


Java 25 Features
(mit Beispielen)
Java 25 wurde am 16. September 2025 veröffentlich. Du kannst es hier herunterladen.
Meine Java-25-Highlights:
- Zwei Jahre nach virtuellen Threads sind nun auch Scoped Values ein produktives Feature. Mit Scoped Values können Daten über Methodenketten hinweg bereitgestellt werden, ohne sie als Parameter von Methode zu Methode übergeben zu müssen.
- Compact Source Files and Instance Main Methods: Für kleine Test- und Demoprogramme, wie man sie häufig beim Ausprobieren neuer Features schreibt, ist nun keine Klassendeklaration mehr erforderlich, und die Signatur der
main()-Methode wurde stark vereinfacht: mehr alsvoid main()ist nun nicht mehr nötig. - Mit Flexible Constructor Bodies dürfen wir ab sofort im Konstruktor Code vor dem Aufruf von
super()oderthis()ausführen. Das erlaubt es z. B. Parameter zu validieren oder zu berechnen, bevor der Super-Konstruktor aufgerufen wird. - Durch Compact Object Headers können Objekt-Header von 12 auf 8 Byte komprimiert werden. Insbesondere bei Anwendungen mit vielen kleinen Objekten spart das Speicherplatz und verbessert die Performance.
- Mit Stable Values (aktuell noch im Preview-Stadium) lassen sich Werte threadsicher beim ersten Zugriff darauf initialisieren – dann gelten sie als Konstanten und können durch die JVM wie finale Felder, z. B. durch Constant Folding, optimiert werden.
Für alle JEPs und Änderungen aus den Release Notes verwende ich wie immer die originalen, englischen Bezeichnungen.
Scoped Values – JEP 506
Mit Java 25 wird das zweite Feature aus „Project Loom“ (nach Virtuellen Threads) fertiggestellt: Nach mehreren Runden als Incubator- und Preview-Feature wurden nun auch Scoped Values finalisiert.
Scoped Values bieten eine elegante Möglichkeit, Daten über Methodenketten hinweg verfügbar zu machen, ohne sie als Parameter weitergeben zu müssen. Typisches Beispiel: In einer Webanwendung wird nach erfolgreicher Authentifizierung der eingeloggte User in einem Scoped Value hinterlegt. Alle nachfolgenden Methoden – egal wie tief im Call-Stack sie aufgerufen werden – können dann direkt auf dieses User-Objekt zugreifen:
public class Server {
public static final ScopedValue<User> LOGGED_IN_USER = ScopedValue.newInstance();
private void serve(Request request) {
User loggedInUser = authenticateUser(request);
ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.run(() -> restAdapter.processRequest(request));
}
}Code-Sprache: Java (java)Innerhalb des Aufrufs von restAdapter.processRequest(...) kann der eingeloggte User jederzeit über LOGGED_IN_USER.get() abgerufen werden – ganz ohne explizite Übergabe als Parameter. Der Mechanismus erinnert an ThreadLocal, hat aber mehrere Vorteile:
- Begrenzter Gültigkeitsbereich: Der Scope ist klar abgegrenzt und endet automatisch mit dem Ablauf von
run()odercall(). - Immutability: Der gespeicherte Wert kann – im Gegensatz zu
ThreadLocal– nicht verändert werden, was Race Conditions und unerwartete Seiteneffekte verhindert. - Niedrigerer Memory Footprint: Bei der Verwendung von
InheritableThreadLocalwerden Werte in Kind-Threads kopiert, damit Änderungen im Kind-Thread nicht den Eltern-Thread beeinflussen. Aufgrund der Immutability ist es bei Scoped Value nicht erforderlich, Werte zu kopieren.
Scoped Values wurden erstmals in Java 20 als Incubator-Feature vorgestellt. Mit Java 23 wurden sie um das generische Interface ScopedValue.CallableOp erweitert, das typsicheres Exception-Handling ermöglicht. In Java 24 sind die Convenience-Methoden callWhere() und runWhere() entfernt worden – zugunsten eines konsistenteren, fluenten Stils:
// Before Java 24:
Result result = ScopedValue.callWhere(LOGGED_IN_USER, loggedInUser,
() -> doSomethingSmart());
// Since Java 24:
Result result = ScopedValue.where(LOGGED_IN_USER, loggedInUser)
.call(() -> doSomethingSmart());Code-Sprache: Java (java)In Java 25 werden Scoped Values durch JDK Enhancement Proposal 506 finalisiert und können somit in Produktionscode eingesetzt werden.
