schließlich kann die benötigte Zeit für einen Weg ja nicht negativ sein.
Die Zeit nicht – aber die Kosten!
Stell dir vor, unser Fahrzeug ist ein Elektroauto. In einem Straßennetz mit Steigungen und Gefällen soll eine Route von A nach B gefunden werden, auf dem das Fahrzeug am wenigsten Energie verbraucht.
Auf einem Gefälle kann das E-Auto seine Batterie aufladen. Und die dabei zurückgewonnene Energie können wir durch negative Kantengewichte repräsentieren.
Warum sind Dijkstra und A* bei negativen Kantengewichten nicht anwendbar?
Bei Dijkstras und dem A*-Algorithmus werden die Knoten der Reihe nach abgearbeitet. Wenn ein Knoten abgearbeitet wurde, wird er nicht weiter betrachtet.
Negative Kantengewichte könnten allerdings dazu führen, dass die Gesamtkosten vom Start zu einem bereits abgearbeiteten Knoten reduziert werden. Die reduzierten Gesamtkosten würden ignoriert und eine evtl. kürzere Route nicht gefunden werden.
Des weiteren: Wenn die Gesamtkosten vom Start zu einem bestimmten Knoten höher sind als die einer bereits gefundenen Route zum Ziel, dann betrachten Dijkstra und A* die von diesem Knoten ausgehenden Wege nicht weiter.
Sollte ein solcher Weg ein negatives Kantengewicht haben, wäre es jedoch möglich, dass dieser Weg mit geringeren Gesamtkosten zum Ziel führt (da die Kosten durch das negative Gewicht ja wieder reduziert werden).
Schauen wir uns das am Beispiel von oben an. Es soll die kürzeste Route von A nach F gesucht werden.
Dijkstra würde zunächst folgende zwei (noch unvollständige) Wege finden:
- A→B→C mit Gesamtkosten vom Start von 4+5 = 9
- A→D→E mit Gesamtkosten vom Start von 3+3 = 6

Dijkstra würde als nächstes Knoten E untersuchen (da 6 kleiner ist als 9) und von hier aus einen Weg zu B mit Gesamtkosten von 3+3+(-3) = 3 finden. Dieser Weg ist kürzer als der bisher gefundene (4 via A). Da B bereits abgearbeitet ist, würde diese Änderung wirkungslos sein.
Des weiteren würde Dijkstra einen Weg von E zum Zielknoten F entdecken mit Gesamtkosten von 3+3+2 = 8:

Da bei Knoten C bereits Gesamtkosten in Höhe von 9 aufgelaufen sind, würde Dijkstra die von C ausgehenden Wege nicht weiter prüfen und die Suche beenden.
Was Dijkstra übersehen würde: Durch das negative Gewicht von C nach F würden sich die Gesamtkosten des Weges A→B→C→F auf 4+5+(-2) = 7 reduzieren.
Und die Gesamtkosten des Weges A→D→E→B→C→F liegen sogar noch niedriger bei 3+3+(-3)+5+(-2) = 6.
Dijkstras Algorithmus hätte bei diesem Beispiel also nicht den kürzesten, sondern nur den drittkürzesten Weg gefunden.
Für den A*-Algorithmus gilt ähnliches, wobei es bei der Existenz negativer Kantengewichte ohnehin schwer fallen dürfte eine sinnvolle Heuristik-Funktion zu definieren.
Wie funktioniert der Bellman-Ford-Algorithmus?
Der Bellman-Ford-Algorithmus ähnelt dem von Dijkstra stark. Der Unterschied ist, dass wir bei Bellman-Ford die Knoten nicht priorisieren, sondern dass wir in jeder Iteration allen Kanten des Graphen folgen und die Gesamtkosten vom Start im Kanten-Zielknoten aktualisieren, wenn diese eine Verbesserung gegenüber des aktuellen Zustands darstellen.
Ich erkläre den Algorithmus in den folgenden Abschnitten am oben vorgestellten Graphen Schritt für Schritt.
Vorbereitung – Tabelle der Knoten
Wir beginnen – genau wie bei Dijkstra – mit dem Erstellen einer Tabelle aller Knoten mit dem jeweiligen Vorgänger-Knoten und den Gesamtkosten vom Startknoten. Die Vorgänger-Spalte lassen wir leer, und als Gesamtkosten tragen wir beim Startknoten 0 ein und bei allen anderen Knoten unendlich (∞):
| Knoten | Vorgänger | Gesamtkosten vom Start |
|---|---|---|
| A | – | 0 |
| B | – | ∞ |
| C | – | ∞ |
| D | – | ∞ |
| E | – | ∞ |
| F | – | ∞ |
Im folgenden ist es wichtig die Begriffe Kosten und Gesamtkosten zu differenzieren:
- Kosten bezeichnet die Kosten von einem Knoten zu einem Nachbarknoten.
- Gesamtkosten bezeichnet die Summe aller Teilkosten vom Startknoten über eventuelle Zwischenknoten zu einem bestimmten Knoten.
Bellman-Ford-Algorithmus – Schritt für Schritt
Die folgenden Ausschnitte des Graphen zeigen zu jedem Knoten den jeweiligen Vorgängerknoten (wenn vorhanden) und die Gesamtkosten vom Start mit an. Diese Daten sind in der Regel nicht im Graph enthalten, sondern nur in der zuvor angelegten, separaten Tabelle. Ich zeige sie hier der Übersicht halber mit an.
Wir führen nun n-1 mal (n ist die Anzahl der Knoten) die folgende Iteration durch. Wir haben sechs Knoten, also fünf Iterationen.
Iteration 1 von 5
In jeder Iteration betrachten wir alle Kanten des Graphen. Die Kanten werden mit zwei Kleinbuchstaben in Klammern gekennzeichnet. Die Kante von Knoten A nach B beispielsweise mit (a, b).
Da weder Kanten noch Knoten priorisiert sind, betrachten wir die Kanten in alphabetischer Reihenfolge. Wir beginnen also mit Kante (a, b):
Kante (a, b)
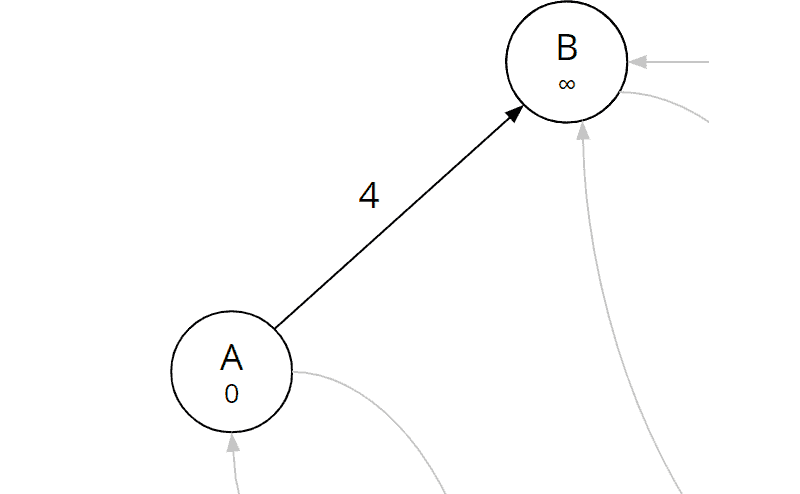
Wir berechnen die Summe aus Gesamtkosten vom Start zu A (diese betragen 0, da A selbst der Startknoten ist) und den Kosten der betrachteten Kante (a, b):
| Kante (a, b) | 0 (Gesamtkosten vom Start zu A) + 4 (Kosten A→B) = 4 |
Die Gesamtkosten für B sind aktuell noch unendlich. Das bedeutet, dass noch keine Route zu B gefunden wurde. Soeben haben wir eine Route entdeckt und tragen daher bei Knoten B als Vorgänger den Knoten A ein und als Gesamtkosten vom Start die eben berechnete Summe 4:

