


Java 25 Features
(with Examples)
Java 25 was released on September 16, 2025. You can download it here.
My Java 25 highlights:
- Two years after Virtual Threads, Scoped Values are now also a production feature. With Scoped Values, data can be provided across method chains without having to pass them as parameters from method to method.
- Compact Source Files and Instance Main Methods: For small test and demo programs, as often written when trying out new features, a class declaration is no longer required, and the signature of the
main()method has been greatly simplified: more thanvoid main()is no longer necessary. - With Flexible Constructor Bodies, we are now allowed to execute code in the constructor before calling
super()orthis(). This allows, for example, validating or calculating parameters before calling the super constructor. - With Compact Object Headers, object headers can be compressed from 12 to 8 bytes. This saves memory space and improves performance, especially in applications with many small objects.
- With Stable Values (currently still in preview stage), values can be initialized thread-safely on first access – then they are considered constants and can be optimized by the JVM like final fields, e.g., through constant folding.
Scoped Values – JEP 506
With Java 25, the second feature from “Project Loom” (after Virtual Threads) is completed: After several rounds as an incubator and preview feature, Scoped Values have now also been finalized.
Scoped Values offer an elegant way to make data available across method chains without having to pass them as parameters. Typical example: In a web application, after successful authentication, the logged-in user is stored in a Scoped Value. All subsequent methods – no matter how deep in the call stack they are called – can then directly access this User object:
public class Server {
public static final ScopedValue<User> LOGGED_IN_USER = ScopedValue.newInstance();
private void serve(Request request) {
User loggedInUser = authenticateUser(request);
ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.run(() -> restAdapter.processRequest(request));
}
}Code language: Java (java)Within the call of restAdapter.processRequest(…), the logged-in user can be retrieved at any time via LOGGED_IN_USER.get() – without explicit passing as a parameter. The mechanism is reminiscent of ThreadLocal, but has several advantages:
- Limited scope: The scope is clearly defined and automatically ends with the expiration of
run()orcall(). - Immutability: The stored value cannot be changed – unlike
ThreadLocal– which prevents race conditions and unexpected side effects. - Lower memory footprint: When using
InheritableThreadLocal, values are copied to child threads so that changes in the child thread do not affect the parent thread. Due to immutability, it is not necessary to copy values with Scoped Values.
Scoped Values were first introduced in Java 20 as an incubator feature. With Java 23, they were extended by the generic interface ScopedValue.CallableOp, which enables type-safe exception handling. In Java 24, the convenience methods callWhere() and runWhere() were removed – in favor of a more consistent, fluent style:
// Before Java 24:
Result result = ScopedValue.callWhere(LOGGED_IN_USER, loggedInUser,
() -> doSomethingSmart());
// Since Java 24:
Result result = ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.call(() -> doSomethingSmart());Code language: Java (java)In Java 25, Scoped Values are finalized through JDK Enhancement Proposal 506 and can thus be used in production code.
If you have been using ThreadLocal so far, it’s worth taking a look at the new possibilities. Scoped Values not only offer better readability and maintainability but also fit perfectly into the new world of Virtual Threads.
👉 You can find a detailed introduction in the main article about Scoped Values.
Module Import Declarations – JEP 511
After two rounds as a preview in Java 23 and Java 24, Module Import Declarations have also been finalized in Java 25 through JDK Enhancement Proposal 511 – without further changes.
What Does import module Do?
Since Java 1.0, classes from the package java.lang have been automatically made available. We have always been able to include entire packages with the import statement. What was not possible for a long time: importing entire modules. This is now made possible by import module.
A module import allows you to use all classes from the exported packages of a module:
import module java.base;
public static Map<Character, List<String>> groupByFirstLetter(String... values) {
return Stream.of(values).collect(
Collectors.groupingBy(s -> Character.toUpperCase(s.charAt(0))));
}Code language: Java (java)In the example above, you don’t need to import java.util.List or java.util.stream.Collectors individually – they all belong to the java.base module.
Important: You don’t need a module-info.java for this. Even classic projects without modules benefit from the new mechanism.
Name Conflicts with Multiple Occurring Classes
When two imported modules provide a class with the same name, the compiler cannot immediately know which one is needed. An example is the class Date – it is contained in both java.base and java.sql:
import module java.base;
import module java.sql;
// . . .
Date date = new Date(); // Compiler error: "reference to Date is ambiguous"Code language: Java (java)The solution? You specify which variant you want to use through an explicit class name import:
import module java.base;
import module java.sql;
import java.util.Date; // ⟵ This resolves the ambiguity
// . . .
Date date = new Date();Code language: Java (java)Since Java 24, you can also resolve such conflicts through package imports:
import module java.base;
import module java.sql;
import java.util.*; // ⟵ This also resolves the ambiguity
// . . .
Date date = new Date();Code language: Java (java)Transitive Module Dependencies
A major advantage of import module lies in the support of transitive dependencies: When a module transitively includes another, its exported packages are also available – without any additional import.
Example: java.sql declares a transitive dependency on java.xml:
module java.sql {
requires transitive java.xml;
}Code language: Java (java)This allows you to directly use classes like SAXParserFactory without explicitly importing java.xml:
import module java.sql;
SAXParserFactory factory = SAXParserFactory.newInstance();Code language: Java (java)New in Java 24 (and now final in Java 25) is that java.base also works as a transitive dependency – for example, when you import java.se, which previously had not transitively included java.base.
Effects on JShell and Compact Source Files
JShell and the so-called Compact Source Files, which are also finalized in Java 25 and described in the next section, now automatically import java.base. This reduces boilerplate code in interactive sessions and in compact source files.
👉 You can find more background information, practical examples, and in-depth explanations in the main article about Module Import Declarations.
Compact Source Files and Instance Main Methods – JEP 512
When Java beginners write their first program, it often looks like this:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Code language: Java (java)For experienced developers, this may seem completely self-evident – but beginners are overwhelmed by visibility modifiers like public, classes, static methods, an unused args array, and a somewhat cumbersome System.out.
With Java 25, all of this becomes optional. Compact Source Files and Instance Main Methods – finalized through JDK Enhancement Proposal 512 after four preview rounds with varying feature names – enables compact Java programs without explicit class structure:
void main() {
IO.println("Hello world!");
}Code language: Java (java)Functionality in Detail
A Compact Source File is a .java file that contains no explicit class or package declaration. When compiling, the Java compiler automatically generates a so-called implicitly declared class. This class is not visible and cannot be referenced by other classes.
