


Java 26 Features
(mit Beispielen)
Java 26 befindet sich seit dem 4. Dezember 2025 in der sogenannten „Rampdown Phase One”, d. h. es werden keine weiteren JDK Enhancement Proposals (JEPs) in das Release aufgenommen. Das Feature-Set steht also fest. Es werden nur noch Bugs gefixt und ggf. kleinere Verbesserungen durchgeführt.
Als Veröffentlichungsdatum ist der 17. März 2026 angepeilt. Die aktuelle Early-Access-Version kannst du hier herunterladen.
Java 26 gehört mit 10 gelieferten JDK Enhancement Proposals (JEPs) zu den überschaubareren Releases der letzten Jahre. Die Hälfte der JEPs sind kleinere bis mittelgroße Änderungen – wie Warnungen bei der Mutation von finalen Feldern und die Unterstützung von HTTP/3.
Die andere Hälfte sind wiedervorgelegte Previews – also Aktualisierungen von bereits vorgestellten, aber noch nicht finalisierten Features. Bis auf bei Lazy Constants (zuvor bekannt als Stable Values) gab es hier nur minimale Änderungen.
Für alle JEPs und Änderungen aus den Release Notes verwende ich wie immer die originalen, englischen Bezeichnungen.
Prepare to Make Final Mean Final – JEP 500
Die meisten Entwickler:innen gehen davon aus, dass ein Feld, das wir als final kennzeichnen, nicht veränderbar ist. Tatsächlich können wir einem final-Feld auch nicht einfach per Gleich-Zeichen einen neuen Wert zuweisen. Allerdings erlaubt es uns die sogenannte Deep Reflection, diese Einschränkung zu umgehen.
Hier eine kleine Beispielklasse, der wir im Konstruktor einen Wert übergeben, der dann in dem finalen Feld value gespeichert wird:
public class Box {
private final Object value;
public Box(Object value) {
this.value = value;
}
@Override
public String toString() {
return "Box{value=" + value + "}";
}
}Code-Sprache: Java (java)Der folgende Code zeigt, wie sich der Inhalt des finalen Feldes kinderleicht – sogar von außerhalb des Objekts – ändern lässt:
Box box = new Box("Rubic's Cube");
IO.println("box = " + box);
Field valueField = Box.class.getDeclaredField("value");
valueField.setAccessible(true);
valueField.set(box, "Magic Wand");
IO.println("box = " + box);Code-Sprache: Java (java)Wir umgehen hier sowohl die Kapselung des Feldes per private als auch die Unveränderlichkeit via final. Und dieser Code lässt sich von beliebiger Stelle aus ausführen, beispielsweise auch von Drittanbieter-Libraries, von denen wir nicht mal wissen, dass sie auf dem Classpath liegen.
Dieses Problem wurde bereits vor Jahren erkannt, und daher wurde bei Hidden Classes in Java 15 und bei Records in Java 16 von Beginn an Deep Reflection gar nicht erst erlaubt.
Zudem kam ebenfalls in Java 16 die „Strong Encapsulation“ für JDK-Interna. Seitdem müssen wir Deep Reflection über Modulgrenzen hinweg explizit mit --add-opens erlauben. Das funktioniert bei eigenen Anwendungen aber nur, wenn diese auch das Modulsystem nutzen.
Um Java sicherer zu machen, soll die Modifkation finaler Felder per Deep Reflection in Zukunft grundsätzlich verboten werden – auch innerhalb eines Moduls.
Warnungen ab Java 26
In Java 26 werden durch JDK Enhancement Proposal 500 als ein erster Schritt Warnungen eingeführt. Der oben gezeigte Code lässt sich unter Java 25 anstandslos ausführen; unter Java 26 zeigt er nun folgende Warnung an:
WARNING: Final field value in class eu.happycoders.java26.jep500.Box has been mutated reflectively by class eu.happycoders.java26.jep500.FinalTest in unnamed module @3f99bd52
WARNING: Use --enable-final-field-mutation=ALL-UNNAMED to avoid a warning
WARNING: Mutating final fields will be blocked in a future release unless final field mutation is enabledCode-Sprache: Klartext (plaintext)Die Nutzung von Deep Reflection kann per --enable-final-field-mutation=<Modulname> explizit für bestimmte Module erlaubt – und damit die Warnung verhindert werden.
In einer zukünftigen Java-Version soll Deep Reflection dann standardmäßig verboten sein – statt einer Warnung wird es dann zu einer Exception kommen, sofern Deep Reflection nicht per --enable-final-field-mutation explizit erlaubt ist.
Das zukünftige Verhalten kann bereits jetzt durch die VM-Option --illegal-final-field-mutation eingeschaltet werden. Die Option bietet folgende Möglichkeiten:
--illegal-final-field-mutation=allow | Finale Felder können ohne Warnung verändert werden (Standardverhalten vor Java 26). |
--illegal-final-field-mutation=warn | Beim erstmaligen Ändern eines finalen Feldes erscheint eine Warnung (Standardverhalten ab Java 26). |
--illegal-final-field-mutation=debug | Bei jedem Ändern eines finalen Feldes erscheint eine Warnung. |
--illegal-final-field-mutation=deny | Finale Felder dürfen nicht geändert werden – der Versuch führt zu einer IllegalAccessException. |
In einer zukünftigen Java-Version wird deny zur Standardeinstellung werden, und allow wird nicht mehr erlaubt sein. Dann muss Deep Reflection auf Modulebene per --enable-final-field-mutation aktiviert werden.
