


Binary Tree
(+ Java Code Examples)
Two of the most important topics in computer science are sorting and searching data sets. A data structure often used for both is the binary tree and its concrete implementations binary search tree and binary heap.
In this article, you will learn:
- What is a binary tree?
- What types of binary trees exist?
- How to implement a binary tree in Java?
- What operations do binary trees provide?
- What are pre-order, in-order, post-order, and level-order traversal in binary trees?
You can find the source code for the article in this GitHub repository.
Binary Tree Definition
A binary tree is a tree data structure in which each node has at most two child nodes. The child nodes are called left child and right child.
Binary Tree Example
As an example, a binary tree looks like this:
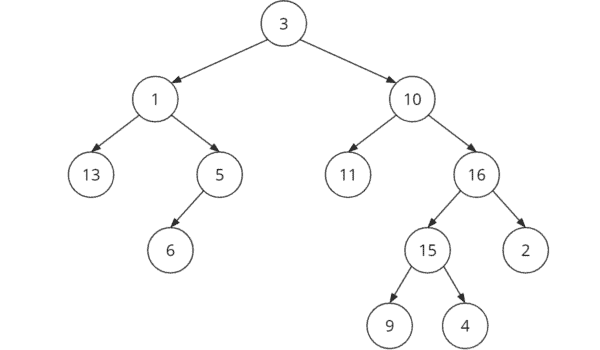
Binary Tree Terminology
As a developer, you should know the following terms:
- A node is a structure that contains data and optional references to a left and a right child node (or just child).
- The connection between two nodes is called an edge.
- The top node is called the root or root node.
- A node that has children is an inner node (short: inode) and, at the same time, the parent node of its child(ren).
- A node without children is called an outer node or leaf node, or just a leaf.
- A node with only one child is a half node. Attention: this term exists – in contrast to all others – only for binary trees, not for trees in general.
- The number of child nodes is also called the degree of a node.
- The depth of a node indicates how many levels the node is away from the root. Therefore, the root has a depth of 0, the root's children have a depth of 1, and so on.
- The height of a binary tree is the maximum depth of all its nodes.
The following image shows the same binary tree data structure as before, labeled with node types, node depth, and binary tree height.

Binary Trees Properties
Before we get to the implementation of binary trees and their operations, let's first briefly look at some special binary tree types.
Full Binary Tree
In a full binary tree, all nodes have either no children or two children.

Complete Binary Tree
In a complete binary tree, all levels, except possibly the last one, are completely filled. If the last level is not completely filled, then its nodes are arranged as far to the left as possible.

Perfect Binary Tree
A perfect binary tree is a full binary tree in which all leaves have the same depth.

A perfect binary tree of height h has n = 2h+1-1 nodes and l = 2h leaves.
At the height of 3, that's 15 nodes, 8 of which are leaves.
Balanced Binary Tree
In a balanced binary tree, each node's left and right subtrees differ in height by at most one.

Sorted Binary Tree
In a sorted binary tree (also known as ordered binary tree), the left subtree of a node contains only values less than (or equal to) the value of the parent node, and the right subtree contains only values greater than (or equal to) the value of the parent node. Such a data structure is also called a binary search tree.
Binary Tree in Java
For the binary tree implementation in Java, we first define the data structure for the nodes (class Node in the GitHub repository). For simplicity, we use int primitives as node data. We can, of course, use any other or a generic data type; however, with an int, the code is more readable – and that is most important for this tutorial.
public class Node {
int data;
Node left;
Node right;
Node parent;
public Node(int data) {
this.data = data;
}
}Code language: Java (java)The parent reference is not mandatory for storing and displaying the tree. However, it is helpful – at least for certain types of binary trees – when deleting nodes.
The binary tree itself initially consists only of the interface BinaryTree and its minimal implementation BaseBinaryTree, which initially contains only a reference to the root node:
public interface BinaryTree {
Node getRoot();
}
public class BaseBinaryTree implements BinaryTree {
Node root;
@Override
public Node getRoot() {
return root;
}
}Code language: Java (java)Why we bother to define an interface here will become apparent in the further course of the tutorial.
The binary tree data structure is thus fully defined.
Binary Tree Traversal
An essential operation on binary trees is the traversal of all nodes, i.e., visiting all nodes in a particular order. The most common types of traversal are:
- Depth-first search (pre-order, post-order, in-order, reverse in-order traversal)
- Breadth-first search (level-order traversal)
In the following sections, you will see the different types illustrated by the following example:

We implement the visiting during traversal using the visitor design pattern, i.e., we create a visitor object which we pass to the traversal method.
Depth-First Search in a Binary Tree
In depth-first search (DFS), we perform the following three operations in a specific order:
- visiting the current node (from now on referred to as "N),
- the depth-first search is invoked recursively on the left child (referred to as "L"),
- the depth-first search is invoked recursively on the right child (referred to as "R").
The standard sequences are:
Binary Tree Pre-Order Traversal
In pre-order traversal (also known as NLR), traversing is performed in the following order:
- visiting the current node "N",
- recursive invocation of depth-first search on left subtree "L",
- recursive invocation of depth-first search on right subtree "R".
The nodes of the example tree are visited in the following order, as shown in the diagram below: 3→1→13→10→11→16→15→2
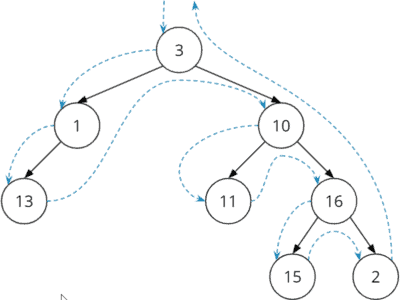
The code for this is fairly simple (DepthFirstTraversalRecursive class, starting at line 21):
private void traversePreOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
visitor.visit(node);
traversePreOrder(node.left, visitor);
traversePreOrder(node.right, visitor);
}Code language: Java (java)You can either invoke the method directly – in which case you must pass the the root node to it – or via the non-static method traversePreOrder() in the same class (DepthFirstTraversalRecursive, starting at line 17):
public void traversePreOrder(NodeVisitor visitor) {
traversePreOrder(tree.getRoot(), visitor);
}Code language: Java (java)This requires creating an instance of DepthFirstTraversalRecursive, passing a reference to the binary tree to the constructor:
new DepthFirstTraversalRecursive(tree).traversePreOrder(visitor);Code language: Java (java)An iterative implementation is also possible using a stack (class DepthFirstTraversalIterative from line 20). The iterative implementations are pretty complex, which is why I do not print them here.
You can read why I use ArrayDeque instead of Stack in iterative tree traversals here: Why You Should Not Use Stack (Anymore).
Binary Tree Post-Order Traversal
In post-order traversal (also known as LRN), traversing is performed in the following order:
- recursive invocation of depth-first search on left subtree "L",
- recursive invocation of depth-first search on right subtree "R",
- visiting the current node "N".
In this case, the nodes of the example tree are visited in the following order: 13→1→11→15→2→16→10→3

You can find the code in DepthFirstTraversalRecursive starting at line 42:
public static void traversePostOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traversePostOrder(node.left, visitor);
traversePostOrder(node.right, visitor);
visitor.visit(node);
}Code language: Java (java)You can find the iterative implementation, which is even more complicated for post-order traversal than for pre-order traversal, in DepthFirstTraversalIterative starting at line 44.
Binary Tree In-Order Traversal
In-order traversal (also known as LNR) traverses the tree in the following order:
- recursive invocation of depth-first search on left subtree "L",
- visiting the current node "N",
- recursive invocation of depth-first search on right subtree "R".
The nodes of the example tree are visited in the following order: 13→1→3→11→10→15→16→2

You will find the recursive code in DepthFirstTraversalRecursive starting at line 62:
public static void traverseInOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traverseInOrder(node.left, visitor);
visitor.visit(node);
traverseInOrder(node.right, visitor);
}Code language: Java (java)See DepthFirstTraversalIterative starting at line 69 for the iterative implementation of in-order traversal.
In a binary search tree, in-order traversal visits the nodes in the order in which they are sorted.
Binary Tree Reverse In-Order Traversal
Reverse in-order traversal (also known as RNL) traverses the tree in the following reverse order:
- recursive invocation of depth-first search on right subtree "R",
- visiting the current node "N",
- recursive invocation of depth-first search on left subtree "L".
The nodes of the sample tree are visited in reverse order to the in-order traversal: 2→16→15→10→11→3→1→13