The main() method – whether in conventional or compact source files – no longer needs to be static or public, and the args parameter is also optional. If the method is not static, i.e., it’s an instance method, an instance of the class is automatically created when the program starts, and the main() method of this instance is called.
The new IO class provides the three most important input and output methods with print(), println(), and readln(). It is located in the java.lang package and is thus automatically available in all Java files without an import statement.
In compact source files, the module java.base is automatically imported. This means all classes of the packages exported by this module are immediately available (i.e., without imports). You can find more information about module imports in the Module Import Declarations section.
Why Is This Important?
These innovations make getting started with Java noticeably easier. Compact programs like this can be executed directly:
void main() {
IO.println(greet("world"));
}
String greet(String name) {
return "Hello " + name + "!";
}Code language: Java (java)The full expressiveness of the language is retained, just with significantly less syntactic overhead. Classes, modifiers, packages, modules can then be introduced when they are needed – as soon as the programs grow larger and require more structure.
Review
In Java 21, the feature was first introduced under the name Unnamed Classes and Instance Main Methods.
In Java 22, the concept of “unnamed classes” was replaced by “implicitly declared classes”. At the same time, the launch protocol that controls which main() method is executed if multiple main() methods exist was simplified.
In Java 23, the java.io.IO helper class was introduced.
In Java 24, the feature was renamed to Simple Source Files and Instance Main Methods without any other changes.
In Java 25, the feature was finalized by JDK Enhancement Proposal 512 and renamed one last time to Compact Source Files and Instance Main Methods. The IO class, which was previously in the java.io package and whose methods were automatically statically imported, was moved to the java.lang package, and its methods must be explicitly imported. Thus, there is no longer a special rule for this one class.
👉 You can find further details about the main() method, the “launch protocol” and special cases in the section Compact Source Files and Instance Main Method in the article about the main() method.
Flexible Constructor Bodies – JEP 513
Constructors in Java were long strictly limited in their structure: no custom code was allowed before calling super(…) or this(…). This often led to sometimes cumbersome constructions – especially when wanting to validate or pre-calculate parameters.
The Problem So Far: Cumbersome Constructor Logic
An example makes this clear:
public class Square extends Rectangle {
public Square(Color color, int area) {
this(color, Math.sqrt(validateArea(area)));
}
private static double validateArea(int area) {
if (area < 0) throw new IllegalArgumentException();
return area;
}
private Square(Color color, double sideLength) {
super(color, sideLength, sideLength);
}
}Code language: Java (java)Here, the validation must be outsourced to a separate method and the conversion of the area to a side length to a separate constructor. Why? Because (until now) super(…) or this(…) always had to be the first statement in a constructor.
This makes the code unnecessarily complex and hard to read – as you surely noticed at first glance at the code ;-)
Flexible Constructors in Java 25
Since Java 25, this anti-pattern is a thing of the past – thanks to “Flexible Constructor Bodies” finalized by JDK Enhancement Proposal 513.
From now on, the rule is: Any code may precede the call to super(…) or this(…) – as long as it doesn’t read from uninitialized instance fields.
This means:
- You can validate parameters.
- You can calculate local variables.
- You can even initialize fields – and this is especially helpful when the super constructor calls methods that are overridden in the subclass.
This leads to much more readable code:
public class Square extends Rectangle {
public Square(Color color, int area) {
if (area < 0) throw new IllegalArgumentException();
double sideLength = Math.sqrt(area);
super(color, sideLength, sideLength);
}
}Code language: Java (java)Here it is clear at first glance what happens:
- The area is validated.
- The side length is calculated.
- The
Rectangleconstructor is called.
Fewer Surprises with Inheritance
A frequently underestimated problem was also the following:
If a method is called in the super constructor, and that method is overridden in the subclass and accesses fields of the subclass there, this can lead to surprises.
Here’s an example:
public class SuperClass {
public SuperClass() {
logCreation(); // ⟵ 2.
}
protected void logCreation() {
System.out.println("SuperClass created"); // ⟵ not invoked;
// method is overridden in ChildClass
}
}
public class ChildClass extends SuperClass {
private final String parameter;
public ChildClass(String parameter) {
super(); // ⟵ 1.
this.parameter = parameter; // ⟵ 4.
}
@Override
protected void logCreation() {
System.out.println("parameter = " + parameter); // ⟵ 3.
}
}Code language: Java (java)A call to new ChildClass("foo") would not output “SuperClass created” or “parameter = foo”. No, this call would output the following:
parameter = nullCode language: plaintext (plaintext)The reason: parameter is only set in step 4 (see source code comments) – i.e., after the super constructor call. The method logCreation() called by the super constructor, which is overridden by ChildClass, therefore accesses an uninitialized field in step 3.
With Flexible Constructor Bodies, this can be easily prevented:
public ChildClass(String parameter) {
this.parameter = parameter;
super();
}Code language: Java (java)We can now assign fields before we call the super constructor.
Review
Flexible Constructor Bodies started in Java 22 under the name “Statements before super(…)”.
In Java 23, the feature received its current name, and the possibility to initialize fields before calling the super constructor was added.
In Java 24, the feature was re-proposed as a preview without changes.
In Java 25, the feature is finalized without changes through JDK Enhancement Proposal 513 and can thus be used in production code.
👉 You can find further use cases, details, and peculiarities in the main article: Flexible Constructor Bodies in Java: Call Code Before super()
Performance Improvements
Java 25 brings performance improvements in various areas of the JVM: Compact Object Headers make memory usage more efficient; Generational Shenandoah optimizes garbage collection. Additionally, there are two extensions to the Ahead-of-Time Class Loading and Linking feature released in Java 24.
Compact Object Headers – JEP 519
Every Java object contains an object header in addition to the actual data fields. This header contains metadata such as the object’s hash code, lock information (for synchronization), object age (for garbage collection), and a pointer to the class data structure.
Until now, this header was typically 12 bytes in size – even 16 bytes with Compressed Class Pointers disabled.
As part of Project Lilliput, JDK developers have managed to reduce the header to 8 bytes – without losing functionality. This more compact variant is called Compact Object Header and saves considerable memory, especially with a large number of small objects.