Die Garantie, dass finale Felder wirklich final sind, schützt übrigens nicht nur vor unerwartetem Verhalten, sondern sie verbessert auch die Performance einer Anwendung: Wenn die JVM weiß, dass ein Feld nicht verändert werden kann, dann kann es den Zugriff darauf per Constant Folding – eine Art Inlining für Konstanten – optimieren.
Ahead-of-Time Object Caching with Any GC – JEP 516
In Java 24 wurde Ahead-of-Time Class Loading & Linking eingeführt – die Möglichkeit, die von einer Anwendung benötigten Klassen in einem architekturspezifischen Binärformat in einem sogenannten Ahead-of-Time-Cache zu speichern – und aus diesem zu laden, um den Start von Anwendungen deutlich zu beschleunigen (in Tests um bis zu 42 %).
Bisher wurden die Klassen exakt so im Cache gespeichert, wie sie der Garbage Collector auf dem Heap ablegt, einschließlich Header ud Referenzen auf andere Objekte (z. B. von Class-Objekten auf Strings). Dies hat den Vorteil, dass die Ahead-of-Time-Cache-Datei direkt vom Dateisystem in den Heap gemappt werden kann – und das geschieht nahezu ohne Zeitverlust, wenn die Ahead-of-Time-Cache-Datei im Dateisystem-Cache liegt.
Allerdings kann sich die Binärdarstellung sowohl der Objekt-Header als auch der Referenzen von Garbage Collector zu Garbage Collector oder abhängig von VM-Optionen unterscheiden:
- Bei Compressed OOPs (Standard bei Heaps bis maximal 32 GB) sind die Referenzen 32 Bit lang.
- Ohne Compressed OOPs (bei einem Heap größer als 32 GB oder mit der VM-Option
-XX:-UseCompressedOOPs) sind sie 64 Bit lang. - ZGC verwendet einige Bits der Referenzen für Metadaten.
- Durch die Aktivierung von Compact Object Headers (
-XX:+UseCompactObjectHeaders) oder die Deaktivierung von Compressed Class Pointers (deprecated seit Java 25) ändert sich das Binärformat des Headers.
Deshalb konnte bisher ein Ahead-of-Time-Cache, der mit dem G1, dem Serial GC oder dem Parallel GC erzeugt wurde, nicht von Anwendungen gelesen werden, die den ZGC nutzen – und vice versa. Ebenso konnte ein Cache, der mit aktivierten Compressed OOPs oder Compact Object Headers erzeugt wurde, nicht von einer Anwendung gelesen werden, bei denen Compressed OOPs oder Compact Object Headers ausgeschaltet sind – und vice versa.
GC-unabhängiger Ahead-of-Time-Cache
Um den Ahead-of-Time-Cache flexibler nutzen zu können, können wir ab Java 26 einen GC-unabhängigen Ahead-of-Time-Cache erzeugen. Dabei werden die Objekte in der Cache-Datei über ihren Index innerhalb des Caches referenziert. Die Cache-Datei kann so nicht mehr direkt in den Heap gemappt werden. Stattdessen werden die Objekte nach und nach aus der Datei gelesen und dann im GC-spezifischen Format auf dem Heap gespeichert und dort korrekt verlinkt – oder anders ausgedrückt: Sie werden aus der Cache-Datei in den Heap gestreamt.
Das GC-unabhängige Format (auch „Streamable Objects“ genannt) wird verwendet, wenn im Trainingslauf...
- ZGC verwendet wurde – oder
- Compressed OOPs mit
-XX:-CompressedOopsdeaktiviert wurden – oder - der Heap größer war als 32 GB – oder
- die VM-Option
-XX:+AOTStreamableObjectsangegeben wurde.
Wenn hingegen eine Anwendung mit dem G1, dem Serial GC oder dem Parallel GC und einem Heap von maximal 32 GB gestartet wurde, wird das bisherige, GC-spezifische Format verwendet.
HTTP/3 for the HTTP Client API – JEP 517
Das nächste Feature wird bereits durch die Überschrift vollständig erklärt: Die HttpClient-API unterstützt ab Java 26 Version 3 des HTTP-Protokolls (eingeführt im Jahr 2022).
Mit der HttpClient-API könntest du z. B. wie folgt den Inhalt meiner Homepage laden und in einem String speichern:
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.happycoders.eu/"))
.build();
HttpResponse<String> response =
client.send(request, BodyHandlers.ofString());
String responseBody = response.body();Code-Sprache: Java (java)Standardmäßig wurde hier bisher HTTP/2 verwendet – und daran ändert sich auch mit Java 26 nichts, da erst ca. ein Drittel aller Webseiten HTTP/3 unterstützen.
Du kannst nun allerdings HTTP/3 explizit wie folgt aktivieren:
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.happycoders.eu/"))
.version(HttpClient.Version.HTTP_3) // ← Try to use HTTP/3
.build();Code-Sprache: Java (java)Somit wird versucht mit dem Server über HTTP/3 zu kommunizieren. Sollte der Server kein HTTP/3 unterstützen, wird transparent auf HTTP/2 umgeschaltet.
G1 GC: Improve Throughput by Reducing Synchronization – JEP 522
G1 ist der Standard-Garbage-Collector der JVM – er bietet ein ausgewogenes Verhältnis aus hohem Durchsatz und kurzen Latenzen (im Gegensatz dazu sind der Serial GC und der Parallel GC auf höchstmöglichen Durchsatz ausgelegt und ZGC und Shenandoah auf niedrigstmögliche Latenzen).
