


Selection Sort – Algorithm, Source Code, Time Complexity
This article is part of the series "Sorting Algorithms: Ultimate Guide" and…
- describes how Selection Sort works,
- includes the Java source code for Selection Sort,
- shows how to derive its time complexity (without complicated math)
- and checks whether the performance of the Java implementation matches the expected runtime behavior.
You can find the source code for the entire article series in my GitHub repository.
Example: Sorting Playing Cards
Sorting playing cards into the hand is the classic example for Insertion Sort.
Selection Sort can also be illustrated with playing cards. I don't know anybody who picks up their cards this way, but as an example, it works quite well ;-)
First, you lay all your cards face-up on the table in front of you. You look for the smallest card and take it to the left of your hand. Then you look for the next larger card and place it to the right of the smallest card, and so on until you finally pick up the largest card to the far right.

Difference to Insertion Sort
With Insertion Sort, we took the next unsorted card and inserted it in the right position in the sorted cards.
Selection Sort kind of works the other way around: We select the smallest card from the unsorted cards and then – one after the other – append it to the already sorted cards.
Selection Sort Algorithm
The algorithm can be explained most simply by an example. In the following steps, I show how to sort the array [6, 2, 4, 9, 3, 7] with Selection Sort:
Step 1
We divide the array into a left, sorted part and a right, unsorted part. The sorted part is empty at the beginning:

Step 2
We search for the smallest element in the right, unsorted part. To do this, we first remember the first element, which is the 6. We go to the next field, where we find an even smaller element in the 2. We walk over the rest of the array, looking for an even smaller element. Since we can't find one, we stick with the 2. We put it in the correct position by swapping it with the element in the first place. Then we move the border between the array sections one field to the right:

Step 3
We search again in the right, unsorted part for the smallest element. This time it is the 3; we swap it with the element in the second position:

Step 4
Again we search for the smallest element in the right section. It is the 4, which is already in the correct position. So there is no need for swapping operation in this step, and we just move the section border:

Step 5
As the smallest element, we find the 6. We swap it with the element at the beginning of the right part, the 9:

Step 6
Of the remaining two elements, the 7 is the smallest. We swap it with the 9:

Algorithm Finished
The last element is automatically the largest and, therefore, in the correct position. The algorithm is finished, and the elements are sorted:

Selection Sort Java Source Code
In this section, you will find a simple Java implementation of Selection Sort.
The outer loop iterates over the elements to be sorted, and it ends after the second-last element. When this element is sorted, the last element is automatically sorted as well. The loop variable i always points to the first element of the right, unsorted part.
In each loop cycle, the first element of the right part is initially assumed as the smallest element min; its position is stored in minPos.
The inner loop then iterates from the second element of the right part to its end and reassigns min and minPos whenever an even smaller element is found.
After the inner loop has been completed, the elements of positions i (beginning of the right part) and minPos are swapped (unless they are the same element).
public class SelectionSort {
public static void sort(int[] elements) {
int length = elements.length;
for (int i = 0; i < length - 1; i++) {
// Search the smallest element in the remaining array
int minPos = i;
int min = elements[minPos];
for (int j = i + 1; j < length; j++) {
if (elements[j] < min) {
minPos = j;
min = elements[minPos];
}
}
// Swap min with element at pos i
if (minPos != i) {
elements[minPos] = elements[i];
elements[i] = min;
}
}
}
}Code language: Java (java)The code shown differs from the SelectionSort class in the GitHub repository in that it implements the SortAlgorithm interface to be easily interchangeable within the test framework.
Selection Sort Time Complexity
We denote with n the number of elements, in our example n = 6.
The two nested loops are an indication that we are dealing with a time complexity* of O(n²). This will be the case if both loops iterate to a value that increases linearly with n.
It is obviously the case with the outer loop: it counts up to n-1.
What about the inner loop?
Look at the following illustration:
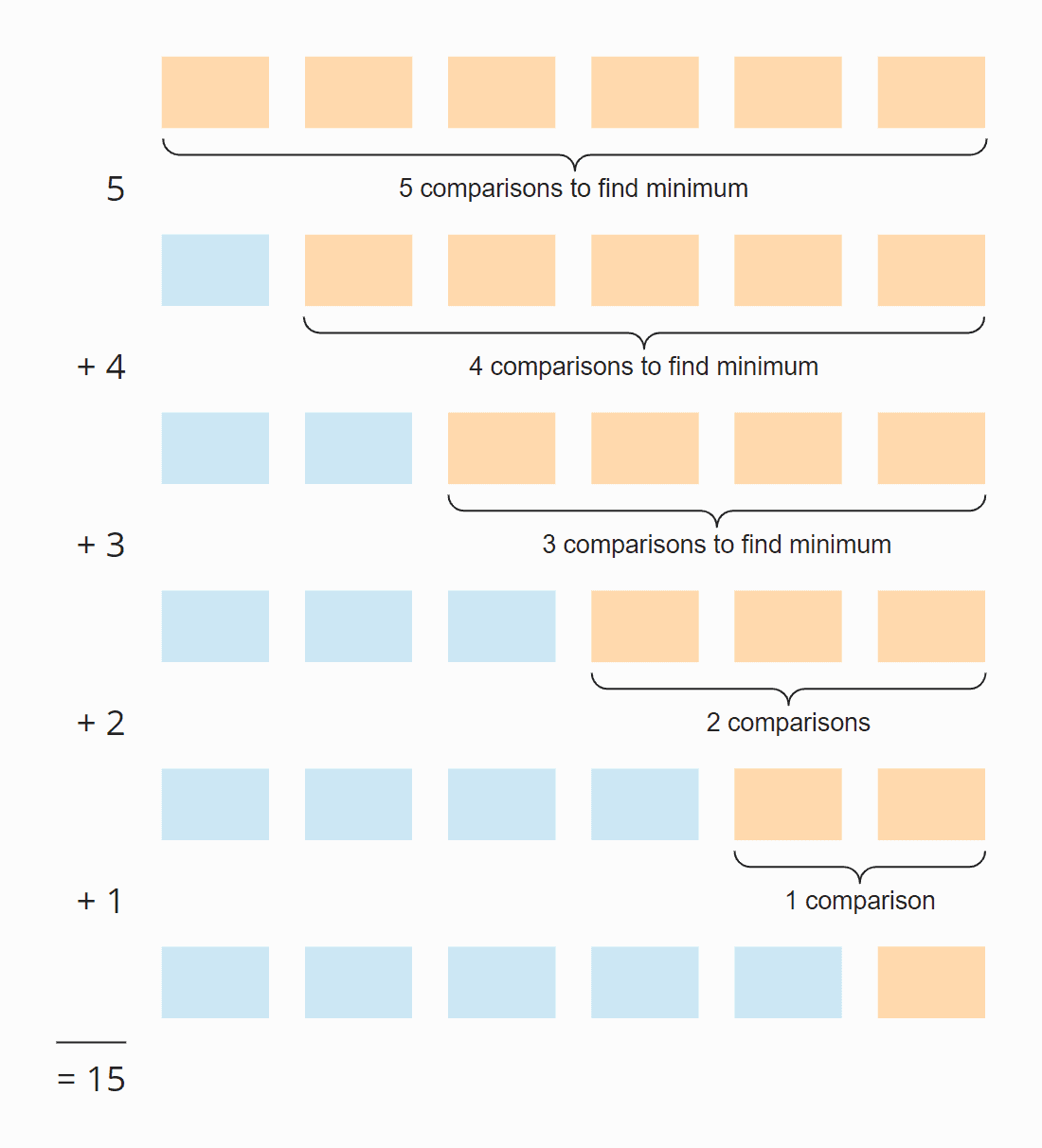
In each step, the number of comparisons is one less than the number of unsorted elements. In total, there are 15 comparisons – regardless of whether the array is initially sorted or not.
This can also be calculated as follows:
Six elements times five steps; divided by two, since on average over all steps, half of the elements are still unsorted:
6 × 5 × ½ = 30 × ½ = 15
If we replace 6 with n, we get
n × (n – 1) × ½
When multiplied, that's:
½ n² – ½ n
The highest power of n in this term is n². The time complexity for searching the smallest element is, therefore, O(n²) – also called "quadratic time".
Let's now look at the swapping of the elements. In each step (except the last one), either one element is swapped or none, depending on whether the smallest element is already at the correct position or not. Thus, we have, in sum, a maximum of n-1 swapping operations, i.e., the time complexity of O(n) – also called "linear time".
For the total complexity, only the highest complexity class matters, therefore:
The average, best-case, and worst-case time complexity of Selection Sort is: O(n²)
* The terms "time complexity" and "O-notation" are explained in this article using examples and diagrams.
Runtime of the Java Selection Sort Example
Enough theory! I have written a test program that measures the runtime of Selection Sort (and all other sorting algorithms covered in this series) as follows:
- The number of elements to be sorted doubles after each iteration from initially 1,024 elements up to 536,870,912 (= 229) elements. An array twice this size cannot be created in Java.