Wenn du bisher ThreadLocal genutzt hast, lohnt sich ein Blick auf die neuen Möglichkeiten. Scoped Values bieten nicht nur bessere Lesbarkeit und Wartbarkeit, sondern passen auch perfekt zur neuen Welt der virtuellen Threads.
👉 Eine ausführliche Einführung findest du im Hauptartikel über Scoped Values.
Module Import Declarations – JEP 511
Nach zwei Runden als Preview in Java 23 und Java 24 wurden in Java 25 durch JDK Enhancement Proposal 511 auch Module Import Declarations finalisiert – ohne weitere Änderungen.
Was macht import module?
Seit Java 1.0 werden Klassen aus dem Paket java.lang automatisch verfügbar gemacht. Auch ganze Pakete konnten wir schon immer mit dem import-Statement einbinden. Was lange nicht möglich war: der Import ganzer Module. Genau das macht nun import module möglich.
Ein Modul-Import ermöglicht es dir, alle Klassen aus den exportierten Paketen eines Moduls zu verwenden:
import module java.base;
public static Map<Character, List<String>> groupByFirstLetter(String... values) {
return Stream.of(values).collect(
Collectors.groupingBy(s -> Character.toUpperCase(s.charAt(0))));
}Code-Sprache: Java (java)Im Beispiel oben musst du weder java.util.List noch java.util.stream.Collectors einzeln importieren – sie gehören alle zum java.base-Modul.
Wichtig: Du brauchst dafür keine module-info.java. Auch klassische Projekten ohne Module profitieren vom neuen Mechanismus.
Namenskonflikte bei mehrfach vorkommenden Klassen
Wenn zwei importierte Module eine Klasse mit identischem Namen bereitstellen, kann der Compiler nicht ohne weiteres wissen, welche benötigt wird. Ein Beispiel ist die Klasse Date – sie ist sowohl in java.base als auch in java.sql enthalten:
import module java.base;
import module java.sql;
// . . .
Date date = new Date(); // Compilerfehler: "reference to Date is ambiguous"Code-Sprache: Java (java)Die Lösung? Du gibst durch einen expliziten Klassennamen-Import an, welche Variante du nutzen möchtest:
import module java.base;
import module java.sql;
import java.util.Date; // ⟵ Das löst die Mehrdeutigkeit auf
// . . .
Date date = new Date();Code-Sprache: Java (java)Seit Java 24 kannst du solche Konflikte auch durch Paket-Importe auflösen:
import module java.base;
import module java.sql;
import java.util.*; // ⟵ Auch das löst die Mehrdeutigkeit auf
// . . .
Date date = new Date();Code-Sprache: Java (java)Transitive Modul-Abhängigkeiten
Ein großer Vorteil von import module liegt in der Unterstützung transitiver Abhängigkeiten: Wenn ein Modul ein anderes transitiv einbindet, sind dessen exportierte Pakete ebenfalls verfügbar – ganz ohne zusätzlichen Import.
Beispiel: java.sql deklariert eine transitive Abhängigkeit auf java.xml:
module java.sql {
requires transitive java.xml;
}Code-Sprache: Java (java)Dadurch kannst du direkt Klassen wie SAXParserFactory verwenden, ohne java.xml explizit zu importieren:
import module java.sql;
SAXParserFactory factory = SAXParserFactory.newInstance();Code-Sprache: Java (java)Neu in Java 24 (und damit jetzt auch final in Java 25) ist, dass java.base ebenfalls als transitive Abhängigkeit funktioniert – etwa wenn du java.se importierst, das java.base zuvor nicht transitiv eingebunden hatte.
Auswirkungen auf JShell und Compact Source Files
JShell und die sogenannten Compact Source Files, die ebenfalls in Java 25 finalisiert und im nächsten Abschnitt beschrieben werden, importieren nun automatisch java.base. Das reduziert Boilerplate-Code in interaktiven Sessions und in kompakten Quelldateien.
👉 Weitere Hintergründe, praktische Beispiele und tiefergehende Erklärungen findest du im Hauptartikel über Module Import Declarations.
Compact Source Files and Instance Main Methods – JEP 512
Wenn Java-AnfängerInnen ihr erstes Programm schreiben, sieht das häufig so aus:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Code-Sprache: Java (java)Für erfahrene EntwicklerInnen mag das vollkommen selbstverständlich sein – doch EinsteigerInnen werden durch Sichtbarkeitsmodifikatoren wie public, Klassen, statische Methoden, ein ungenutztes args-Array und ein etwas sperriges System.out überfordert.