Wenn der Garbage Collector ein Objekt verschiebt, dann muss er auch alle Referenzen auf dieses Objekt anpassen. Dafür den gesamten Heap zu scannen wäre sehr ineffizient. Daher scannt G1 nur die Objekte innerhalb einer Region (zur Erinnerung: G1 teilt den Heap in ca. 2.048 Regionen auf) – Referenzen von einer Region in eine andere hingegen werden in einer separaten, effizienten Datenstruktur namens Card Table gespeichert. Diese kann G1 besonders schnell durchsuchen.
Wie erfährt G1, dass der Anwendungscode eine Referenz von einem Objekt auf ein anderes gesetzt hat, welche zusätzlich in der Card Table gespeichert werden muss? Durch sogenannte Write Barriers: kurze Stücke von Maschinencode, die G1 beim Start einer Anwendung in den Code einwebt.
Damit das Scannen der Card Table nach dem Verschieben eines Objekts möglichst schnell erfolgt, optimiert G1 die Card Table kontinuierlich im Hintergrund. Da G1 parallel zur Anwendung läuft, muss der Zugriff auf die Card Table von den Anwendungsthreads über die Write Barriers und der Zugriff durch den Optimierungsthread synchronisiert werden. Das wiederum stellt einen nicht unerheblichen Overhead dar.
Reduzierung des Synchronisations-Overheads in Java 26
Deshalb wird G1 in Java 26 wie folgt optimiert:
Es wird eine zweite Card Table eingeführt. Während die Anwendungsthreads auf eine dieser zwei Card Tables zugreifen, optimiert der Optimierungsthread die jeweils andere. Sobald eine Card Table durch die Anwendungsthreads so stark modifiziert wurde, dass die Zeit für das Scannen dieser Card Table eine gewisse Grenze überschreitet, werden die Card Tables getauscht. Der Anwendungsthread greift dann auf die zuvor optimierte Card Table zu, während der Optimierungsthread die schwerfällig gewordene Card Table wieder optimiert.
Der Optimierungsthread muss somit nicht mit der parallel laufenden Anwendung synchronisiert werden. Der so reduzierte Synchronisationsoverhead kann zu einer Erhöhung des Gesamtdurchsatzes um 5 bis 15 % führen. Die Kosten dafür sind minimal: eine Card Table belegt 0,2 % des Heaps – entsprechend werden bei gleichbleibender Heap-Größe lediglich 0,2 % mehr nativer Arbeitsspeicher benötigt.
Diese Optimierung greift nach einem Upgrade auf Java 26 ohne jegliche Codeänderung oder Anpassung von VM-Parametern.
Wiedervorgelegte Preview- und Incubator-Features
Keines der fünf Features, die sich in Java 25 im Preview- bzw. Incubator-Stadium befanden, wurde in Java 26 wurde finalisiert. Alle fünf Features wurden mit kleinen oder größeren Änderungen wiedervorgelegt. In den folgenden Abschnitten werden die Features mit Fokus auf die Änderungen gegenüber Java 25 beschrieben.
PEM Encodings of Cryptographic Objects (Second Preview) – JEP 524
PEM steht für Privacy-Enhanced Mail und stellt ein Kodierungsschema für kryptografische Objekte dar. Du hast sicher schon mal PEM-kodierte Objekte gesehen – wie z. B. das folgende PEM-kodierte kryptografische Zertifikat:
-----BEGIN CERTIFICATE-----
MIIDtzCCAz2gAwIBAgISBUCeYELtjMmr4FAIqHapebbFMAoGCCqGSM49BAMDMDIx
CzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQDEwJF
. . .
DBeMde1YpWNXpF9+B/OMKgn7RgXRj5b2QpBCnFsP92T4cK/Nn+xFIjYCMCCx4E79
toSQBlYnNHv0eXnWkI8TmXsU/A6rU4Gxdr9GbGixgRJvkw0C6zjL/lH2Vg==
-----END CERTIFICATE-----Code-Sprache: Klartext (plaintext)PEM-kodierte Objekte in Java zu schreiben oder zu lesen war bisher äußerst kompliziert und erforderte über ein Dutzend Zeilen Code. Das folgende Beispiel zeigt, was man alles schreiben musste, um einen PEM-kodierten privaten Schlüssel in Java zu lesen:
String encryptedPrivateKeyPemEncoded = . . .
String passphrase = . . .
String encryptedPrivateKeyBase64Encoded = encryptedPrivateKeyPemEncoded
.replace("-----BEGIN ENCRYPTED PRIVATE KEY-----", "")
.replace("-----END ENCRYPTED PRIVATE KEY-----", "")
.replaceAll("[\\r\\n]", "");
Base64.Decoder decoder = Base64.getDecoder();
byte[] encryptedPrivateKeyBytes = decoder.decode(encryptedPrivateKeyBase64Encoded);
EncryptedPrivateKeyInfo encryptedPrivateKeyInfo =
new EncryptedPrivateKeyInfo(encryptedPrivateKeyBytes);
String algorithmName = encryptedPrivateKeyInfo.getAlgName();
SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithmName);
PBEKeySpec pbeKeySpec = new PBEKeySpec(passphrase.toCharArray());
Key pbeKey = secretKeyFactory.generateSecret(pbeKeySpec);
Cipher cipher = Cipher.getInstance(algorithmName);
AlgorithmParameters algParams = encryptedPrivateKeyInfo.getAlgParameters();
cipher.init(Cipher.DECRYPT_MODE, pbeKey, algParams);
KeyFactory rsaKeyFactory = KeyFactory.getInstance("RSA");
KeySpec keySpec = encryptedPrivateKeyInfo.getKeySpec(cipher);
PrivateKey privateKey = rsaKeyFactory.generatePrivate(keySpec);Code-Sprache: Java (java)In Java 25 wurde als Preview-Feature eine eigene PEM-API eingeführt, die den Umgang mit PEM-kodierten Objekten deutlich vereinfachen soll. Das Lesen des verschlüsselten Private Keys ist so mit nur wenigen Zeilen Code möglich (oder nur einer, wenn man alles in eine Zeile schreibt):
PrivateKey privateKey = PEMDecoder.of()
.withDecryption(passphrase.toCharArray())
.decode(encryptedPrivateKeyPemEncoded, PrivateKey.class);Code-Sprache: Java (java)Neben dem oben gezeigten PEMDecoder gibt es einen entsprechenden PEMEncoder mit einer encode()-Methode.