You will find the recursive code in DepthFirstTraversalRecursive starting at line 83:
public static void traverseReverseInOrder(Node node, NodeVisitor visitor) {
if (node == null) {
return;
}
traverseReverseInOrder(node.right, visitor);
visitor.visit(node);
traverseReverseInOrder(node.left, visitor);
}Code language: Java (java)You can find the iterative implementation of reverse in-order traversal in DepthFirstTraversalIterative starting at line 89.
In a binary search tree, reverse in-order traversal visits the nodes in descending sort order.
Binary Tree Level-Order Traversal
In breadth-first search (BFS) – also called level-order traversal – nodes are visited starting from the root, level by level, from left to right.
Level-order traversal results in the following sequence: 3→1→10→13→11→16→15→2

To visit the nodes in level-order, we need a queue in which we first insert the root node and then repeatedly remove the first element, visit it, and add its children to the queue – until the queue is empty again.
You can find the code in the BreadthFirstTraversal class:
public static void traverseLevelOrder(Node root, NodeVisitor visitor) {
if (root == null) {
return;
}
Queue<Node> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
Node node = queue.poll();
visitor.visit(node);
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}Code language: Java (java)You can find examples for invoking all traversal types in the traverseTreeInVariousWays() method of the Example1 class.
Binary Tree Operations
Besides traversal, other basic operations on binary trees are the insertion and deletion of nodes.
Search operations are provided by special binary trees such as the binary search tree. Without special properties, we can search a binary tree only by traversing over all nodes and comparing each with the searched element.
Insertion of a Node
When inserting new nodes into a binary tree, we have to distinguish different cases:
Case A: Inserting a Node Below a (Half) Leaf
Es ist leicht einen neuen Knoten an ein Blatt oder ein Halbblatt anzuhängen. Hierzu müssen wir lediglich die left- oder right-Referenz des Parent-Knotens P, an den wir den neuen Knoten N anhängen wollen, auf den neuen Knoten setzen. Wenn wir auch mit parent-Referenzen arbeiten, müssen wir diese im neuen Knoten N auf den Parent-Knoten P setzen.
It is easy to append a new node to a leaf or half leaf. To do this, we just need to set the left or right reference of the parent node P, to which we want to append the new node N, to the new node. If we are working with a parent reference, we need to set the new node's parent reference to P.


Case B: Inserting a Node Between Inner Node and Its Child
But how do you go about inserting a node between an inner node and one of its children?

This is only possible by reorganizing the tree. How exactly the tree is reorganized depends on the concrete type of binary tree.
In this tutorial, we implement a very simple binary tree and proceed as follows for the reorganization:
- If the new node N is to be inserted as a left child below the inner node P, then P's current left subtree L is set as a left child below the new node N. Accordingly, the parent of L is set to N, and the parent of N is set to P.
- If the new node N is to be inserted as a right child below the inner node P, then P's current right subtree R is set as a right child below the new node N. Accordingly, the parent of R is set to N, and the parent of N is set to P.
The following diagram shows the second case: We insert the new node N between P and R:

This is – as mentioned – a very simple implementation. In the example above, this results in a highly unbalanced binary tree.
Specific binary trees take a different approach here to maintain a tree structure that satisfies the particular properties of the binary tree in question (sorting, balancing, etc.).
Inserting a Binary Tree Node – Java Source Code
Here you can see the code for inserting a new node with the given data below the given parent node to the specified side (left or right) using the reorganization strategy defined in the previous section (class SimpleBinaryTree starting at line 18).
(The switch expression with the curly braces was introduced in Java 12/13.)
public Node insertNode(int data, Node parent, Side side) {
var node = new Node(data);
node.parent = parent;
switch (side) {
case LEFT -> {
if (parent.left != null) {
node.left = parent.left;
node.left.parent = node;
}
parent.left = node;
}
case RIGHT -> {
if (parent.right != null) {
node.right = parent.right;
node.right.parent = node;
}
parent.right = node;
}
default -> throw new IllegalStateException();
}
return node;
}Code language: Java (java)In the createSampleTree() method of the Example1 class, you can see how to create the sample binary tree from the beginning of this article.
Deletion of a Node
Also, when deleting a node, we have to distinguish different cases.
Case A: Deleting a Node Without Children (Leaf)
If the node N to be deleted is a leaf, i.e., has no children itself, then the node is simply removed. To do this, we check whether the node is the left or right child of the parent P and set P's left or right reference to null accordingly.

Case B: Deleting a Node With One Child (Half Leaf)
If the node N to be deleted has a child C itself, then the child moves up to the deleted position. Again, we check whether node N is the left or right child of its parent P. Then, accordingly, we set the left or right reference of P to N's child C (the previous grandchild) – and C's parent reference to N's parent P (the previous grandparent node).