Structure of the Previous 12-Byte Object Header
This is how the 12-byte header looks so far:
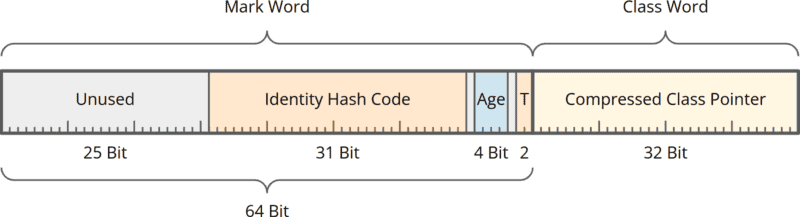
The 12-byte header consists of:
- a Mark Word containing the object’s identity hash code, its age, and two so-called tag bits (for synchronization)
- and a Class Word with a compressed pointer to the class data structure.
Structure of the “Compact” 8-Byte Object Header
And this is how the new 8-byte header is structured (Note: scale changed):
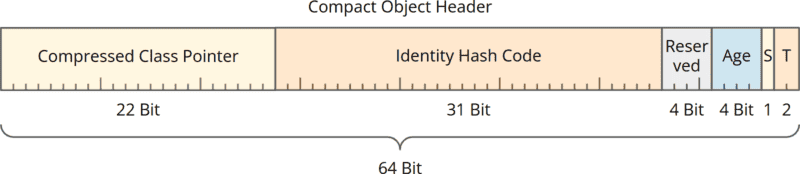
The Compact Object Header is no longer divided into Mark Word and Class Word. It now consists of:
- 22 bits for the class pointer (instead of 32 previously),
- 31 bits for the identity hash code (unchanged),
- 4 reserved bits for Project Valhalla,
- 4 bits for the object age (unchanged),
- 2 bits for locking information (tag bits, unchanged),
- 1 bit for the new Self Forwarded Tag.
What has changed?
- Unused bits removed: The previous layout had 27 unused bits in the mark word (25 at the start, plus one before and one after the age bits) – these were removed.
- Class Pointer compressed: The 32-bit pointer to the class data structure has been reduced to 22 bits – you can learn exactly how this works in the main article about Compact Object Headers.
In Java 24, Compact Object Headers were introduced as an experimental feature. As they have proven to be stable and performant, they are declared a production-ready feature in Java 25 through JDK Enhancement Proposal 519.
You can activate them with the following VM option:
-XX:+UseCompactObjectHeaders
The additional enabling of experimental features through -XX:+UnlockExperimentalVMOptions is no longer required in Java 25.
You can find more details in the main article about Compact Object Headers mentioned above.
Generational Shenandoah – JEP 521
In Java 24, the Generational Mode for the Shenandoah garbage collector was introduced as an experimental feature.
A Generational Garbage Collector takes advantage of the so-called “Weak Generational Hypothesis”: Most objects die shortly after their creation, while long-lived objects typically continue to exist for longer.
To efficiently utilize this property, the garbage collector divides the heap into two areas – a young and an old generation. New objects initially land in the Young Space. Only if they survive multiple GC cycles are they moved to the Old Space. Due to the expected stability of the old generation, it is scanned less frequently – this reduces the number of unnecessary scans and ideally shortens pause times significantly.
This strategy is not new: The G1 Garbage Collector – in use since Java 7 – has always worked on a generational basis. The ZGC has also been using a comparable approach by default since Java 23. With Java 24, Shenandoah followed suit, initially only in experimental mode. The implementation proved to be stable and efficient in practice: Users reported positive results with latency-sensitive applications.
In Java 25, the Generational Mode is now declared a production-ready feature through JDK Enhancement Proposal 521. You can now activate it as follows:
-XX:+UseShenandoahGC -XX:ShenandoahGCMode=generational
The additional option -XX:+UnlockExperimentalVMOptions is no longer required.
Ahead-of-Time Command-Line Ergonomics – JEP 514
When starting a Java application, it can sometimes take seconds to minutes until all Java classes are read, parsed, loaded, and linked. Through Ahead-of-Time Class Loading and Linking introduced in Java 24, which is based on Application Class Data Sharing (AppCDS), these steps can be executed before the application starts, thereby significantly accelerating the application’s startup.
The process previously consisted of three steps:
Step 1: In “Record Mode”, the JVM analyzes the application in a training run and stores information about the loaded and linked classes in the AOT configuration (in the example AotTest.conf):
java -XX:AOTMode=record -XX:AOTConfiguration=AotTest.conf \
-cp AotTest.jar eu.happycoders.AotTestCode language: plaintext (plaintext)Step 2: In “Create Mode”, the JVM generates the AOT cache (AotTest.aot) from the AOT configuration:
java -XX:AOTMode=create -XX:AOTConfiguration=AotTest.conf -XX:AOTCache=AotTest.aot \
-cp AotTest.jarCode language: plaintext (plaintext)Step 3: On each subsequent start of the application, the JVM loads the classes in loaded and linked form directly from this cache and starts correspondingly faster:
java -XX:AOTCache=AotTest.aot -cp AotTest.jar eu.happycoders.AotTestCode language: MIPS Assembly (mipsasm)(In the article linked above, you will be guided step by step through this process.)
JDK Enhancement Proposal 514 introduces the new command-line option -XX:AOTCacheOutput, which allows the first two steps to be executed with a single command:
java -XX:AOTCacheOutput=AotTest.aot -cp AotTest.jar eu.happycoders.AotTestCode language: plaintext (plaintext)Through a new environment variable JDK_AOT_VM_OPTIONS, you can specify VM options that should only apply to the second sub-step (“Create Mode”) – without affecting the first sub-step, the training run (“Record Mode”).
The new combined mode does not replace the two old modes, as there are use cases where it may still make sense to execute the steps separately. For example, if step 1 (the training run) should be executed on a small cloud instance – while step 2 (cache generation, which may take significantly longer in the future due to new optimizations) should be run on a more powerful machine.
Ahead-of-Time Method Profiling – JEP 515
When a Java application is running, the JVM continuously collects data about the called methods, especially about which methods require the most CPU time. These methods are then dynamically optimized and translated into assembler code for the target platform. Since this process takes a while, a Java application is slower at the beginning – in the so-called “warm-up phase” – and only reaches its full performance after a few seconds.
Through Ahead-of-Time Class Loading and Linking, as described in the previous section, a training run creates an AOT cache that contains the classes needed by an application in loaded and linked form, thus accelerating the start of an application.