In Java 26 bleibt die grundsätzliche Funktionsweise dieser API gleich – es wurden nur einige Details verändert und der Funktionsumfang etwas erhöht:
- Es wurden einige Klassen und Methoden umbenannt sowie einige Methoden hinzugefügt (von diesen Änderungen war das simple Beispiel oben nicht betroffen).
- Es wurden einige Exceptions angepasst.
- Zusätzlich zu den bisherigen kryptografischen Objekten können nun auch Schlüsselpaare sowie PKCS#8-kodierte Schlüssel kodiert und dekodiert werden.
Mehr Details zur neuen API und zu diesen Änderungen findest du in JDK Enhancement Proposal 524.
Structured Concurrency (Sixth Preview) – JEP 525
Structured Concurrency befindet sich bereits in der sechsten Preview-Runde. Wenn du die API bereits kennst und nur wissen möchtest, was sich in Java 26 geändert hat, kannst du zum Abschnitt Structured Concurrency – Änderungen in Java 26 springen.
Was ist Structured Concurrency?
Structured Concurrency bedeutet – im Gegensatz zu Unstructured Concurrency und angelehnt an die Strukturierte Programmierung –, dass die Ausführungspfade, die beim Starten nebenläufiger Threads erzeugt werden, an einem einzigen Punkt im Code wieder zusammenlaufen – und dass garantiert ist, dass an diesem Punkt keine verwaisten Threads mehr ausgeführt werden.
Die folgende Grafik soll das demonstrieren. Sie zeigt zudem, dass sich durch Structured Concurrency aufgespannte „Scopes“ (= die Bereiche, in denen nebenläufige Tasks ausgeführt werden) – ineinander schachteln lassen:

Dies war bisher – in eingeschränktem Umfang – auch mit einem ExecutorService und dem Aufruf von close() bzw. shutdown() und awaitTermination() möglich. Die Java-API für die Structured Concurrency, StructuredTaskScope, bietet jedoch zusätzliche Möglichkeiten, um einen Scope beim Eintritt bestimmter Ereignisse vorzeitig zu beenden und alle noch laufenden Tasks abzubrechen. Das war bei einem ExecutorService nur mit einem äußerst komplexen und dementsprechend fehleranfälligen Orchestrierungsaufwand möglich.
StructuredTaskScope API
Das folgende Beispiel zeigt, wie sich mit der StructuredTaskScope-API mehrere Subtasks parallel starten lassen und dann auf das Ergebnis aller Subtasks gewartet wird. Sollte einer der Subtasks fehlschlagen, werden die noch laufenden Subtasks abgebrochen, und scope.join() wirft die Exception, die in dem fehlgeschlagenen Subtask aufgetreten ist.
Invoice createInvoice(int orderId, int customerId, String language)
throws InterruptedException {
try (var scope = StructuredTaskScope.open()) {
var orderTask = scope.fork(() -> orderService.getOrder(orderId));
var customerTask = scope.fork(() -> customerService.getCustomer(customerId));
var templateTask = scope.fork(() -> templateService.getTemplate(language));
scope.join();
var order = orderTask.get();
var customer = customerTask.get();
var template = templateTask.get();
return Invoice.generate(order, customer, template);
}
}Code-Sprache: Java (java)Das folgende Beispiel zeigt eine andere (durch Joiner.anySuccessfulOrThrow() aktivierte) Strategie: Hier wird nur das Ergebnis eines der Subtasks benötigt – und sobald dieses vorliegt, werden die anderen Subtasks abgebrochen:
AddressVerificationResponse verifyAddress(Address address) throws InterruptedException {
try (var scope = StructuredTaskScope.open(
Joiner.<AddressVerificationResponse>anySuccessfulOrThrow())) {
scope.fork(() -> verificationService.verifyViaServiceA(address));
scope.fork(() -> verificationService.verifyViaServiceB(address));
scope.fork(() -> verificationService.verifyViaServiceC(address));
return scope.join();
}
}Code-Sprache: Java (java)Das hier verwendete Joiner-Interface stellt noch weitere Strategien zur Verfügung. Welche das sind und wie du darüberhinaus eigene Strategien implementieren kannst, erfährst du im Hauptartikel über Structured Concurrency in Java.