Mit Java 25 wird all das optional. Compact Source Files and Instance Main Methods – nach vier Preview-Runden mit variierenden Feature-Namen durch JDK Enhancement Proposal 512 finalisiert – ermöglicht kompakte Java-Programme ohne explizite Klassenstruktur:
void main() {
IO.println("Hello world!");
}Code-Sprache: Java (java)Funktionsweise im Detail
Ein Compact Source File ist eine .java-Datei, die keine explizite Klassen- oder Paketdeklaration enthält. Der Java-Compiler erzeugt beim Übersetzen automatisch eine sogenannte implizit deklarierte Klasse. Diese Klasse ist nicht sichtbar und nicht durch andere Klassen referenzierbar.
Die main()-Methode – egal ob in herkömmlichen oder kompakten Quelldateien – muss nicht mehr static oder public sein, und auch der args-Parameter ist optional. Wenn die Methode nicht statisch ist, es sich also um eine Instanzmethode handelt, wird beim Programmstart automatisch eine Instanz der Klasse erzeugt und die main()-Methode dieser Instanz aufgerufen.
Die neue Klasse IO stellt mit print(), println() und readln() die drei wichtigsten Ein- und Ausgabemethoden zur Verfügung. Sie liegt im Paket java.lang und ist damit automatisch in allen Java-Dateien ohne import-Statement verfügbar.
In kompakten Quelldateien wird das Modul java.base automatisch importiert. Damit stehen alle Klassen der von diesem Modul exportierten Pakete unmittelbar (also ohne Imports) zur Verfügung. Mehr Informationen zu Modul-Imports findest du im Abschnitt Module Import Declarations.
Warum ist das wichtig?
Durch diese Neuerungen wird der Einstieg in Java spürbar einfacher. Kompakte Programme wie dieses lassen sich direkt ausführen:
void main() {
IO.println(greet("world"));
}
String greet(String name) {
return "Hello " + name + "!";
}Code-Sprache: Java (java)Die volle Ausdruckskraft der Sprache bleibt erhalten, nur eben mit deutlich geringerem syntaktischem Overhead. Klassen, Modifier, Pakete, Module können dann eingeführt werden, wenn sie gebraucht werden – sobald die Programme größer werden und mehr Struktur erfordern.
Rückblick
In Java 21 wurde das Feature unter dem Namen Unnamed Classes and Instance Main Methods erstmals vorgestellt.
In Java 22 wurde das Konzept der „unbenannten Klassen“ durch „implizit deklarierte Klassen“ ersetzt. Gleichzeitig wurde das Launch-Protokoll vereinfacht, das steuert, welche main()-Methode ausgeführt wird, falls mehrere main()-Methoden existieren.
In Java 23 wurde die java.io.IO-Hilfsklasse eingeführt.
In Java 24 wurde das Feature – ohne sonstige Änderungen – in Simple Source Files and Instance Main Methods umbenannt.
In Java 25 wurde das Feature durch JDK Enhancement Proposal 512 finalisiert und ein letztes Mal umbenannt – in Compact Source Files and Instance Main Methods. Die IO-Klasse, die sich zuvor im Paket java.io befand und deren Methoden automatisch statisch importiert wurden, wandert ins Paket java.lang, und ihre Methoden müssen explizit importiert werden. Somit gibt es keine Sonderregelung mehr für diese eine Klasse.
👉 Weitere Details zur main()-Methode, dem „Launch-Protokoll“ und Spezialfällen findest du im Abschnitt Compact Source Files and Instance Main Method im Artikel über die main()-Methode.
Flexible Constructor Bodies – JEP 513
Konstruktoren in Java waren lange in ihrer Struktur streng limitiert: Vor dem Aufruf von super(…) oder this(…) durfte kein eigener Code stehen. Dadurch entstanden immer wieder teils umständliche Konstruktionen – besonders dann, wenn man Parameter validieren oder vorberechnen wollte.