JDK Enhancement Proposal 515 extends the training run and AOT cache so that, in addition to the binary class data, the aforementioned data on CPU usage of methods (so-called “method profiles”) are also stored in the AOT cache.
Thus, at program start, the most frequently called methods (the so-called “hotspots”) can be directly translated into machine code. This has resulted in measured improvements in startup time of up to 19%, while the size of the AOT cache has only increased by 2.5%.
The changes introduced by JEP 515 do not affect the continuous analysis of method calls and further optimization at runtime, so the application continues to be continuously optimized by the JVM when its behavior changes in production.
Improvements to Java Flight Recorder (JFR)
Java Flight Recorder (JFR) is a tool built into the JVM since Java 11 for diagnosing Java applications. With the JFR, you can profile the application and capture certain events without significantly impacting the application’s performance.
Java 25 includes three improvements to the Java Flight Recorder – one of which is still in Experimental status.
JFR Cooperative Sampling – JEP 518
One function of the Java Flight Recorder is “profiling”. This is not about individual events, but about statistics, e.g., on which methods take up how much time.
This is not done by exact measurement, but by so-called “sampling”: At fixed intervals, the call stacks of all threads are read and stored. From the stored call stacks, the approximate call duration of all methods is then derived using statistical methods.
However, reading an exact stack trace is only possible at so-called “safepoints” – these are designated points in the JVM code where certain required metadata is available. Reading exclusively at these safepoints, however, leads to the so-called “safepoint bias”: If frequently called code is executed disproportionately often far from a safepoint, it is measured inaccurately.
For this reason, sampling has not been performed only at these safepoints until now. However, without the metadata available at the safepoints, heuristics had to be used to generate the call stack. These heuristics are extremely inefficient and can, in the worst case, cause the JVM to crash.
Therefore, the sampling mechanism was modified as follows through JDK Enhancement Proposal 518:
- At regular sampling intervals, only the CPU’s program counter and stack pointer are read.
- Stack traces are read at the subsequent safepoints.
- The call stack at the sampling time is reconstructed using the recorded program counter and stack pointer.
This approach is more performant on the one hand, and simpler in implementation and therefore more stable on the other.
JFR Method Timing & Tracing – JEP 520
In the previous section, I described how the Java Flight Recorder (JFR) profiling works: At certain points in time, call stacks of all threads are read, and the approximate call frequencies and durations of all methods are derived through statistical calculations. However, this method is inaccurate and will never be able to determine the exact number of calls and duration.
Third-party providers such as JProfiler, YourKit or DataDog have always provided tools that connect to the JVM as a so-called Java agent and inject code into the methods to be measured, which precisely measures the call frequency and duration. This, of course, results in a certain overhead.
JDK Enhancement Proposal 520 now creates the possibility within the JVM to measure method calls and their duration precisely. Filters can be used to select specific classes, specific methods, or methods with specific annotations. The advantages: higher accuracy compared to sampling and less overhead compared to using third-party agents.
For example, you can log the stack trace of all interactions with HashMaps using the following options:
java -XX:StartFlightRecording:jdk.MethodTrace#filter=java.util.HashMap,filename=recording.jfr Demo.javaCode language: plaintext (plaintext)Then you can print the stack traces like this:
jfr print --events jdk.MethodTrace --stack-depth 20 recording.jfrCode language: plaintext (plaintext)You can log and print the call times as follows:
java -XX:StartFlightRecording:jdk.MethodTiming#filter=java.util.HashMap,filename=recording.jfr Demo.java
jfr print --events jdk.MethodTiming recording.jfrCode language: plaintext (plaintext)JFR CPU-Time Profiling (Experimental) – JEP 509
In the JFR Cooperative Sampling section, I described how the call frequency and duration of methods can be derived by reading stack traces at fixed intervals.
The times determined in this process are the so-called execution time, i.e., the time that has elapsed from entering the method to exiting it. This time is independent of how the method has used the CPU. A method that executes a sorting algorithm for one second, utilizing 100% of the CPU, has the same execution time as a method that sends a request to the database and waits one second for the response – which, in contrast, uses only minimal CPU resources.
The time during which the method uses the CPU is called CPU time.
If we know which methods use the most CPU time, we can optimize these methods, for example, by replacing a search algorithm with a more efficient one – and thereby reduce the CPU load of the application.
Until now, the Java Flight Recorder did not offer a way to analyze CPU time. This changes with JDK Enhancement Proposal 509 – initially, however, only for Linux.
The new option jdk.CPUTimeSample#enabled=true allows you to activate CPU time sampling. For example, the following command starts a Java application with CPU time sampling activated and outputs the measured data to the file profile.jfr:
java -XX:StartFlightRecording=jdk.CPUTimeSample#enabled=true,filename=profile.jfr ...Code language: plaintext (plaintext)The new option is independent of the option jdk.ExecutionSample#enabled=true, which activates execution time sampling – so you can activate both sampling methods simultaneously and measure execution times and CPU times.
CPU-Time Profiling is currently only available for Linux and is still in the experimental stage. Since it is not a regular VM option, but a JFR option, you do not need to specify the VM option -XX:+UnlockExperimentalVMOptions to activate it.
New Preview Features in Java 25
Even though Java 25 is a long-term support release, that’s no reason for JDK developers not to publish new preview features. A particularly interesting preview feature is Stable Values – values that are initialized once when first accessed and then remain constant, allowing the JVM to optimize access to them.
Preview features are not intended for production use, but for initial experimentation and must be activated with the following VM options:
--enable-preview --source 25
Stable Values (Preview) – JEP 502
Stable Values solve an old problem – the clean, performant, and thread-safe initialization of values that should not (or cannot) be set at program startup, but only upon first access.
Why Do We Need Stable Values?
Immutable values make code simpler, safer, and allow the JVM to perform extensive performance optimizations such as constant folding. Until now, this was only possible by marking a field as final. However, final fields are initialized immediately when a class is loaded (final static fields) or when an object is created (final instance fields).
But if the initialization is complex or context-dependent – for example, because a service is only available later – we have to make do with various forms of lazy initialization. Trivial implementations are often not thread-safe, and thread-safe variants, such as the double-checked locking idiom, are difficult to implement correctly and thus error-prone. In the end, all available solutions are workarounds and exclude JVM optimizations.