Structured Concurrency – Änderungen in Java 26
Structured Concurrency wurde erstmals in Java 21 vorgestellt. In Java 25 wurde die API grundlegend überarbeitet (Stichwort: „Composition over Inheritance“). In Java 26 wurden durch JDK Enhancement Proposal 525 folgende Erweiterungen und Anpassungen durchgeführt:
- Das
Joiner-Interface hat nebenonFork()undonComplete()eine zusätzliche MethodeonTimeout()bekommen. Diese wird im Fall eines Timeouts vonStructuredTaskScope.join()aufgerufen und wirft standardmäßig eineTimeoutException. Sie kann aber in einem eigenen Joiner überschrieben werden, um Timeouts alternativ zu behandeln – z. B. um einen bestimmten Wert zurückzuliefern. - Der durch
Joiner.allSuccessfulOrThrow()erzeugte Joiner liefert nicht mehr einen Stream von Subtasks zurück (die ja ohnehin alle erfolgreich sind), sondern eine Liste der Ergebnisse der Subtasks. - Der durch
Joiner.allUntil(...)erzeugte Joiner liefert statt eines Streams von Subtasks eine Liste von Subtasks. - Die Methode
Joiner.anySuccessfulResultOrThrow()wurde inanySuccessfulOrThrow()umbenannt (das WortResultwurde gestrichen, da es auch in den anderenJoiner-Factory-Methoden nicht verwendet wird). - Es gibt eine überladene
StructuredTaskScope.open(...)-Methode, mit der die Konfiguration eines Joiners angepasst werden kann. In dieser wurde der Typ für den Konfigurationsparameter vonFunction<Configuration, Configuration>aufUnaryOperator<Configuration>geändert (was letztendlich ja wiederum eineFunction<Configuration, Configuration>ist).
Code der mit Java 25 geschrieben wurde, erfordert also nur kleinere (oder gar keine) Anpassungen, um auf Java 26 zu laufen.
Lazy Constants (Second Preview) – JEP 526
Lazy Constants wurden in Java 25 als Stable Values eingeführt. Wenn du dich mit Stable Values bereits beschäftigt hast und nur an den Änderungen in Java 26 interessiert bist, kannst du zum Abschnitt Lazy Constants – Änderungen in Java 26 springen.
Welches Problem wollen wir lösen?
Konstanten – also unveränderliche Werte – habe viele Vorteile: Sie machen den Code einfacherer und sicherer, da sie nur in einem Zustand sein können und da auf sie sicher aus mehreren Threads zugegriffen werden kann. Zudem ermöglichen sie Performance-Optimierungen durch die JVM, z. B. durch (das oben bei finalen Feldern bereits erwähnte) Constant Folding.
Konstanten können bisher nur durch finale Felder definiert werden:
- finale statische Felder, die beim Laden einer Klasse initialisiert werden – oder
- finale Instanzfelder, die beim Erzeugen eines Objekts initialisiert werden.
Möchte man einen unveränderlichen Wert erst bei Bedarf initialisieren, z. B. weil die Initialisierung aufwändig ist, muss man das Konzept der „Lazy Initialization“ einsetzen. Um Lazy Initialization in Java threadsicher zu gestalten, mussten wir bisher entweder auf das Double-Checked-Locking-Idiom oder das Initialization-on-Demand-Holder-Idiom zurückgreifen. Wer das schon einmal gemacht hat, weiß, dass sich dabei leicht Fehler einschleichen können.
Lazy Constants API
In Java 25 wurde die Stable-Values-API vorgestellt, um Lazy Initialization zu vereinfachen. Nach umfangreichem Feedback wurde die API in Java 26 durch JDK Enhancement Proposal 526 stark vereinfacht und in Lazy Constants umbenannt.
Das folgende Beispiel zeigt, wie wir eine LazyConstant definieren, die erst beim ersten Zugriff darauf ein Settings-Objekt durch Laden aus einer Datenbank initialisiert:
private final LazyConstant<Settings> settings =
LazyConstant.of(this::loadSettingsFromDatabase);
public Locale getLocale() {
return settings.get().getLocale(); // ⟵ Here we access the lazy constant
}Code-Sprache: Java (java)Nur beim ersten Aufruf von settings.get() wird die loadSettingsFromDatabase()-Methode aufgerufen. Dabei wird der Wert in dem LazyConstant-Objekt gespeichert, und weitere Aufrufe von settings.get() liefern diesen gespeicherten Wert zurück. Auch die Threadsicherheit wird garantiert: Sollte settings.get() aus mehreren Threads gleichzeitig aufgerufen werden, wird loadSettingsFromDatabase() dennoch maximal einmal aufgerufen.
Sobald die LazyConstant initialisiert ist, wird sie von der JVM als unveränderlich interpretiert und der Zugriff darauf durch Constant Folding optimiert.
Lazy Lists
Neben einzelnen Lazy Constants können wir auch Lazy Lists definieren – Listen, bei denen jedes Element eine Lazy Constant ist. Das folgende Beispiel zeigt eine einfache Lazy List, in der jedes Feld lazily mit der Quadratwurzel des Feld-Indexes initialisiert wird:
private final List<Double> squareRoots = List.ofLazy(100, Math::sqrt);Code-Sprache: Java (java)Auch hier erfolgt die Initialisierung erst beim ersten Zugriff – und zwar separat für jedes Element der Liste, z. B. beim direkten Zugriff mit get(int index) – oder bei der Iteration über die Liste. Und auch hier ist die Initialisierung threadsicher, und die Werte werden nach der Initialisierung durch die JVM wie Konstanten behandelt und optimiert.