- If a test takes longer than 20 seconds, the array is not extended further.
- All tests are run with unsorted as well as ascending and descending pre-sorted elements.
- We allow the HotSpot compiler to optimize the code with two warmup rounds. After that, the tests are repeated until the process is aborted.
After each iteration, the program prints out the median of all previous measurement results.
Here is the result for Selection Sort after 50 iterations (for the sake of clarity, this is only an excerpt; the complete result can be found here):
| n | unsorted | ascending | descending |
|---|---|---|---|
| ... | ... | ... | ... |
| 16.384 | 27,9 ms | 26,8 ms | 65,6 ms |
| 32.768 | 108,0 ms | 105,4 ms | 265,4 ms |
| 65.536 | 434,0 ms | 424,3 ms | 1.052,2 ms |
| 131.072 | 1.729,8 ms | 1.714,1 ms | 4.209,9 ms |
| 262.144 | 6.913,4 ms | 6.880,2 ms | 16.863,7 ms |
| 524.288 | 27.649,8 ms | 27.568,7 ms | 67.537,8 ms |
Here the measurements once again as a diagram (whereby I have displayed "unsorted" and "ascending" as one curve due to the almost identical values):
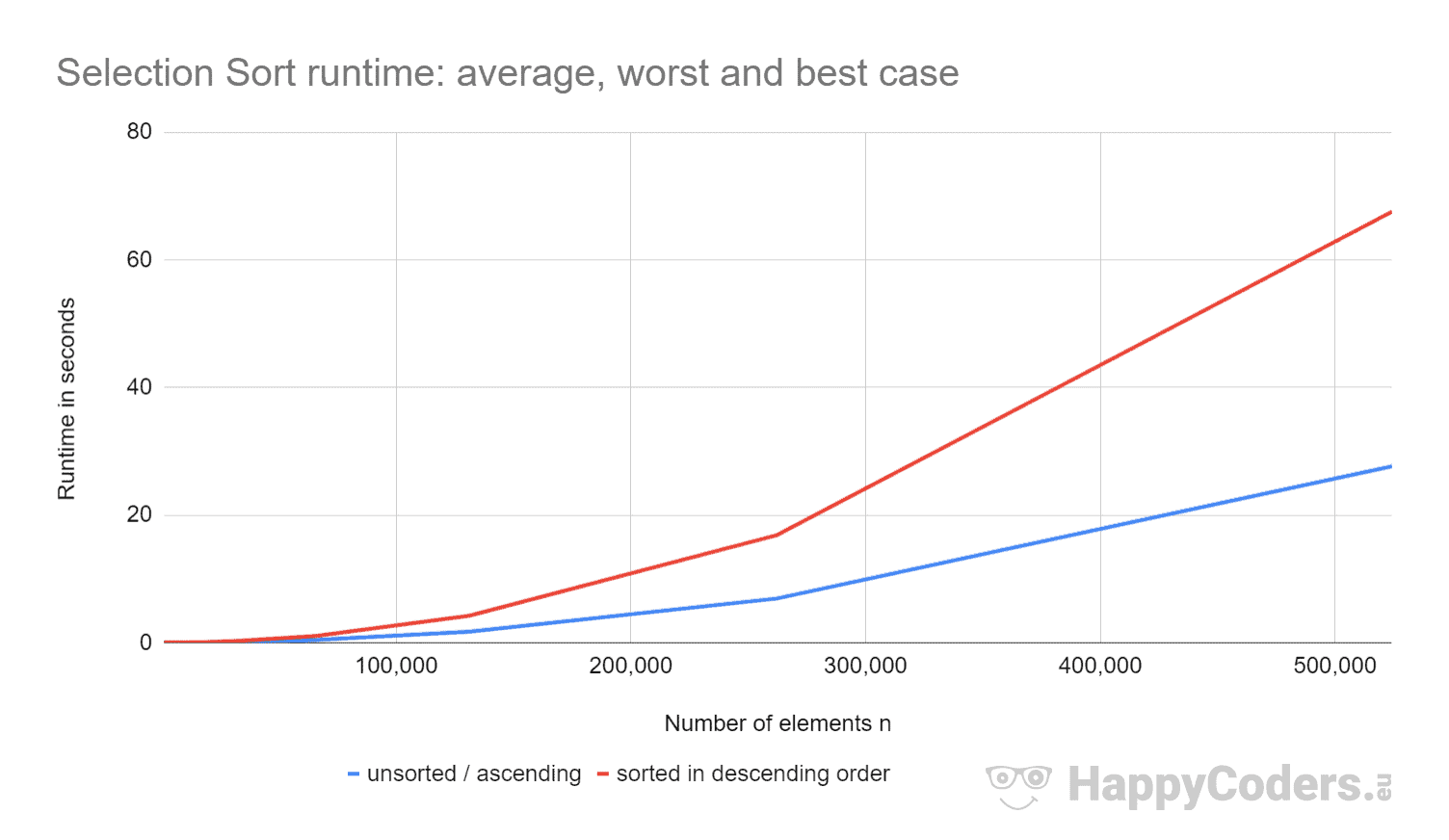
It's good to see that
- if the number of elements is doubled, the runtime is approximately quadrupled – regardless of whether the elements are previously sorted or not. This corresponds to the expected time complexity of O(n²).
- that the runtime for ascending sorted elements is slightly better than for unsorted elements. This is because the swapping operations, which – as analyzed above – are of little importance, are not necessary here.
- that the runtime for descending sorted elements is significantly worse than for unsorted elements.
Why is that?
Analysis of the Worst-Case Runtime
Theoretically, the search for the smallest element should always take the same amount of time, regardless of the initial situation. And the swap operations should only be slightly more for elements sorted in descending order (for elements sorted in descending order, every element would have to be swapped; for unsorted elements, almost every element would have to be swapped).
Using the CountOperations program from my GitHub repository, we can see the number of various operations. Here are the results for unsorted elements and elements sorted in descending order, summarized in one table:
| n | Comparisons | Swaps unsorted | Swaps descending | minPos/min unsorted | minPos/min descending |
|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... |
| 512 | 130.816 | 504 | 256 | 2.866 | 66.047 |
| 1.024 | 523.776 | 1.017 | 512 | 6.439 | 263.167 |
| 2.048 | 2.096.128 | 2.042 | 1.024 | 14.727 | 1.050.623 |
| 4.096 | 8.386.560 | 4.084 | 2.048 | 30.758 | 4.198.399 |
| 8.192 | 33.550.336 | 8.181 | 4.096 | 69.378 | 16.785.407 |
From the measured values can be seen:
- With elements sorted in descending order, we have – as expected – as many comparison operations as with unsorted elements – that is, n × (n-1) / 2.
- With unsorted elements, we have – as assumed – almost as many swap operations as elements: for example, with 4,096 unsorted elements, there are 4,084 swap operations. These numbers change randomly from test to test.
- However, with elements sorted in descending order, we only have half as many swap operations as elements! This is because, when swapping, we not only put the smallest element in the right place, but also the respective swapping partner.
With eight elements, for example, we have four swap operations. In the first four iterations, we have one each and in the iterations five to eight, none (nevertheless the algorithm continues to run until the end):