Here’s an example of a trivial, non-thread-safe implementation to load program settings from a database upon first access:
private Settings settings;
private Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}
public Locale getLocale() {
return getSettings().getLocale();
}Code language: Java (java)With synchronized, we could make the getSettings() method thread-safe, but that wouldn’t be very performant. You can find a thread-safe and performant – but significantly more complex – variant in the Optimized Double-Checked Locking in Java section of the article on double-checked locking.
The Solution: Stable Values
Stable Values bridge the gap between final and mutable:
- They can be initialized exactly once – at any time and in a thread-safe manner.
- After that, they are considered immutable, allowing the JVM to optimize them like
finalfields. - They eliminate typical sources of errors in self-built lazy initializations.
Here’s the example from above with a Stable Value:
private final Supplier<Settings> settings =
StableValue.supplier(this::loadSettingsFromDatabase);
public Locale getLocale() {
return settings.get().getLocale(); // ⟵ Here we access the stable value
}Code language: Java (java)On the first call to settings.get(…), loadSettingsFromDatabase() is called and the settings are cached within settings. All subsequent accesses then return the cached value. This all happens in a thread-safe manner, meaning if get(…) is called simultaneously from multiple threads, loadSettingsFromDatabase() is only called in one of the threads. The other threads wait until the value is available.
Also Usable as a List
With StableValue.list(), you can define a list whose elements are initialized upon access and then frozen. Example:
List<Double> squareRoots = StableValue.list(100, Math::sqrt);Code language: Java (java)Only upon the first access to a list element – whether with first(), get(int index), last(), or during an iteration – is it calculated. After that, it remains constant, and further accesses to it can be optimized by the JVM – just like accesses to constants.
In addition to Stable Lists, there are also Stable Maps, Stable Functions, and Stable IntFunctions.
You'll find the complete Stable Value API – along with a detailed explanation of how it works internally – in the main article on Stable Values. There, I also take a closer look at the previous workarounds and their drawbacks.
Stable Values have been released in Java 25 as a preview feature through JDK Enhancement Proposal 502.
PEM Encodings of Cryptographic Objects (Preview) – JEP 470
PEM (Privacy-Enhanced Mail) is a widely used format for storing cryptographic keys and certificates. A certificate in PEM format looks like this, for example:
-----BEGIN CERTIFICATE-----
MIIDtzCCAz2gAwIBAgISBUCeYELtjMmr4FAIqHapebbFMAoGCCqGSM49BAMDMDIx
CzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQDEwJF
. . .
DBeMde1YpWNXpF9+B/OMKgn7RgXRj5b2QpBCnFsP92T4cK/Nn+xFIjYCMCCx4E79
toSQBlYnNHv0eXnWkI8TmXsU/A6rU4Gxdr9GbGixgRJvkw0C6zjL/lH2Vg==
-----END CERTIFICATE-----Code language: plaintext (plaintext)Anyone who has ever tried to import keys or certificates in PEM format into a Java application or export them from it will have discovered after painstaking Stack Overflow research: Java does not offer a direct way to do this.
For example, decoding an encrypted private key in PEM format requires more than a dozen lines of code:
String encryptedPrivateKeyPemEncoded = . . .
String passphrase = . . .
String encryptedPrivateKeyBase64Encoded = encryptedPrivateKeyPemEncoded
.replace("-----BEGIN ENCRYPTED PRIVATE KEY-----", "")
.replace("-----END ENCRYPTED PRIVATE KEY-----", "")
.replaceAll("[\\r\\n]", "");
Base64.Decoder decoder = Base64.getDecoder();
byte[] encryptedPrivateKeyBytes = decoder.decode(encryptedPrivateKeyBase64Encoded);
EncryptedPrivateKeyInfo encryptedPrivateKeyInfo =
new EncryptedPrivateKeyInfo(encryptedPrivateKeyBytes);
String algorithmName = encryptedPrivateKeyInfo.getAlgName();
SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithmName);
PBEKeySpec pbeKeySpec = new PBEKeySpec(passphrase.toCharArray());
Key pbeKey = secretKeyFactory.generateSecret(pbeKeySpec);
Cipher cipher = Cipher.getInstance(algorithmName);
AlgorithmParameters algParams = encryptedPrivateKeyInfo.getAlgParameters();
cipher.init(Cipher.DECRYPT_MODE, pbeKey, algParams);
KeyFactory rsaKeyFactory = KeyFactory.getInstance("RSA");
KeySpec keySpec = encryptedPrivateKeyInfo.getKeySpec(cipher);
PrivateKey privateKey = rsaKeyFactory.generatePrivate(keySpec);Code language: Java (java)The feature PEM Encodings of Cryptographic Objects introduced in Java 25 as a preview is intended to significantly simplify this. The code monster above can be simplified in Java 25 with activated preview features as follows:
PrivateKey privateKey = PEMDecoder.of()
.withDecryption(passphrase.toCharArray())
.decode(encryptedPrivateKeyPemEncoded, PrivateKey.class);Code language: Java (java)18 lines of code have been reduced to three lines!
It’s just as easy to encrypt a private key and convert it to PEM format:
String encryptedPrivateKeyPemEncoded = PEMEncoder.of()
.withEncryption(passphrase.toCharArray())
.encodeToString(privateKey);Code language: Java (java)At the center of the new feature are the classes PEMEncoder and PEMDecoder as well as the interface DEREncodable:
- All classes that represent cryptographic keys and certificates (like
PrivateKeyin the example above) implement the new interfaceDEREncodable. - A
PEMEncoderis created – as shown above – with the static methodPEMEncoder.of(). The instance methodsencode(…)andencodeToString(…)can then be used to convert cryptographic objects to PEM format (binary or as a string). - A
PEMDecoderis created with the static methodPEMDecoder.of(). PEM files can then be converted into a cryptographic object using thedecode()method. - The
PEMDecoder.decode()method also exists without the second parameter, which in the example above specifies the expected return typePrivateKey.class. This variant returns aDEREncodable, which can then be evaluated using Pattern Matching for switch, for example. - To encrypt a private key, the
PEMEncodermust be created withPEMEncoder.of().withEncryption(passphrase)– as in the example above. To decrypt it again, thePEMDecodermust be created analogously withPEMDecoder.of().withDecryption(passphrase). PEMEncoderandPEMDecoderinstances are stateless and thread-safe – thus a single instance can be shared and reused by multiple threads.- If the
decode()method cannot decode the PEM data, no exception is thrown, but a genericPEMRecordobject is returned containing the binary data of the PEM file.