Lazy Maps
Auch Maps lassen sich in Zukunft lazily initialisieren. Das folgende Beispiel zeigt eine Lazy Map, bei der Locales auf ResourceBundles gemappt werden:
Set<Locale> supportedLocales = getSupportedLocales();
Map<Locale, ResourceBundle> resourceBundles =
Map.ofLazy(supportedLocales, this::loadResourceBundle);Code-Sprache: Java (java)Beim ersten Zugriff auf ein Map-Element für eine bestimmte Locale wird das zugehörige ResourceBundle über loadResourceBundle() geladen und dann in der Map als Konstante gespeichert. Genau wie Lazy Constants und Lazy Lists sind auch Lazy Maps threadsicher.
Lazy Constants – Änderungen in Java 26
Neben der offensichtlichen Änderung – der Umbenennung in Lazy Constants – wurden in Java 26 folgende Vereinfachungen durchgeführt:
- Low-Level-Methoden wie
orElseSet(),setOrThrow()undtrySet()wurden entfernt, da diese die API unnötig kompliziert machten. - Lazy Lists und Lazy Maps wurden zuvor über
StableValue.list(...)undStableValue.map(...)erzeugt. Diese Factory-Methoden wurden in dasList- bzw.Map-Interface verschoben. - Die über
StableValue.function(...)bzw.StableValue.intFunction(...)erzeugtenFunction- undIntFunction-Implementierungen wurden ersatzlos gestrichen, da sie keinen Mehrwert gegenüber Lazy Lists und Lazy Maps darstellten. - Aus Performance-Gründen dürfen Lazy Constants, Lazy Lists und Lazy Maps keine
null-Werte mehr enthalten. Wenn die Berechnungsfunktionnullzurückliefert, wird eineNullPointerExceptiongeworfen.
Solltest du in Java 25 also bereits auf Stable Values gesetzt haben, wird ein umfangreiches Refactoring erforderlich sein.
Vector API (Eleventh Incubator) – JEP 529
Und nun kommen wir – zum mittlerweile elften Mal – zur Vector API.
Mit der Vector API lassen sich mathematische Vektoroperationen mit den Vektor-Instruktionssätzen moderner CPUs (wie SSE und AVX) besonders effizient berechnen – z. B. eine Vektor-Addition wie die folgende:
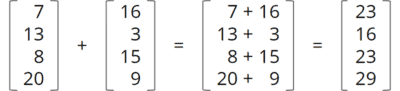
Als Java-Code würde diese Operation wie folgt implementiert werden, wobei a und b die Eingabe-Vektoren sind und c der Ausgabe-Vektor:
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void addVectors(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.add(vb);
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}Code-Sprache: Java (java)Hier ist aktuell noch ziemlich viel Boilerplate notwendig für so eine einfache Operation:
- Über
SPECIES.length()wird abgefragt, wie viele Vektor-Elemente in einem CPU-Zyklus gleichzeitig verarbeitet werden können. SPECIES.loopBound(...)berechnet, in wie viele vollständige Teilvektoren dieser Länge der Ausgangsvektor aufgesplittet werden kann.- Über die erste Schleife werden alle Teilvektoren addiert.
- Wenn die Länge des Ausgangsvektors kein Vielfaches der Teilvektorenlänge ist, verbleibt ein Rest. Dessen Elemente werden über die zweite Schleife einzeln addiert.
Ich bin gespannt, ob die API noch vereinfacht wird, nachdem sie das Preview-Stadium erreicht hat.
Dazu müssen wir uns allerdings noch gedulden, bis der ersten JEP aus Project Valhalla – JEP 401: Value Classes and Objects das Preview-Stadium erreicht hat. Denn die Vector-Klasse soll von Anfang an eine Value Class sein – also eine Klasse, deren Objekte ohne Identität auskommen werden.
Wann wird es soweit sein? Brian Goetz, Language Architekt bei Oracle, beantwortet die Frage nach dem Erscheinungsdatum von Project Valhalla seit Jahren konsequent mit: „It’s ready when it’s ready“ – eine konkretere Aussage ließ er sich bisher nicht entlocken. Am 10. Oktober 2025 wurde der Java-Community endlich ein erstes Early-Access Build von Projekt Valhalla zur Verfügung gestellt.
Die elfte Incubator-Version der Vector API wird in JDK Enhancement Proposal 529 beschrieben: Es gibt keine substanziellen Änderungen gegenüber der vorherigen Version.
Primitive Types in Patterns, instanceof, and switch (Fourth Preview) – JEP 530
Pattern Matching mit primitiven Typen wurde erstmals in Java 23 als Preview-Feature vorgestellt. Seither gab es keine grundlegenden Änderungen. Wenn du mit dem Feature bereits vertraut bist und dich für die kleinen Verfeinerungen in Java 26 interessierst, springe gerne zum Abschnitt Primitive Types in Patterns – Änderungen in Java 26.
Pattern Matching und switch mit primitiven Typen – Status Quo
Pattern Matching ist bisher auf Referenztypen beschränkt, beispielsweise wie folgt:
Object obj = . . .
switch (obj) {
case String s when s.length() >= 5 -> IO.println(s.toUpperCase());
case Integer i -> IO.println(i * i);
case null, default -> IO.println(obj);
}Code-Sprache: Java (java)Ein switch über primitive Typen ist zwar möglich – allerdings nur mit byte, short, char und int – und in den case-Labels sind nur Konstanten erlaubt:
int code = . . .
switch (code) {
case 200 -> IO.println("OK");
case 404 -> IO.println("Not Found");
}Code-Sprache: Java (java)Pattern Matching und switch mit primitiven Typen – Was wird sich ändern?