Kante (a, d)
Wir betrachten als nächstes die Kante (a, d):
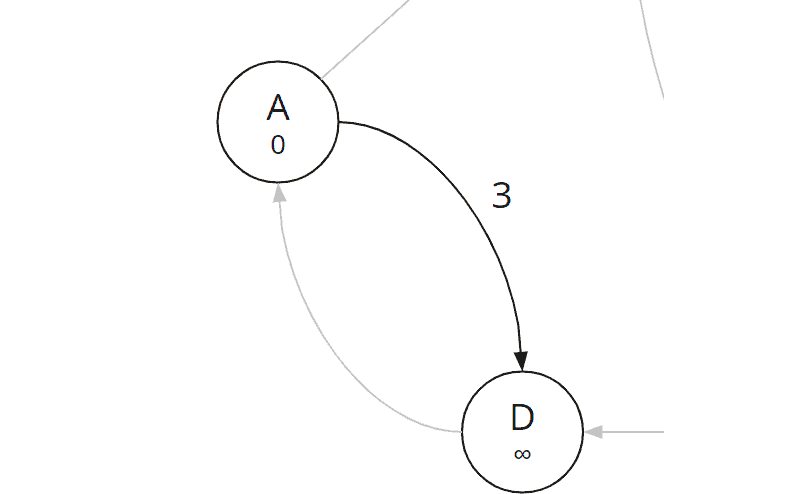
Wir berechnen die Gesamtkosten zu D:
| Kante (a, d) | 0 (Gesamtkosten vom Start zu A) + 3 (Kosten A→D) = 3 |
Da auch die Gesamtkosten bei D noch unendlich sind, tragen wir dort als Gesamtkosten 3 und als Vorgänger A ein:

Von Knoten A führt keine weitere Kante weg. Fahren wir mit den Kanten fort, die von Knoten B aus fortführen.
Kante (b, c)
Wir betrachten Kante (b, c):

Wir berechnen die neue Gesamtkosten für Knoten C:
| Kante (b, c) | 4 (Gesamtkosten vom Start zu B) + 5 (Kosten B→C) = 9 |
Auch C hat noch Gesamtkosten von unendlich; wir tragen als neue Gesamtkosten bei Knoten C eine 9 ein und als Vorgänger Knoten B:

Kante (b, e)
Die nächste Kante in alphabetischer Reihenfolge ist Kante (b, e):

Wir rechnen:
| Kante (b, e) | 4 (Gesamtkosten vom Start zu B) + 4 (Kosten B→E) = 8 |
Und wir aktualisieren Knoten E:

Kante (c, b)
Als nächstes kommen wir zu Kante (c, b). Dass wir die entgegengesetzte Kante (b, c) bereits betrachtet haben, ist an dieser Stelle irrelevant.
Wir sehen natürlich sofort intuitiv, dass es keinen Sinn macht, diesen Weg wieder zurückzulaufen. Damit der Algorithmus dies auch sieht, muss er diesen Pfad dennoch überprüfen. Wir berechnen also die Gesamtkosten für Knoten B, wenn wir diesen über die Kante (c, b) erreichen würden:
| Kante (c, b) | 9 (Gesamtkosten vom Start zu C) + 5 (Kosten C→B) = 14 |
Wir könnten Knoten B von C aus also mit Gesamtkosten von 14 erreichen. Wir haben aber bereits eine Route zu B mit Gesamtkosten von nur 4 gefunden. Den neu gefundenen Weg ignorieren wir daher und fahren stattdessen mit der nächsten Kante fort.
Kante (c, f)
Wir betrachten die erste Kante mit einem negativen Gewicht, Kante (c, f):

Wir berechnen die neuen Gesamtkosten für F:
| Kante (c, f) | 9 (Gesamtkosten vom Start zu C) - 2 (Kosten C→F) = 7 |
Wir aktualisieren Gesamtkosten und Vorgänger in Knoten F:

Wir haben die erste Route zum Ziel gefunden. Da es bei Bellman-Ford keine Priorisierung gibt, könnte dieser Weg der kürzeste sein, der längste, oder irgendeiner dazwischen. Wir müssen daher mit der Abarbeitung der Kanten fortfahren.
Kante (d, a)

Wir berechnen die Gesamtkosten für A über D:
| Kante (d, a) | 3 (Gesamtkosten vom Start zu D) + 4 (Kosten D→A) = 7 |
Die neu berechneten Gesamtkosten (7) sind höher als die bei A bereits hinterlegten (0). Der Weg über D zu A ist also nicht kürzer als der bereits bekannte und wird somit nicht weiter beachtet.
Kante (d, e)

Wir berechnen die Gesamtkosten für E über D:
| Kante (d, e) | 3 (Gesamtkosten vom Start zu D) + 3 (Kosten D→E) = 6 |
Die neu berechneten Gesamtkosten (6) sind niedriger als die bei Knoten E hinterlegten (8). Wir haben also einen kürzeren Weg zu E entdeckt. Wir reduzieren daher die Gesamtkosten in Knoten E von 8 auf 6 und ersetzen Vorgänger B durch D:

Kante (e, b)

Wir berechnen die Gesamtkosten über E zu B:
| Kante (e, b) | 6 (Gesamtkosten vom Start zu E) - 3 (Kosten E→B) = 3 |
Auch hier sind die neu berechneten Gesamtkosten zu B (3) niedriger als die aktuell hinterlegten (4). Wir haben also auch zu B einen kürzeren Weg gefunden. Wir aktualisieren Vorgänger und Gesamtkosten in Knoten B:

Kante (e, f)
Mit der Kante (e, f) betrachten wir die zweite Kante, die zum Zielknoten F führt:

Wir berechnen:
| Kante (e, f) | 6 (Gesamtkosten vom Start zu E) + 2 (Kosten E→F) = 8 |
Wir haben eine weitere Route zum Zielknoten F über Knoten E gefunden. Dieser Weg ist mit Gesamtkosten von 8 jedoch länger als der bisherige (7). Somit ignorieren wir ihn.
Kante (f, c)
Als letztes betrachten wir die Kante (f, c):

Wir berechnen:
| Kante (f, c) | 7 (Gesamtkosten vom Start zu F) + 4 (Kosten F→C) = 11 |
Die neu berechneten Gesamtkosten (11) für Knoten C sind niedriger als die hinterlegten (9). Wir ignorieren also auch diese letzte Kante.
Ende der ersten Iteration
Wir haben nun alle Kanten des Graphen genau einmal betrachtet und eine Route mit Gesamtkosten von 7 zum Ziel gefunden. Mit der Kante (e, b) haben wir allerdings auch die Kosten von Knoten B, dessen ausgehende Kanten wir zuvor schon bearbeitet hatten, noch einmal verringert.
Dies könnte dazu führen, dass wir einen noch kürzeren Weg zum Ziel finden. Wir wiederholen daher die gesamte Iteration.
Der Übersicht halber habe ich während der ersten Iteration die Änderungen von Gesamtkosten und Vorgängern direkt im Graphen notiert. Tatsächlich werden diese Änderungen in die zuvor angelegte Tabelle eingetragen. Diese sieht am Ende der Iteration wie folgt aus:
| Knoten | Vorgänger | Gesamtkosten vom Start |
|---|---|---|
| A | – | 0 |
| B | E | 3 |
| C | B | 9 |
| D | A | 3 |
| E | D | 6 |
| F | C | 7 |
Der Graph sieht aktuell so aus:

Iteration 2 von 5
In der zweiten Iteration betrachten wir erneut alle Kanten des Graphen und führen die gleichen Berechnungen durch wie in der ersten Iteration. Ich werde die Schritte daher etwas weniger detailreich beschreiben.
Kanten (a, b) und (a, d)
| Kante (a, b) | 0 (Gesamtkosten vom Start zu A) + 4 (Kosten A→B) = 4 |
| Kante (a, d) | 0 (Gesamtkosten vom Start zu A) + 3 (Kosten A→D) = 3 |
Da sich in der vorangegangenen Iteration die Gesamtkosten von Knoten A nicht geändert haben, sind die Berechnungen für die von Knoten A wegführenden Kanten gleich geblieben. Es ergeben sich keine niedrigeren Gesamtkosten für die Knoten B und D.
Kante (b, c)
Knoten B ist derjenige, dessen Gesamtkosten wir in der ersten Iteration von 4 auf 3 reduziert haben, nachdem wir alle von ihm ausgehenden Kanten bereits betrachtet hatten. Daher schauen wir uns diese Kante noch einmal detailliert an:

Wir berechnen:
| Kante (b, c) | 3 (Gesamtkosten vom Start zu B) + 5 (Kosten B→C) = 8 |
Die neu berechneten Gesamtkosten (8) sind niedriger als die hinterlegten (9). Das war zu erwarten, da wir ja die Gesamtkosten von B um 1 reduziert haben, nachdem wir die Gesamtkosten von C über B schon berechnet hatten.
Wir aktualisieren die Gesamtkosten in Knoten C; der Vorgänger bleibt unverändert:

Kanten (b, e) und (c, b)
Die nächsten zwei Kanten können wir wieder im Schnellverfahren abhandeln:
| Kante (b, e) | 3 (Gesamtkosten vom Start zu B) + 4 (Kosten B→E) = 7 |
| Kante (c, b) | 8 (Gesamtkosten vom Start zu C) + 5 (Kosten C→B) = 13 |
In beiden Fällen ergeben sich für den Kanten-Endknoten höhere Gesamtkosten als aktuell hinterlegt sind (6 bei E und 3 bei B). Wir haben also keine kürzeren Wege gefunden und ignorieren diese zwei Kanten.
Kante (c, f)
Da wir das Gesamtgewicht von Knoten C eben verändet haben, betrachten wir auch diese Kante noch einmal genauer:

Wir berechnen:
| Kante (c, f) | 8 (Gesamtkosten vom Start zu C) - 2 (Kosten C→F) = 6 |
Die Gesamtkosten sind niedriger als die hinterlegten. Wir haben also einen kürzeren Weg gefunden und aktualisieren die Gesamtkosten in Knoten F von 7 auf 6:

Kanten (d, a), (d, e), (e, b), (e, f) und (f, c)
Auch die verbleibenden fünf Kanten können wir schnell erledigen:
| Kante (d, a) | 3 (Gesamtkosten vom Start zu D) + 4 (Kosten D→A) = 7 |
| Kante (d, e) | 3 (Gesamtkosten vom Start zu D) + 3 (Kosten D→E) = 6 |
| Kante (e, b) | 6 (Gesamtkosten vom Start zu E) - 3 (Kosten E→B) = 3 |
| Kante (e, f) | 6 (Gesamtkosten vom Start zu E) + 2 (Kosten E→F) = 8 |
| Kante (f, c) | 6 (Gesamtkosten vom Start zu F) + 4 (Kosten F→C) = 10 |
In allen fünf Fällen sind die neu berechneten Gesamtkosten für den Kanten-Endknoten größer oder gleich den aktuellen Werten. Somit gibt es keine weiteren Änderungen.
Ende der zweiten Iteration
Wir haben nun ein zweites Mal alle Kanten betrachtet. Bei zwei Knoten (C und F) hat dies zur Reduzierung der Gesamtkosten geführt. Und wir haben einen kürzeren Weg zum Ziel gefunden als in der ersten Iteration.
Die Tabelle sieht aktuell so aus:
| Knoten | Vorgänger | Gesamtkosten vom Start |
|---|---|---|
| A | – | 0 |
| B | E | 3 |
| C | B | 8 |
| D | A | 3 |
| E | D | 6 |
| F | C | 6 |
Und noch einmal die Gesamtkosten und Vorgänger im Graphen:

Um zu prüfen, ob wir ein weiteres mal Gesamtkosten reduzieren können, führen wir eine dritte Iteration durch.
Iteration 3 von 5
Ich mache es kurz: Nach der dritten Prüfung aller Kanten wird der Algorithmus keine weiteren Kostenreduktionen festgestellt haben.
In der Originalvariante würde der Algorithmus noch eine vierte und fünfte Iteration durchführen. Doch wenn in einer Iteration keine kürzeren Wege gefunden werden können, dann ändert sich die Ausgangssituation nicht für die Folgeiteration. Demzufolge können auch in der Folgeiteration (und allen weiteren) keine kürzeren Routen mehr gefunden werden.
Eine entsprechend optimierte Variante des Algorithmus wird daher am Ende von Iteration 3 vorzeitig terminieren.
Backtrace zur Bestimmung des vollständigen Weges
Wir können nun aus der Tabelle oder dem Graphen direkt ablesen, dass der kürzeste Weg zu F über Knoten C führt und dass die Gesamtkosten 6 betragen. Doch wie lautet der vollständige Pfad?
Diesen ermitteln wir mit Hilfe des sogenannten "Backtrace": Wir folgen den Knoten – Vorgänger für Vorgänger – vom Ziel zum Start:

Der Vorgänger von F ist C; der Vorgänger von C ist B; der Vorgänger von B lautet E; der Vorgänger von E ist D, und der Vorgänger von D ist der Startknoten A. Der gesamte Pfad lautet also: A→D→E→B→C→F
Kürzeste Wege zu allen Knoten finden
Tatsächlich können wir nicht nur den kürzesten Pfad zum Zielknoten F ablesen, sondern den kürzesten Pfad zu jedem beliebigen Knoten. Im aktuellen Beispiel, in dem der kürzeste Pfad über alle Knoten des Graphen führt, mag das naheliegend sein. Dies gilt jedoch allgemein, da der Algorithmus ja erst dann endet, wenn er im gesamten Graphen keine weitere Kostenreduktion mehr feststellt.
Maximale Anzahl Iterationen
Zu Beginn des Beispiels habe ich erklärt, dass es maximal n-1 Iterationen gibt. Warum ist das so?
Der längstmögliche Pfad durch den Graphen führt genau einmal durch alle n Knoten, enthält also n-1 Kanten. Im Worst Case werden in jeder Iteration die Kanten in genau entgegengesetzter Richtung zur gesuchten Route geprüft. Dies wiederum führt dazu, dass in jeder Iteration die Gesamtkosten nur für eine Kante in Richtung Ziel berechnet werden können. Bei n-1 Kanten sind somit n-1 Iterationen nötig.
Am folgende Beispiel ist das gut zu erkennen. Wir suchen in folgendem Graphen den kürzesten Weg von A nach D:

Iteration 1
Im schlechtesten Fall besuchen wir die Kanten von rechts nach links, wir beginnen also mit der Kante (c, d). Da die Gesamtkosten von Knoten C noch unendlich sind (s. vorheriges Bild), ignorieren wir diese Kante. Gleiches gilt für die Kante (b, c). Erst bei der Kante (a, b) können wir die Gesamtkosten für B berechnen (0+2 = 2) und aktualisieren:

Iteration 2
Wieder beginnen wir bei Kante (c, d). Die Gesamtkosten für Knoten C sind nach wie vor nicht berechnet (s. vorheriges Bild), also ignorieren wir die Kante auch in dieser Iteration. Die Gesamtkosten für Knoten B sind berechnet, daher können wir anhand der Kante (b, c) jetzt die Gesamtkosten für Knoten C berechnen (2+3 = 5):

Iteration 3
Nachdem wir in der zweiten Iteration die Gesamtkosten für Knoten C berechnet haben, können wir schließlich anhand der Kante (c, d) auch die Gesamtkosten für Knoten D berechnen (5+2 = 7):

Für vier Knoten (n = 4) haben wir also drei (n - 1) Iterationen benötigt.
Identifizierung negativer Zyklen in gerichteten Graphen
Ein Problem, mit dem wir im gezeigten Beispiel nicht konfrontiert wurden, ist das Vorhandensein negativer Zyklen im Graph. Dieser Abschnitt beschreibt, was ein negativer Zyklus ist, warum dieser eine Herausforderung darstellt und wie der Bellman-Ford-Algorithmus diese löst.
Was ist ein negativer Zyklus?
In einem negativen Zyklus kann man von einem Knoten aus denselben Knoten wieder erreichen über einen Pfad mit negativen Gesamtkosten. Z. B. in folgendem Graph:

In diesem Beispiel hat der zyklische Pfad B→C→D→B Gesamtkosten von 1+2+(-4) = -1
Warum ist ein negativer Zyklus problematisch?
Wir können den negativen Zyklus beliebig oft traversieren. Mit jeder Runde reduzieren wir die Gesamtkosten auf allen beteiligten Knoten weiter.
Nehmen wir an, wir suchen im Beispiel oben den Pfad mit den geringsten Gesamtkosten von A nach E. Der naheliegende Weg wäre A→B→C→D→E mit Gesamtkosten von 5+1+2+3 = 11.
Wir könnten von Knoten D aber auch zurück zu B gehen und folgenden Weg zurücklegen: A→B→C→D→B→C→D→E. Die Gesamtkosten dieses Weges belaufen sich auf 5+1+2+(-4)+1+2+3 = 10. Durch einmaliges Durchlaufen des negativen Zyklus haben wir die Gesamtkosten um 1 reduziert.
Wenn wir dem negativen Zyklus 11 mal durchlaufen, liegen die Gesamtkosten bei 0. Das ist aber nicht das Ende der Fahnenstange. Wir können dem negativen Zyklus auch 1.000 mal folgen und die Gesamtkosten auf -989 reduzieren. Oder 1.000.000 mal... es gibt unendlich viele Möglichkeiten: mit jedem weiteren Durchlauf des negativen Zyklus reduzieren wir die Gesamtkosten weiter.
Der Algorithmus würde also nie enden. Oder er würde, wenn wir ihn nach einer bestimmten Anzahl Iterationen abbrechen, nicht den kürzesten Pfad liefern.
Wie wird ein negativer Zyklus identifiziert?
Im Abschnitt "Maximale Anzahl Iterationen" habe ich gezeigt, dass Bellman-Ford maximal n-1 Iterationen durchlaufen muss (n ist die Anzahl der Knoten), um den kürzesten Weg zu finden.
Der Algorithmus führt nun eine weitere Iteration durch, in der er prüft, ob sich an einem beliebigen Knoten noch einmal die Gesamtkosten reduzieren würden. Sollte das der Fall sein, ist die Schlussfolgerung, dass es im Graphen einen negativen Zyklus geben muss.
Der Algorithnmus endet dann mit einer entsprechenden Fehlermeldung.
Bellman-Ford-Algorithmus – Informelle Beschreibung
Vorbereitung:
- Erstelle eine Tabelle aller Knoten mit Vorgängerknoten und Gesamtkosten vom Start.
- Setze die Gesamtkosten des Startknotens auf 0 und die aller anderer Knoten auf unendlich.
Führe folgendes n-1 mal aus (n ist die Anzahl der Knoten):
- Für jede Kante des Graphen:
- Berechne die Summe aus Gesamtkosten zum Kanten-Startknoten und Kantengewicht.
- Ist diese Summe niedriger als die aktuellen Gesamtkosten des Kanten-Endknotens, dann setze den Vorgänger des Endknotens auf den Kanten-Startknoten und die Gesamtkosten des Endknotens auf die eben berechnete Summe.
- Wurden in dieser Iteration keine Änderungen durchgeführt, beende den Algorithmus vorzeitig (in der optimierten Version des Algorithmus).
Wenn der Algorithmus nicht vorzeitig beendet wurde, prüfe auf negative Zyklen:
- Für jede Kante des Graphen:
- Berechne die Summe aus Gesamtkosten zum Kanten-Startknoten und Kantengewicht.
- Ist diese Summe niedriger als die aktuellen Gesamtkosten des Kanten-Endknotens, dann beende den Algorithmus mit der Meldung, dass ein negativer Zyklus entdeckt wurde.
Bellman-Ford-Algorithmus in Java
Dieser Abschnitt zeigt dir Schritt für Schritt, wie man den Bellman-Ford-Algorithmus in Java implementiert. Den vollständigen Quellcode findest du in diesem GitHub-Repository, im Paket eu.happycoders.pathfinding.bellman_ford.
Datenstruktur für den Graph: Guava ValueGraph
Zunächst benötigen wir eine Datenstruktur für den Graph. Diese brauchen wir nicht selbst zu schreiben. Stattdessen verwenden wir den ValueGraph aus den Google Core Libraries for Java, genauer gesagt den MutableValueGraph. (Die verschiedenen Graph-Klassen werden hier erläutert.)
Der folgende Code zeigt, wie man den gerichteten Graphen aus dem Artikelbeispiel erstellt (du findest die Methode am Ende der Klasse TestWithSampleGraph im GitHub-Repository):
private static ValueGraph<String, Integer> createSampleGraph() {
MutableValueGraph<String, Integer> graph = ValueGraphBuilder.directed().build();
graph.putEdgeValue("A", "B", 4);
graph.putEdgeValue("A", "D", 3);
graph.putEdgeValue("B", "C", 5);
graph.putEdgeValue("B", "E", 4);
graph.putEdgeValue("C", "B", 5);
graph.putEdgeValue("C", "F", -2);
graph.putEdgeValue("D", "A", 4);
graph.putEdgeValue("D", "E", 3);
graph.putEdgeValue("E", "B", -3);
graph.putEdgeValue("E", "D", 3);
graph.putEdgeValue("E", "F", 2);
graph.putEdgeValue("F", "C", 4);
return graph;
}Code-Sprache: Java (java)Die Typparameter des ValueGraph sind:
- Typ der Knoten: im Beispielcode
Stringfür die Knotennamen "A" bis "F" - Typ der Kantenwerte: im Beispielcode
Integerfür die Kosten der Kanten
Da der Graph gerichtet ist, ist es wichtig, in welcher Reihenfolge die Knoten jeweils angegeben werden. Für Kanten, die in beiden Richtungen existieren (z. B. zwischen den Knoten B und C) muss dementsprechend auch zweimal putEdgeValue() aufgerufen werden.
Datenstruktur für die Knoten: NodeWrapper
Als nächstes benötigen wir eine Datenstruktur, die für jeden Knoten dessen Gesamtkosten vom Start sowie dessen Vorgängerknoten speichert. Diese Aufgabe erledigt die Klasse NodeWrapper:
class NodeWrapper<N> {
private final N node;
private int totalCostFromStart;
private NodeWrapper<N> predecessor;
NodeWrapper(N node, int totalCostFromStart, NodeWrapper<N> predecessor) {
this.node = node;
this.totalCostFromStart = totalCostFromStart;
this.predecessor = predecessor;
}
// getter for node
// getters and setters for totalCostFromStart and predecessor
// equals() and hashCode()
}Code-Sprache: Java (java)Der Typparameter <N> steht für den Knotentyp und ist in unserem Beispiel String für die Knotennamen.
Vorbereitung: Füllen der Tabelle
Der Algorithmus selbst wird in der Methode findShortestPath(ValueGraph<N, Integer> graph, N source, N target) der Klasse BellmanFord implementiert.
Als Datenstruktur für die Tabelle verwenden wir eine HashMap. Wir iterieren über alle Knoten des Graphen, verpacken jeden Knoten in einen NodeWrapper und setzen die Gesamtkosten des Startknotens auf 0 und die aller anderen Knoten auf Integer.MAX_VALUE:
Map<N, NodeWrapper<N>> nodeWrappers = new HashMap<>();
for (N node : graph.nodes()) {
int initialCostFromStart = node.equals(source) ? 0 : Integer.MAX_VALUE;
NodeWrapper<N> nodeWrapper = new NodeWrapper<>(node, initialCostFromStart, null);
nodeWrappers.put(node, nodeWrapper);
}Code-Sprache: Java (java)Iterationen
Die Logik in den ersten n-1 Iterationen und die Logik zum Auffinden von negativen Zyklen sind größtenteils gleich. Daher fasse ich beides in eine Schleife zusammen, die nicht n-1 mal ausgeführt wird, sondern n mal:
// Iterate n-1 times + 1 time for the negative cycle detection
int n = graph.nodes().size();
for (int i = 0; i < n; i++) {
// Last iteration for detecting negative cycles?
boolean lastIteration = i == n - 1;
boolean atLeastOneChange = false;
// For all edges...
for (EndpointPair<N> edge : graph.edges()) {