PEM Encodings of Cryptographic Objects is specified in JDK Enhancement Proposal 470.
Resubmitted Preview and Incubator Features
Three features didn’t make it to be finalized in Java 25 and are going into a new preview or incubator round: Structured Concurrency, Primitive Type Patterns, and – not surprisingly – the Vector API.
Structured Concurrency (Fifth Preview) – JEP 505
When a task can be broken down into multiple subtasks that can be executed independently and in parallel, you can use Structured Concurrency to coordinate these subtasks in a clearly structured, traceable, and efficient manner.
Instead of complex and error-prone logic with, for example, ExecutorService or parallel streams, we get an API that summarizes the start, completion, and error handling of all subtasks in a clearly defined code block.
Structured concurrency scopes can be nested arbitrarily. This allows you to clearly model complex task structures while maintaining an overview and control over the lifecycle of all subtasks at all times:

With Java 25, Structured Concurrency is already entering its fifth preview round – for the first time since the first preview version in Java 21, however, with significant changes to the API. The changes are specified in JDK Enhancement Proposal 505 and are based on extensive feedback from the community.
If you haven’t dealt with Structured Concurrency yet and therefore aren’t interested in the changes, feel free to jump directly to the section Example: The Fastest Response Wins.
What’s New in Java 25?
The way a StructuredTaskScope is opened has been fundamentally revised:
- Instead of using
newand the constructor, aStructuredTaskScopeis now opened via the static factory methodStructuredTaskScope.open(). - If
open()is called without parameters, aStructuredTaskScopeis created that waits for all subtasks to complete successfully … or one subtask to fail – just like the previous specialized implementationShutdownOnFailure. Thus,new StructuredTaskScope.ShutdownOnFailure()becomesStructuredTaskScope.open(). - Other strategies are no longer created by deriving from
StructuredTaskScope, but by a so-called joiner, which is passed as a parameter to theopen()method. - The
Joinerinterface defines static factory methods to create joiners for frequently needed strategies. Joiner.anySuccessfulResultOrThrow()creates a joiner that returns a result as soon as the first subtask is successful – just like the specializedStructuredTaskScopeimplementationShutdownOnSuccessdid before. Thus, newStructuredTaskScope.ShutdownOnSuccess()becomesStructuredTaskScope.open(Joiner.anySuccessfulResultOrThrow()).- Custom join strategies can be implemented by implementing the
Joinerinterface instead of extendingStructuredTaskScope.
Additionally, the completion of processing has been simplified:
- The method
StructuredTaskScope.result()has been removed – nowStructuredTaskScope.join()returns the result. For example,scope.join(); return scope.result();thus becomesreturn scope.join(); - Similarly, the method
StructuredTaskScope.throwIfFailed()has been removed – in case of an exception, it is now also thrown byStructuredTaskScope.join(). This makes error handling more robust. StructuredTaskScope.join()no longer throws a genericExecutionExceptionin case of an error, but a Structured Concurrency-specificFailedExceptionor aTimeoutException.
Here you can see the changes using the example of the race() method, which I have shown in some previous articles:
Old implementation up to Java 24:
public static <R> R race(Callable<R> task1, Callable<R> task2)
throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<R>()) {
scope.fork(task1);
scope.fork(task2);
scope.join();
return scope.result();
}
}Code language: Java (java)New implementation from Java 25:
public static <R> R race(Callable<R> task1, Callable<R> task2)
throws InterruptedException {
Joiner<R, R> joiner = Joiner.anySuccessfulResultOrThrow();
try (var scope = StructuredTaskScope.open(joiner)) {
scope.fork(task1);
scope.fork(task2);
return scope.join();
}
}Code language: Java (java)These changes decouple StructuredTaskScope and join strategy, leading to more flexible and maintainable code (keyword: Composition over inheritance).
Example: The Fastest Response Wins
A common scenario is querying multiple services in parallel, where the first valid response should be used – in the following example when obtaining weather data:
WeatherResponse getWeatherFast(Location location) throws InterruptedException {
Joiner<WeatherResponse, WeatherResponse> joiner = Joiner.anySuccessfulResultOrThrow();
try (var scope = StructuredTaskScope.open(joiner)) {
scope.fork(() -> weatherService.readFromStation1(location));
scope.fork(() -> weatherService.readFromStation2(location));
scope.fork(() -> weatherService.readFromStation3(location));
return scope.join();
}
}Code language: Java (java)As soon as one of the tasks is successful, the others are automatically canceled. The scope.join() method returns the result of the first successful task or throws a FailedException if no task was completed successfully.
Without Structured Concurrency, you would have to implement the same task with significantly more code, manual thread handling, and custom error logic – which would not only be more time-consuming but also much more prone to bugs.
Conclusion
With JEP 505, Structured Concurrency takes a big step towards finalization. The revised API is more clearly structured, easier to understand, and more robust in error handling.
It once again shows how valuable the feedback from the Java community is during the preview phase of a feature: Only through feedback from practical use could the weaknesses of the previous API be identified and specifically improved.
You can find a more detailed description and numerous other examples in the main article about Structured Concurrency.
Primitive Types in Patterns, instanceof, and switch (Third Preview) – JEP 507
Pattern Matching is one of the most exciting developments in recent years. What began with Pattern Matching for instanceof in Java 16 and was expanded with Pattern Matching for switch in Java 21 is now being extended – to primitive data types like int, double, or boolean.
Until now, pattern matching was limited to reference types. For example, like this:
switch (obj) {
case String s when s.length() >= 5 -> System.out.println(s.toUpperCase());
case Integer i -> System.out.println(i * i);
case null, default -> System.out.println(obj);
}Code language: Java (java)This wasn’t possible with primitive values. While you have long been able to compare primitive values like int with constants in the classic switch …
int code = ...
switch (code) {
case 200 -> System.out.println("OK");
case 404 -> System.out.println("Not Found");
}Code language: Java (java)… but this only worked with byte, short, char and int – but not with long, float, double or boolean. And instanceof didn’t work with primitive types at all.
This will change with Primitive Types in Patterns, instanceof, and switch:
- All primitive types (
int,long,float,double,char,byte,short,boolean) can now be used inswitchstatements and expressions – both with constants and with pattern matching.
- Pattern matching with primitive types is now also possible with
instanceof.
What Exactly Does Pattern Matching with Primitive Types Mean?