In Zukunft sollen im switch alle primitiven Typen erlaubt sein, also auch long, double, float und sogar boolean. Und in den case-Labels sollen auch Patterns erlaubt sein. Damit könnten wir dann z. B. einen int-Wert auf bestimmte Zahlenbereiche prüfen:
int code = . . .
switch (code) {
case int i when i >= 100 && i < 200 -> IO.println("information");
case int i when i >= 200 && i < 300 -> IO.println("success");
case int i when i >= 300 && i < 400 -> IO.println("redirection");
case int i when i >= 400 && i < 500 -> IO.println("client error");
case int i when i >= 500 && i < 600 -> IO.println("server error");
default -> throw new IllegalArgumentException();
}Code-Sprache: Java (java)Pattern mit Referenztypen matchen auch auf abgeleitete Typen, z. B. würde ein case Number n auch auf ein Objekt vom Typ Integer matchen. Bei primitiven Typen gibt es keine Vererbung – daher haben sich die JDK-Developer hier etwas anderes überlegt:
Wir können in Zukunft mit switch (und genauso mit instanceof) prüfen, ob sich der Wert einer primitiven Variablen ohne Präzisionsverlust mit einem anderen primitiven Typen darstellen lässt:
double value = . . .
switch (value) {
case byte b -> IO.println(value + " instanceof byte: " + b);
case short s -> IO.println(value + " instanceof short: " + s);
case char c -> IO.println(value + " instanceof char: " + c);
case int i -> IO.println(value + " instanceof int: " + i);
case long l -> IO.println(value + " instanceof long: " + l);
case float f -> IO.println(value + " instanceof float: " + f);
case double d -> IO.println(value + " instanceof double: " + d);
}Code-Sprache: Java (java)Wenn hier value z. B. 42 wäre, dann würde das Pattern byte b matchen, da sich 42 auch in einem byte speichern lässt. Wäre value z. B. 50.000, dann würde das Pattern char c matchen. Für 65.000 würde int i matchen, für 0,5 float f und für 0,7 erst double d.
Auch bei primitiven Typen gilt das Dominanzprinzip: Die Reihenfolge der case-Labels im vorherigen Beispiel darf nicht verändert werden, da dann einzelne case-Labels nicht mehr erreichbar wären. Beispielsweise dürfte das Pattern int i nicht vor byte b erscheinen, da jedes mögliche Byte bereits auf int i matchen würde.
Primitive Types in Patterns – Änderungen in Java 26
Durch JDK Enhancement Proposal 530 wurde in Java 26 hauptsächlich die Dominanzprüfung verbessert. Der folgende Code beispielsweise lässt sich mit Java 25 noch fehlerfrei compilieren:
int i1 = . . .
switch (i1) {
case float f -> {}
case 16_777_216 -> {}
default -> {}
}
int i2 = . . .
switch (i2) {
case int _ -> {}
case float _ -> {}
}
byte b = . . .
switch (b) {
case short s -> {}
case 42 -> {}
}Code-Sprache: Java (java)In Java 26 hingegen werden alle drei switch-Statements mit Compilerfehlern quittiert:
- Im ersten
switchkann die Konstante 16.777.216 niemals matchen, da diese Zahl auch präzise mit einemfloatdargestellt werden kann und somit die Konstante durch das Patternfloat fdominiert wird. - Im zweiten
switchkann das Patternfloat fniemals matchen, da jeder Wert, deni2annehmen kann, brereits durch das Patternint _gematcht wird. - Im dritten
switchkann die Konsante 42 niemals matchen, da die 42 auch in einemshortgespeichert werden kann und somit die Konstante durch das Patternshort sdominiert wird.
Neben der verbesserten Dominanzprüfung gibt es in Java 26 keine Änderungen.
Deprecations und Löschungen
In Java 26 wurden die Applet-API sowie die Methode Thread.stop() entfernt. Details findest du in den folgenden zwei Abschnitten.
Remove the Applet API – JEP 504
Die Applet-API sowie der Security Manager, der für die Absicherung von Applets verantwortlich war, wurden in Java 9 im Jahr 2017 als deprecated markiert, da Applets zu der Zeit von keinem modernen Webbrowser mehr unterstützt wurden. In Java 17 wurden Applet-API und Security Manager als deprecated for removal markiert.
Der Security Manager wurde in Java 24 deaktiviert.
In Java 26 wurde nun die Applet-API – d. h. alle Klassen des Pakets java.applet sowie einige weitere, wie java.beans.AppletInitializer und javax.swing.JApplet – via JDK Enhancement Proposal 504 vollständig entfernt.
Thread.stop is removed
Thread.stop() wurde bereits in Java 1.2 – im Dezember 1998 – als deprecated markiert, weil es zu inkonsisten Zuständen und unvorhersehbarem Verhalten führen konnte. In Java 18 wurde es als deprecated for removal markiert, und seit Java 20 wirft es eine UnsupportedOperationException.
In Java 26 – also mehr als 27 Jahre nach der Markierung als deprecated – wird die Methode nun vollständig entfernt.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8368226 registriert.)
Sonstige Änderungen in Java 26
In diesem Abschnitt findest du eine Auswahl kleinerer Änderungen aus den Release Notes, für die keine JDK Enhancement Proposals geschrieben wurden.
Add Dark Theme to API Documentation
Dieses Feature ist schnell erklärt: an Java 26 bietet die Javadoc-Dokumentation einen Dark Mode an. Du kannst ihn bereits in der Early-Access-Dokumentation von 26 ausprobieren, indem du auf das Sonnen- bzw. Mondsymbol in der Menüleiste klickst.