NodeWrapper<N> edgeSourceWrapper = nodeWrappers.get(edge.source());
int totalCostToEdgeSource = edgeSourceWrapper.getTotalCostFromStart();
// Ignore edge if no path to edge source was found so far
if (totalCostToEdgeSource == Integer.MAX_VALUE) continue;
// Calculate total cost from start via edge source to edge target
int cost = graph.edgeValue(edge).orElseThrow(IllegalStateException::new);
int totalCostToEdgeTarget = totalCostToEdgeSource + cost;
// Cheaper path found?
// a) regular iteration --> Update total cost and predecessor
// b) negative cycle detection --> throw exception
NodeWrapper edgeTargetWrapper = nodeWrappers.get(edge.target());
if (totalCostToEdgeTarget < edgeTargetWrapper.getTotalCostFromStart()) {
if (lastIteration) {
throw new IllegalArgumentException("Negative cycle detected");
}
edgeTargetWrapper.setTotalCostFromStart(totalCostToEdgeTarget);
edgeTargetWrapper.setPredecessor(edgeSourceWrapper);
atLeastOneChange = true;
}
}
// Optimization: terminate if nothing was changed
if (!atLeastOneChange) break;
}Code-Sprache: Java (java)Zu Beginn der Schleife prüfen wir, ob wir in der letzten Iteration sind.
Dann iterieren wir über alle Kanten des Graphen und berechnen die über die jeweilige Kante erreichten Gesamtkosten für den Kanten-Endknoten. Sollten diese geringer sein als die bisher gespeicherten, dann aktualisieren wir den Endknoten bzw. – wenn wir in der letzten Iteration sind – werfen wir eine Exception aufgrund des erkannten negativen Zyklus.
Zuletzt prüfen wir, ob ein Weg zum Ziel gefunden wurde. Wenn ja, rufen wir die Backtrace-Funktion buildPath() auf und geben deren Ergebnis zurück – andernfalls ist der Rückgabewert null:
// Path found?
NodeWrapper<N> targetNodeWrapper = nodeWrappers.get(target);
if (targetNodeWrapper.getPredecessor() != null) {
return buildPath(targetNodeWrapper);
} else {
return null;
}Code-Sprache: Java (java)Die vollständige findShortestPath()-Methode findest du in der Klasse BellmanFord im GitHub-Repository.
Backtrace-Methode in Java
Die Backtrace-Methode buildPath() folgt den Knoten Vorgänger für Vorgänger und trägt diese dabei in eine Liste ein. Schließlich wird die Liste in umgekehrter Reihenfolge zurückgegeben:
private static <N> List<N> buildPath(NodeWrapper<N> nodeWrapper) {
List<N> path = new ArrayList<>();
while (nodeWrapper != null) {
path.add(nodeWrapper.getNode());
nodeWrapper = nodeWrapper.getPredecessor();
}
Collections.reverse(path);
return path;
}Code-Sprache: Java (java)Aufruf der findShortestPath()-Methode
Den Aufruf der findShortestPath()-Methode findest du in zwei Beispielen:
- TestWithSampleGraph: Dieser Test erstellt den Beispiel-Graphen dieses Artikels und sucht darin die kürzeste Route von A nach F.
- TestWithNegativeCycle: Dieser Test erstellt den Beispiel-Graphen aus dem Abschnitt über negative Zyklen und sucht darin den kürzesten Weg von A nach E.
Kommen wir nun zu einem eher theoretischen Thema: der Zeitkomplexität von Bellman-Ford.
Zeitkomplexität des Bellman-Ford-Algorithmus
Zeitkomplexität der nicht optimierten Variante
Die Zeitkomplexität des nicht optimierten Bellman-Ford-Algorithmus ist sehr einfach zu bestimmen.
Aus dem Abschnitt "Maximale Anzahl Iterationen" wissen wir bereits, dass der Algorithmus n-1 Iterationen durchläuft, wobei n die Anzahl der Knoten ist. In einer weiteren Iteration wird geprüft, ob es negative Zyklen gibt.
In jeder Iteration werden alle Kanten des Graphen betrachtet. Wir bezeichnen die Anzahl der Kanten mit m.
Der Aufwand für das Behandeln einer Kante ist konstant:
- Wir führen eine Addition durch und einen Vergleich.
- Ggf. ändern wir Vorgänger und Gesamtkosten des Kanten-Endknotens.
- Bei Verwendung einer geeigneten Datenstruktur (z. B. einer
HashMap) ist das Auffinden des Knoten-Datensatzes in der Tabelle ebenfalls konstant*.
Es ergibt sich eine Gesamt-Zeitkomplexität von:
O(n · m)
Für den Sonderfall, dass die Anzahl der Kanten ein Vielfaches der Anzahl der Knoten ist – in Landau-Notation: m ∈ O(n) – können wir m und n bei der Berechnung der Zeitkomplexität gleichsetzen.
Aus der Formel wird dann:
O(n²) für m ∈ O(n)
Der Aufwand ist also quadratisch.
* Das ist vereinfacht ausgedrückt und gilt bei ausreichender Kapazität der HashMap und bei Verwendung einer geeigneten Hash-Funktion. Im Worst Case würde sich der Aufwand für das Auffinden eines Datensatzes auf O(log n) verschlechtern (binäre Suche innerhalb der Buckets). Bei Millionen von Knoten wäre daher abzuwägen, ob man Gesamtkosten und Vorgänger direkt in den Knoten hinterlegt anstatt in einer separaten Datenstruktur.
Zeitkomplexität der optimierten Variante
In der optimierten Variante müssen wir best, worst und average case separat betrachten.
Zeitkomplexität der optimierten Variante – Worst Case
Bei einem Fall wie im Abschnitt "Maximale Anzahl Iterationen" beschrieben kommt die Optimierung nicht zum Tragen, da in jeder Iteration Änderungen erfolgen. Die Zeitkomplexität entspricht somit der des nicht optimierten Algorithmus:
O(n · m)
bzw. O(n²) für m ∈ O(n)
Zeitkomplexität der optimierten Variante – Best Case
Im Best Case werden nur in der ersten Iteration Änderungen durchgeführt. Die Anzahl der Knoten ist damit für die Zeitkomplexität irrelevant, und der Aufwand wächst linear mit der Anzahl der Kanten:
O(m)
Zeitkomplexität der optimierten Variante – Average Case
Im durchschnittlichen Fall reduziert sich die Anzahl der Änderungen mit jeder Iteration rasch, so dass der Algorithmus nach nur wenigen Iterationen endet. Die Reduktion erfolgt um einen relativ konstanten Faktor, so dass die Anzahl der Iterationen im Average Case in der Größenordnung O(log n) liegt. Einen formalen Beweis dafür konnte ich in der Literatur nicht finden, die Experimente im folgenden Kapitel werden es aber bestätigen.
Die Zeitkomplexität des gesamten Algorithmus wird damit zu:
O(log n · m)
bzw. O(n · log n) für m ∈ O(n)
Im durchschnittlichen Fall haben wir also quasilinearen Aufwand.
Laufzeit des Bellman-Ford-Algorithmus
Mit dem Tool TestBellmanFordRuntime können wir prüfen, ob die theoretisch hergeleitete Zeitkomplexität mit der Praxis übereinstimmt. Das Programm erstellt Zufallsgraphen verschiedener Größen und sucht darin den kürzesten Weg zwischen zwei zufällig ausgewählten Knoten.
Die Optimierung des Algorithmus können wir für den Test abschalten, indem wir in der Klasse BellmanFord Zeile 69 auskommentieren.
Das Tool wiederholt jeden Test 50 mal und gibt anschließend den Median der Messwerte aus. Die folgenden zwei Grafiken zeigen die Messwerte im Verhältnis zur Anzahl der Knoten mit und ohne Optimierung. Da die Messwerte sehr weit auseinanderliegen, habe ich in der ersten Grafik den Fokus auf den Standard-Algorithmus gelegt, in der zweiten Grafik auf den optimierten.