Das Problem bisher: Umständliche Konstruktor-Logik
Ein Beispiel macht das deutlich:
public class Square extends Rectangle {
public Square(Color color, int area) {
this(color, Math.sqrt(validateArea(area)));
}
private static double validateArea(int area) {
if (area < 0) throw new IllegalArgumentException();
return area;
}
private Square(Color color, double sideLength) {
super(color, sideLength, sideLength);
}
}Code-Sprache: Java (java)Hier muss die Validierung in eine separate Methode und die Umrechnung der Fläche in eine Seitenlänge in einen separaten Konstruktor ausgelagert werden. Warum? Weil (bisher) super(...) immer das erste Statement im Konstruktor sein musste.
Das macht den Code unnötig komplex und schwer lesbar – wie dir sicher beim ersten Blick auf den Code aufgefallen ist ;-)
Flexible Konstruktoren in Java 25
Seit Java 25 gehört dieses Anti-Pattern der Vergangenheit an – dank den durch JDK Enhancement Proposal 513 finalisierten „Flexible Constructor Bodies“.
Ab sofort gilt: Vor dem Aufruf von super(...) oder this(...) darf beliebiger Code stehen – solange er nicht lesend auf noch nicht initialisierte Instanzfelder zugreift.
Das bedeutet:
- Du kannst Parameter validieren.
- Du kannst lokale Variablen berechnen.
- Du darfst sogar Felder initialisieren – und das ist besonders hilfreich, wenn der Super-Konstruktor Methoden aufruft, die in der Subklasse überschrieben wurden.
Das führt zu deutlich lesbarerem Code:
public class Square extends Rectangle {
public Square(Color color, int area) {
if (area < 0) throw new IllegalArgumentException();
double sideLength = Math.sqrt(area);
super(color, sideLength, sideLength);
}
}Code-Sprache: Java (java)Hier ist auf den ersten Blick ersichtlich, was passiert:
- Die Fläche wird validiert.
- Die Seitenlänge wird berechnet
- Der
Rectangle-Konstruktor wird aufgerufen.
Weniger Überraschungen bei Vererbung
Ein häufig unterschätztes Problem was bisher auch das folgende:
Wird im Super-Konstruktor eine Methode aufgerufen, die in der Subklasse überschrieben ist und die dort auf Felder der Subklasse zugreift, kann das zu Überraschungen führen.
Hier ein Beispiel:
public class SuperClass {
public SuperClass() {
logCreation(); // ⟵ 2.
}
protected void logCreation() {
System.out.println("SuperClass created"); // ⟵ not invoked;
// method is overriden in ChildClass
}
}
public class ChildClass extends SuperClass {
private final String parameter;
public ChildClass(String parameter) {
super(); // ⟵ 1.
this.parameter = parameter; // ⟵ 4.
}
@Override
protected void logCreation() {
System.out.println("parameter = " + parameter); // ⟵ 3.
}
}Code-Sprache: Java (java)Ein Aufruf von new ChildClass("foo") würde nicht etwa „SuperClass created“ ausgeben oder „parameter = foo“. Nein, dieser Aufruf würde Folgendes ausgeben:
parameter = nullCode-Sprache: Klartext (plaintext)Der Grund: parameter wird erst in Schritt 4 (s. Quellcode-Kommentare) – also nach dem Aufruf des Super-Konstruktors – gesetzt. Die vom Super-Konstruktor aufgerufene, durch ChildClass überschriebene Methode logCreation() greift daher in Schritt 3 auf ein noch nicht initialisiertes Feld zu.
Mit Flexible Constructor Bodies lässt sich das ganz einfach verhindern:
public ChildClass(String parameter) {
this.parameter = parameter;
super();
}Code-Sprache: Java (java)Wir dürfen Felder nun zuweisen, bevor wir den Super-Konstruktor aufrufen.
Rückblick
Flexible Constructor Bodies starteten in Java 22 unter dem Namen „Statements before super(…)“.
In Java 23 erhielten sie den aktuellen Namen, und es kam die Möglichkeit hinzu Felder vor dem Aufruf des Super-Konstruktors zu initialisieren.
In Java 24 wurde das Feature ohne Änderungen wiedervorgelegt.
Im Java 25 werden sie durch JDK Enhancement Proposal 513 ohne Änderungen finalisiert und können damit in Produktionscode eingesetzt werden.
👉 Weitere Anwendungsfälle, Details und Besonderheiten findest du im Hauptartikel: Flexible Constructor Bodies in Java: Code vor super() aufrufen
Performance-Verbesserungen
Java 25 bringt Performance-Verbesserungen in verschiedenen Bereichen der JVM: Durch Compact Object Headers wird der Speicherverbrauch effizienter gestaltet; durch den Generational Shenandoah wird die Garbage Collection optimiert. Hinzu kommen zwei Erweiterung zum in Java 24 veröffentlichten Ahead-of-Time Class Loading and Linking.