Case C: Deleting a Node With Two Children
How to proceed if you want to delete a node with two children?

This requires a reorganization of the binary tree. Analogous to insertion, there are again different strategies for deletion – depending on the concrete type of binary tree. In a heap, for example, the last node of the tree is placed at the position of the deleted node and then the heap is repaired.
We use the following easy-to-implement variant for our tutorial:
- We replace the deleted node N with its left subtree L.
- We append the right subtree R to the rightmost node of the left subtree.

We can see clearly how this strategy leads to a severely unbalanced binary tree. Specific implementations like the binary search tree and the binary heap, therefore, have more complex strategies.
Deleting a Tree Node – Java Source Code
The following method (class SimpleBinaryTree starting at line 71) removes the passed node from the tree. Corresponding comments mark cases A, B, and C.
public void deleteNode(Node node) {
if (node.parent == null && node != root) {
throw new IllegalStateException("Node has no parent and is not root");
}
// Case A: Node has no children --> set node to null in parent
if (node.left == null && node.right == null) {
setParentsChild(node, null);
}
// Case B: Node has one child --> replace node by node's child in parent
// Case B1: Node has only left child
else if (node.right == null) {
setParentsChild(node, node.left);
}
// Case B2: Node has only right child
else if (node.left == null) {
setParentsChild(node, node.right);
}
// Case C: Node has two children
else {
removeNodeWithTwoChildren(node);
}
// Remove all references from the deleted node
node.parent = null;
node.left = null;
node.right = null;
}Code language: Java (java)The setParentsChild() method checks whether the node to be deleted is the left or right child of its parent node and replaces the corresponding reference in the parent node with the child node. child is null if the node to be deleted has no children, and accordingly, the child reference in the parent node is set to null.
In case the deleted node is the root node, we simply replace the root reference.
private void setParentsChild(Node node, Node child) {
// Node is root? Has no parent, set root reference instead
if (node == root) {
root = child;
if (child != null) {
child.parent = null;
}
return;
}
// Am I the left or right child of my parent?
if (node.parent.left == node) {
node.parent.left = child;
} else if (node.parent.right == node) {
node.parent.right = child;
} else {
throw new IllegalStateException(
"Node " + node.data + " is neither a left nor a right child of its parent "
+ node.parent.data);
}
if (child != null) {
child.parent = node.parent;
}
}Code language: Java (java)In case C (deleting a node with two children), the tree is reorganized as described in the previous section. This is done in the separate method removeNodeWithTwoChildren():
private void removeNodeWithTwoChildren(Node node) {
Node leftTree = node.left;
Node rightTree = node.right;
setParentsChild(node, leftTree);
// find right-most child of left tree
Node rightMostChildOfLeftTree = leftTree;
while (rightMostChildOfLeftTree.right != null) {
rightMostChildOfLeftTree = rightMostChildOfLeftTree.right;
}
// append right tree to right child
rightMostChildOfLeftTree.right = rightTree;
rightTree.parent = rightMostChildOfLeftTree;
}Code language: Java (java)In the deleteSomeNodes() method of the Example1 class, you can see how some nodes of the example tree are deleted again.
Array Representation of a Binary Tree
Finally, I want to show you an alternative representation of the binary tree: storing it in an array.
The array contains as many elements as a perfect binary tree of the height of the binary tree to be stored, i.e., 2h+1-1 elements for height h (in the following image: 7 elements for height 2).
The nodes of the tree are sequentially numbered from the root down, level by level, from left to right, and mapped to the array, as shown in the following illustration:

For a complete binary tree, we can trim the array accordingly – or store the number of nodes as an additional value.
Advantages and Disadvantages of the Array Representation
Storing a binary tree as an array has the following advantages:
- Storage is more compact, as references to children (and parents, if applicable) are not required.
- Nevertheless, you quickly get from parents to children and vice versa:
For a node at index i,- the left child is at index 2i+1,
- the right child is at index 2i+2,
- the parent node is at index i/2, rounded down.
- You can perform a level-order traversal by simply iterating over the array.
Against these, one must weigh the following disadvantages:
- If the binary tree is not complete, memory is wasted by unused array fields.
- If the tree grows beyond the array size, the data must be copied to a new, larger array.
- As the tree shrinks, the data should be copied (with some margin) to a new, smaller array to free up unused space.
Summary
In this article, you learned what a binary tree is, what types of binary trees exist, what operations you can apply to binary trees, and how to implement a binary tree in Java.