Furthermore, we can read from the measurements:
- The reason why Selection Sort is so much slower with elements sorted in descending order can be found in the number of local variable assignments (
minPosandmin) when searching for the smallest element. While with 8,192 unsorted elements, we have 69,378 of these assignments, with elements sorted in descending order, there are 16,785,407 such assignments – that's 242 times as many!
Why this huge difference?
Analysis of the Runtime of the Search for the Smallest Element
For elements sorted in descending order, the order of magnitude can be derived from the illustration just above. The search for the smallest element is limited to the triangle of the orange and orange-blue boxes. In the upper orange part, the numbers in each box become smaller; in the right orange-blue part, the numbers increase again.
Assignment operations take place in each orange box and the first of the orange-blue boxes. The number of assignment operations for minPos and min is thus, figuratively speaking, about "a quarter of the square" – mathematically and precisely, it's ¼ n² + n - 1.
For unsorted elements, we would have to penetrate much deeper into the matter. That would not only go beyond the scope of this article, but of the entire blog.
Therefore, I limit my analysis to a small demo program that measures how many minPos/min assignments there are when searching for the smallest element in an unsorted array. Here are the average values after 100 iterations (a small excerpt; the complete results can be found here):
| n | average number of minPos/min assignments |
|---|---|
| 1.024 | 7.08 |
| 4.096 | 8.61 |
| 16.385 | 8.94 |
| 65.536 | 11.81 |
| 262.144 | 12.22 |
| 1.048.576 | 14.26 |
| 4.194.304 | 14.71 |
| 16.777.216 | 16.44 |
| 67.108.864 | 17.92 |
| 268.435.456 | 20.27 |
Here as a diagram with logarithmic x-axis:

The chart shows very nicely that we have logarithmic growth, i.e., with every doubling of the number of elements, the number of assignments increases only by a constant value. As I said, I will not go deeper into mathematical backgrounds.
This is the reason why these minPos/min assignments are of little significance in unsorted arrays.
Other Characteristics of Selection Sort
In the following sections, I will discuss the space complexity, stability, and parallelizability of Selection Sort.
Space complexity of Selection Sort
Selection Sort's space complexity is constant since we do not need any additional memory space apart from the loop variables i and j and the auxiliary variables length, minPos, and min.
That is, no matter how many elements we sort – ten or ten million – we only ever need these five additional variables. We note constant time as O(1).
Stability of Selection Sort
Selection Sort appears stable at first glance: If the unsorted part contains several elements with the same key, the first should be appended to the sorted part first.
But appearances are deceptive. Because by swapping two elements in the second sub-step of the algorithm, it can happen that certain elements in the unsorted part no longer have the original order. This, in turn, leads to the fact that they no longer appear in the original order in the sorted section.
An example can be constructed very simply. Suppose we have two different elements with key 2 and one with key 1, arranged as follows, and then sort them with Selection Sort:

In the first step, the first and last elements are swapped. Thus the element "TWO" ends up behind the element "two" – the order of both elements is swapped.
In the second step, the algorithm compares the two rear elements. Both have the same key, 2. So no element is swapped.
In the third step, only one element remains; this is automatically considered sorted.
The two elements with the key 2 have thus been swapped to their initial order – the algorithm is unstable.
Stable Variant of Selection Sort
Selection Sort can be made stable by not swapping the smallest element with the first in step two, but by shifting all elements between the first and the smallest element one position to the right and inserting the smallest element at the beginning.
Even though the time complexity will remain the same due to this change, the additional shifts will lead to significant performance degradation, at least when we sort an array.
With a linked list, cutting and pasting the element to be sorted could be done without any significant performance loss.
Parallelizability of Selection Sort
We cannot parallelize the outer loop because it changes the contents of the array in every iteration.
The inner loop (search for the smallest element) can be parallelized by dividing the array, searching for the smallest element in each sub-array in parallel, and merging the intermediate results.
Selection Sort vs. Insertion Sort
Which algorithm is faster, Selection Sort, or Insertion Sort?
Let's compare the measurements from my Java implementations.
I leave out the best case. With Insertion Sort, the best case time complexity is O(n) and took less than a millisecond for up to 524,288 elements. So in the best case, Insertion Sort is, for any number of elements, orders of magnitude faster than Selection Sort.
| n | Selection Sort unsorted | Insertion Sort unsorted | Selection Sort descending | Insertion Sort descending |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 16.384 | 27,9 ms | 21,9 ms | 65,6 ms | 43,6 ms |
| 32.768 | 108,0 ms | 87,9 ms | 265,4 ms | 175,8 ms |
| 65.536 | 434,0 ms | 350,4 ms | 1.052,2 ms | 697,6 ms |
| 131.072 | 1.729,8 ms | 1.398,9 ms | 4.209,9 ms | 2.840,0 ms |
| 262.144 | 6.913,4 ms | 5.706,8 ms | 16.863,7 ms | 11.517,4 ms |
| 524.288 | 27.649,8 ms | 23.009,7 ms | 67.537,8 ms | 46.309,3 ms |
And once again as a diagram:

Insertion Sort is, therefore, not only faster than Selection Sort in the best case but also the average and worst case.
The reason for this is that Insertion Sort requires, on average, half as many comparisons. As a reminder, with Insertion Sort, we have comparisons and shifts averaging up to half of the sorted elements; with Selection Sort, we have to search for the smallest element in all unsorted elements in each step.
Selection Sort has significantly fewer write operations, so Selection Sort can be faster when writing operations are expensive. This is not the case with sequential writes to arrays, as these are mostly done in the CPU cache.
In practice, Selection Sort is, therefore, almost never used.
Summary
Selection Sort is an easy-to-implement, and in its typical implementation unstable, sorting algorithm with an average, best-case, and worst-case time complexity of O(n²).
Selection Sort is slower than Insertion Sort, which is why it is rarely used in practice.
You will find more sorting algorithms in this overview of all sorting algorithms and their characteristics in the first part of the article series.