When pattern matching with reference types, you ask: “Is this object an instance of type XY or one of its subclasses?” With primitive types, it works differently because there is no inheritance. Instead, it checks: Can the current value be represented in a specific target type without loss of precision?
An example:
int i = ...
if (i instanceof byte b) {
System.out.println("b = " + b);
}Code language: Java (java)Here, i matches the pattern byte b if the value also fits in a byte. For i = 100 this would be the case, for i = 500 it wouldn’t.
Or with floating-point numbers:
double d = ...
if (d instanceof float f) {
System.out.println("f = " + f);
}Code language: Java (java)Here, the rule is: Only if d fits into a float without loss of precision does the pattern match. This works for 1.5, but not for Math.PI or 16,777,217. Both numbers are too precise to be stored in a 32-bit float variable.
You can – as with reference types – attach additional conditions:
int a = ...
if (a instanceof byte b && b > 0) {
System.out.println("b = " + b);
}Code language: Java (java)In this case, the pattern only matches if a can be represented losslessly as byte and the value is additionally greater than 0.
Pattern Matching with Switch and Primitive Types
This doesn’t just work with instanceof, but also with switch. Here’s a complete example:
double value = ...
switch (value) {
case byte b -> System.out.println(value + " instanceof byte: " + b);
case short s -> System.out.println(value + " instanceof short: " + s);
case char c -> System.out.println(value + " instanceof char: " + c);
case int i -> System.out.println(value + " instanceof int: " + i);
case long l -> System.out.println(value + " instanceof long: " + l);
case float f -> System.out.println(value + " instanceof float: " + f);
case double d -> System.out.println(value + " instanceof double: " + d);
}Code language: Java (java)Depending on the specific value, the first matching case is executed:
- For
value = 42, for example, the patternbyte bmatches because the value can be stored asbytewithout loss of information. - For
value = 200,byteno longer fits, butshortdoes – so theshort sbranch is executed. - For
value = 65000,shortalso no longer applies, butchar cdoes, ascharcan represent values from 0 to 65,535. - For
value = 500000,byte,short, andcharare too small – hereint ifits. - For
value = 3.14, no integer representation is possible, but the value fits into afloatwithout loss of precision, so the branch behindfloat fis executed. - For
value = Math.PI, onlydouble dremains, asMath.PIis too precise forfloat.
As with object types, the same applies here: You must cover all cases or specify a default branch to ensure exhaustive checking.
Subtleties: Dominance and Exhaustiveness
The principle of dominance also plays an important role for primitive types: An int value basically also fits into a long, so a pattern long l would also catch all int values – and therefore must not stand before a pattern int i in the code.
Additionally, as with all modern switch features, the rule of exhaustiveness applies: The switch block must cover all theoretically possible cases. If this is not possible or not sensible, you must define a default branch to avoid compiler errors.
You can find more about the exact rules for dominance and exhaustiveness, as well as further examples and peculiarities, in the main article Primitive Types in Patterns, instanceof and switch.
Review
Primitive Types in Patterns, instanceof, and switch was first introduced in Java 23 through JEP 455 and reintroduced without changes as a preview in Java 24 through JEP 488. In Java 25, it now goes into the third preview round, specified by JDK Enhancement Proposal 507 – again without changes, to gather further feedback from the Java community.
Vector API (Tenth Incubator) – JEP 508
The Vector API is presented for the tenth time in the incubator stage – specified by JDK Enhancement Proposal 508.
The API allows mathematical vector operations like the following to be executed particularly efficiently:
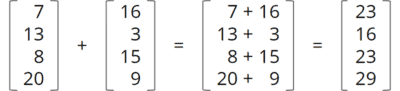
The JVM can map these operations so that they – depending on the vector size – directly access the vector instruction sets of modern CPUs. In many cases, such a calculation can be executed in a single CPU cycle.
The Vector API remains an incubator feature until the building blocks it requires from Project Valhalla have reached the preview stage. As soon as the Vector API is available in a first preview version, I will describe it in detail with practical examples.
Other Changes in Java 25
In this section, you’ll find changes that couldn’t be sorted into the other chapters. These are less prominent JEPs, removals, and some (selected by me from the release notes) minor changes that were implemented without a JEP.
Key Derivation Function API – JEP 510
A Key Derivation Function (KDF) allows additional cryptographic keys to be derived from a secret input value – such as a password, passphrase, or existing key.
For KDFs to be used consistently and implemented by security providers, a standardized interface is needed. This is exactly what JDK Enhancement Proposal 510 provides with the Key Derivation Function API and the javax.crypto.KDF class.
Through this API, you can load and use various KDF algorithms. In the following example, we use “HKDF-SHA256” to derive an AES key from a password and a salt:
void main() throws InvalidAlgorithmParameterException, NoSuchAlgorithmException {
KDF hkdf = KDF.getInstance("HKDF-SHA256");
AlgorithmParameterSpec params =
HKDFParameterSpec.ofExtract()
.addIKM("the super secret passphrase".getBytes(StandardCharsets.UTF_8))
.addSalt("the salt".getBytes(StandardCharsets.UTF_8))
.thenExpand("my derived key".getBytes(StandardCharsets.UTF_8), 32);
SecretKey key = hkdf.deriveKey("AES", params);
System.out.println("key = " + HexFormat.of().formatHex(key.getEncoded()));
}Code language: Java (java)If you’re wondering about the compact main() method: This is part of the innovations covered in the Compact Source Files and Instance Main Methods section.
Explanations for the abbreviations used in the code can be found in the following Wikipedia articles:
- HKDF stands for “HMAC-based Key Derivation Function”.
- HMAC means “Hash-based Message Authentication Code”.
- IKM refers to the “input key material”, for example, the password.
- AES is the “Advanced Encryption Standard”, a widely used encryption algorithm.
When you run the example, you should get the following output:
key = 7ee15549ddce956194ca1d6df5aa34c1a1334d15c875e67ea67fb5850ee48b0cCode language: plaintext (plaintext)The key generated in this way can be used, for example, as a session key for secure data transfer.
The Key Derivation Function API was first introduced in Java 24 as a preview feature and is now a permanent part of the JDK from Java 25 onwards, without changes compared to the preview version.
Remove the 32-bit x86 Port – JEP 503
After the 32-bit port for Windows was removed in Java 24, the last remaining 32-bit variant – the one for Linux – is now being completely removed in Java 25 through JDK Enhancement Proposal 503.