Hier ein Eindruck vom neuen Modus:
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8342705 registriert.)
New ofFileChannel Method in java.net.http.HttpRequest.BodyPublishers
Um mit der HttpClient-API (verfügbar seit Java 11) eine Datei zu senden, musste diese bisher komplett in den RAM geladen und als Byte-Array an den HttpRequest übergeben werden:
byte[] fileContent = Files.readAllBytes(Path.of("test.bin"));
try (HttpClient client = HttpClient.newHttpClient()) {
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create("https://www.example.com/upload"))
.POST(BodyPublishers.ofByteArray(fileContent))
.build();
HttpResponse<Void> response =
client.send(request, HttpResponse.BodyHandlers.discarding());
}Code-Sprache: Java (java)Ab Java 26 kann eine Datei (oder ein Teil davon) auch per FileChannel in den HttpRequest gestreamt werden und muss so nicht mehr zuvor vollständig im Arbeitsspeicher bereitstehen. Das ist insbesondere bei sehr großen Dateien hilfreich:
try (FileChannel fileChannel =
FileChannel.open(Path.of("test.bin"), StandardOpenOption.READ);
HttpClient client = HttpClient.newHttpClient()) {
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create("https://www.example.com/upload"))
.POST(BodyPublishers.ofFileChannel(fileChannel, 0, fileChannel.size()))
.build();
HttpResponse<Void> response =
client.send(request, HttpResponse.BodyHandlers.discarding());
}Code-Sprache: Java (java)(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8329829 registriert.)
Default initial heap size is trimmed down
Wenn beim Start einer Java-Anwendung weder mit -Xms noch mit -XX:InitialRAMPercentage eine minimale Heap-Größe angegeben wird, wird der Heap standardmäßig auf 1/64 (= 1,5625 %) des physischen RAMs gesetzt. Heute haben Computer deutlich mehr RAM als noch vor zwanzig Jahren, so dass viele Anwendungen mit einem unnötig großen Heap ausgestattet werden. Auf meinem 64-GB-Laptop beispielsweise wird so selbst eine Hello-World-Anwendung mit einem 1-GB-Heap gestartet.
Neben dem unnötig belegten RAM kann das auch den Start einer Anwendung spürbar verzögern, da der Garbage Collector für den Heap initiale Datenstrukturen anlegen muss, die mit der Heap-Größe skalieren.
In Java 26 wird die initiale Heap-Größe standardmäßig auf 0,2 % geändert, also 1/500 des physischen RAMs. Auf meinem 64-GB-Laptop sind das immer noch für viele kleine Anwendungen ausreichende 128 MB.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8348278 registriert.)
Virtual threads now unmount when waiting for another thread to execute a class initializer
Unter bestimmten Umständen werden virtuelle Threads an ihren Carrier-Thread „gepinnt“, d. h. wenn der virtuelle Thread blockiert, kann dieser nicht von seinem Carrier-Thread (dem Betriebssystem-Thread, auf dem der virtuelle Thread ausgeführt wird) geunmounted werden. Somit ist auch der Carrier-Thread blockiert und kann keinen anderen virtuellen Thread ausführen.
Bereits in Java 24 wurde das schwerwiegende Problem des Pinnings innerhalb von synchronized-Blöcken behoben.
Vor Java 26 wurde ein virtueller Thread auch dann gepinnt, wenn er versucht, eine Klasse zu initialisieren, die gerade von einem anderen Thread initialisiert wird. Auch das passiert nun nicht mehr.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8369238 registriert.)
Support for Unicode 17.0
Java 26 erhöht die Unicode-Unterstützung auf Version 17.0.
Warum ist das relevant? Alle zeichenverarbeitenden Klassen wie String und Character müssen in der Lage sein, die in der neuen Unicode-Version eingeführten Zeichen und Codeblöcke zu verarbeiten.
(Für diese Änderung gibt es keinen JEP, sie ist im Bug-Tracker unter JDK-8346944 registriert.)
TODO 1: Nach Build 26 prüfen.
Vollständige Liste aller Änderungen in Java 26
In diesem Artikel haben ich alle JDK Enhancement Proposals vorgestellt, die ich Java 26 ausgeliefert wurden, sowie eine Auswahl von Änderungen aus den Release Notes. Die vollständige Liste aller Änderungen findest du in den Java 26 Release Notes.
Fazit
Im Vergleich zu den letzten zwei Java-Versionen fallen die Änderungen in Java 26 sehr übersichtlich aus:
- Bei der Mutation von finalen Feldern mit Deep Reflection wird nun eine Warnung ausgegeben – in Zukunft wird eine Exception geworfen.
- Das in Java 24 eingeführte Ahead-of-Time Class Loading & Linking funktioniert nun mit jedem Garbage Collector – nicht mehr nur mit dem G1.
- HttpClient unterstützt nun HTTP/3.
- Der G1 Garbage Collector wurde optimiert, was zu einer Erhöhung des Durchsatzes führt.
- Die Applet-API und
Thread.stop()wurden entfernt. - Stable Values wurden in Lazy Constants umgenannt – und die API wurde radikal vereinfacht.
- Bei den übrigen Features, die sich derzeit im Preview-Stadium befinden, wurden kleinere Verbesserungen vorgenommen.
Diverse sonstige Änderungen runden wie immer das Release ab. Das aktuelle Java 26 Early-Access Release kannst du hier herunterladen.
Welche der Änderungen findest du am spannendsten? Teile deine Meinung in den Kommentaren!