Sowohl das quadratische Wachstum ohne Optimierung als auch das quasilineare Wachstum mit Optimierung sind gut zu erkennen. Dies entspricht den hergeleiteten Zeitkomplexitäten O(n²) für den ursprünglichen Algorithmus und O(n · log n) in der optimierten Variante – jeweils für m ∈ O(n).
Bellman-Ford vs. Dijkstra
Die folgende Grafik zeigt die Messungen für Bellman-Ford und Dijkstra gegenübergestellt (die für Dijkstra haben ich mit dem Tool TestDijkstraRuntime ermittelt):

Es ist gut zu sehen, dass der nicht optimierte Bellman-Ford-Algorithmus um Größenordnungen langsamer ist als Dijkstras Algorithmus. Auch der optimierte Bellman-Ford-Algorithmus braucht rund zehnmal länger als Dijkstra (mit Fibonacci Heap).
Sofern wir keine negativen Kantengewichte in unserem Graphen haben, sollten wir also immer Dijkstra oder A* (sofern sich eine Heuristik definieren lässt) vorziehen.
Zusammenfassung und Ausblick
In diesem Artikel hast du gelernt (oder aufgefrischt), was negative Kantengewichte sind, wie der Bellman-Ford-Algorithmus den kürzesten Weg in einem gerichteten Graphen mit negativen Kantengewichten findet und wie er negative Zyklen identifiziert.
Die Zeitkomplexität der ursprünglichen Variante – sowie die Worst-Case-Zeitkomplexität der optimierten Variante – ist mit O(n · m) bzw. O(n²) für m ∈ O(n) deutlich schlechter als die von Dijkstra und A*. Dort liegt die Zeitkomplexität beim Einsatz eines Fibonacci-Heaps bei O(n · log n + m) bzw. O(n · log n) für m ∈ O(n).
Im average case schafft die optimierte Variante ebenfalls quasilinearen Aufwand, ist im Experiment aber dennoch etwa zehnmal langsamer als Dijkstra. Bellman-Ford sollte daher nur dann eingesetzt werden, wenn der Graph negative Kantengewichte enthält.
Vorschau: Floyd-Warshall-Algorithmus
Im nächsten und abschließenden Artikel der Pathfinding-Serie stelle ich den Floyd-Warshall-Algorithmus vor. Dieser wird benutzt, um die kürzesten Routen zwischen allen Knotenpaaren eines Graphen zu finden (Floyds Variante) – oder, um festzustellen, zwischen welchen Knotenpaaren es überhaupt Routen gibt (Warshalls Variante).