This eliminates the extra effort for developing and testing 32-bit ports, allowing JDK developers to focus entirely on new features.
Relax String Creation Requirements in StringBuilder and StringBuffer
The specifications of the substring(), subSequence(), and toString() methods of the StringBuilder and StringBuffer classes previously required that a newly created String object is always returned. This requirement has been removed from the specification, so these methods can now, for example, return a "" constant for an empty string, which is faster than creating a new empty string.
There is no JEP for this change; it is listed in the bug tracker under JDK-8138614.
New Methods on BodyHandlers and BodySubscribers to Limit the Number of Response Body Bytes Accepted by the HttpClient
The classes java.net.http.HttpResponse.BodyHandlers and java.net.http.HttpResponse.BodySubscribers have each been extended with a limiting() method, which can be used to limit the size of a response to an HTTP request.
There is no JEP for this change; it is listed in the bug tracker under JDK-8328919.
The UseCompressedClassPointers Option is Deprecated
By default, the JVM works with Compressed Class Pointers – these are 32-bit compressed pointers in the object header that point to the class data structure belonging to the object.
Before Compressed Class Pointers were introduced, these pointers were 64 bits long on 64-bit systems. This mode can currently still be reactivated through -XX:-UseCompressedClassPointers. However, this is practically irrelevant, as 32-bit pointers are sufficient to address 4 GB and thus approximately 6 million classes. Even large Java applications rarely count more than 100,000 classes.
With Compact Object Headers activated in Java 25, class pointers are further compressed to just 22 bits, allowing approximately 4 million – still sufficient – classes to be addressed.
Support for uncompressed class pointers will be removed in Java 27. Accordingly, the UseCompressedClassPointers option was deprecated in Java 25.
There is no JEP for this change; it is listed in the bug tracker under JDK-8350753.
Various Permission Classes Deprecated for Removal
In Java 17, the Security Manager was marked as deprecated for removal. Since Java 24, the Security Manager can no longer be activated.
In Java 25, numerous …Permission classes, which were only usable in connection with the Security Manager, have now also been marked as deprecated for removal.
You can read which classes are affected in detail in the bug tracker under JDK-8348967, JDK-8353641, JDK-8353642, and JDK-8353856.
Syntax Highlighting for Code Fragments
The javadoc tool has been extended with the command line option --syntax-highlight. If this option is specified when calling the javadoc command, the library Highlight.js is included in the generated documentation and the code in {@snippet} tags and HTML elements is color-coded accordingly.
There is no JEP for this change; it is listed in the bug tracker under JDK-8348282.
JavaDoc documentation generated with Java 25 can now be navigated using the keyboard:
/focuses the search field in the top right..focuses the filter field in the sidebar.Escremoves the focus from the search or filter field.- With
Taband the arrow keys, you can navigate in the sidebar and the search results.
There is no JEP for this change; it is listed in the bug tracker under JDK-8350638.
Add Standard System Property stdin.encoding
The new system property stdin.encoding can be used to set the character encoding for reading System.in. If not explicitly specified – e.g., through -Dstdin.encoding=UTF-8 – the value is determined by the operating system and user environment.
Note that this setting is not automatically used, but must be explicitly read and applied by an application, e.g., when using InputStreamReader or Scanner.
There is no JEP for this change; it is listed in the bug tracker under JDK-8350703.
The jwebserver Tool -d Command Line Option Now Accepts Directories Specified with a Relative Path
In Java 18, the so-called Simple Web Server was introduced – a rudimentary HTTP server that can be quickly started to serve static web pages.
For example, the following command serves the /tmp directory at IP address 127.0.0.100 and port 4444:
jwebserver -b 127.0.0.100 -p 4444 -d /tmpCode language: plaintext (plaintext)Previously, an absolute path had to be specified (via the -d parameter) – which was cumbersome when wanting to share a directory via HTTP within the current project. From Java 25 onwards, a relative directory name can now be specified.
There is no JEP for this change; it is listed in the bug tracker under JDK-8355360.
java.io.File Treats the Empty Pathname as the Current User Directory
A java.io.File object created with new File("") previously led to undefined and inconsistent behavior when calling methods on this object. From Java 25 onwards, this creates a File object that represents the current directory.
This aligns the behavior of File with java.nio.Path – Path.of("") always created a representation of the current directory.
There is no JEP for this change; it is listed in the bug tracker under JDK-8024695.
java.io.File.delete No Longer Deletes Read-Only Files on Windows
Previously, calling File.delete() on Windows could also delete files marked as “read-only”. From Java 25 onwards, such files will no longer be deleted, and delete() will return false accordingly.
The previous behavior can be restored with the system property -Djdk.io.File.allowDeleteReadOnlyFiles=true.
There is no JEP for this change; it is listed in the bug tracker under JDK-8355954.
Complete List of All Changes in Java 25
In this article, I have presented all JDK Enhancement Proposals (JEPs) as well as a selection of other changes without JEP that were implemented in Java 25. A complete list of all changes can be found in the Java 25 Release Notes.
Conclusion
Java 25 is once again a well-rounded LTS (long-term-support) release.
- With Scoped Values, the second feature from Project Loom has been finalized. It’s a shame that Structured Concurrency didn’t make it into this release – but thanks to the 6-month release cycle, we’d rather get a mature feature later than an immature one too early.
- Module Import Declarations make the import block more organized – it remains to be seen to what extent this will be adopted (outside of JShell and compact source files) – nowadays, the IDE primarily takes care of managing imports.
- Compact Source Files and Instance Main Methods allow us to write short test and demo programs more quickly. They are also intended to simplify learning the language for beginners.
- Flexible Constructor Bodies finally allow us to call code in constructors before calling
super()orthis(), making unsightly workarounds, e.g., for checking parameters before calling the super constructor, obsolete. - Compact Object Headers, when activated, reduce the object header from 12 to 8 bytes, thereby reducing the memory footprint, especially for applications with many small objects.
- Generational Shenandoah speeds up applications that use the Shenandoah Garbage Collector. However, specific figures are not mentioned in the JEPs.
- Ahead-of-Time Command-Line Ergonomics simplify the creation of an AOT cache, and Ahead-of-Time Method Profiling also stores information about method calls in the AOT cache, which can lead to significant improvements in startup time as frequently called methods can be optimized immediately.
Further minor changes round off the LTS release as always. You can download Java 25 here.
Which Java 25 feature are you most excited about? Write it in the comments!