Compact Object Headers – JEP 519
Jedes Java-Objekt enthält neben den eigentlichen Datenfeldern auch einen Objekt-Header. Dieser enthält Metainformationen wie den Hash-Code des Objekts, Sperrinformationen (für Synchronisation), das Objektalter (für die Garbage Collection) und einen Zeiger auf die Klassendatenstruktur.
Bisher war dieser Header in der Regel 12 Byte groß – bei ausgeschalteten Compressed Class Pointers sogar 16 Byte.
Innerhalb von Projekt Lilliput ist es den JDK-EntwicklerInnen gelungen, den Header auf 8 Byte zu verkleinern – ohne dabei Funktionalität einzubüßen. Diese kompaktere Variante nennt sich Compact Object Header und spart erheblich Speicher, insbesondere bei einer großen Anzahl an Objekten.
Aufbau des bisherigen 12-Byte-Objekt-Headers
So sieht der 12-Byte-Header bisher aus:
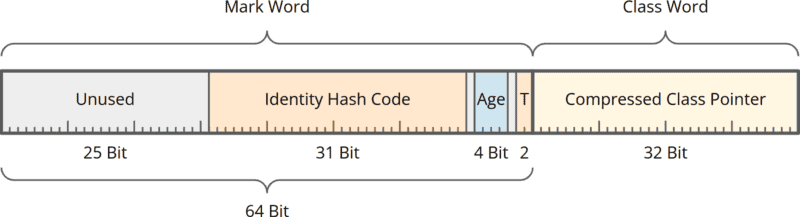
Der 12-Byte-Header besteht aus:
- einem Mark Word, das den Identity Hash Code des Objekts enthält, dessen Alter und zwei sogenannte Tag Bits (für die Synchronisation)
- und einem Class Word mit einem komprimierten Pointer auf die Klassendatenstruktur.
Aufbau des „kompakten“ 8-Byte-Objekt-Headers
Und so ist der neue 8-Byte-Header aufgebaut (Hinweis: Maßstab geändert):
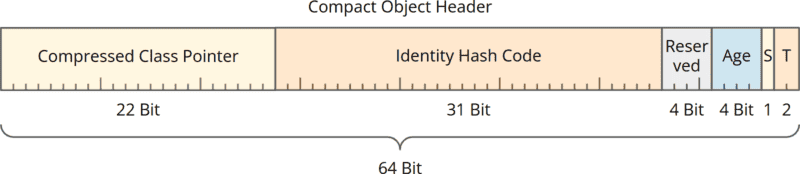
Der Compact Object Header ist nicht mehr in Mark Word und Class Word unterteilt. Er besteht nun aus:
- 22 Bit für den Class Pointer (statt bisher 32),
- 31 Bit für den Identity Hash Code (unverändert),
- 4 reservierte Bits für Project Valhalla,
- 4 Bit für das Objektalter (unverändert),
- 2 Bit für Locking-Informationen (Tag Bits, unverändert),
- 1 Bit für das neue Self Forwarded Tag.
Was wurde geändert?
- Unbenutzte Bits entfernt: Im bisherigen Aufbau gab es 27 ungenutzte Bits im Mark Word – diese wurden entfernt.
- Class Pointer komprimiert: Der 32-Bit-Zeiger auf die Klassendatenstruktur wurde auf 22 Bit reduziert – wie das genau funktioniert, erfährst du im Hauptartikel über Compact Object Headers.
In Java 24 wurden Compact Object Headers als experimentelles Feature vorgestellt. Da sie sich als stabil und performant erwiesen haben, werden sie in Java 25 durch JDK Enhancement Proposal 519 zum produktiven Feature erklärt.
Aktivieren kannst du sie mit folgender VM-Option:
-XX:+UseCompactObjectHeaders
Die zusätzliche Freischaltung experimenteller Features durch -XX:+UnlockExperimentalVMOptions ist in Java 25 nicht mehr erforderlich.
Mehr Details findest du im oben bereits erwähnten Hauptartikel über Compact Object Headers.
Generational Shenandoah – JEP 521
In Java 24 wurde der Generational Mode für den Shenandoah-Garbage-Collector als experimentelles Feature eingeführt.
Ein Generational Garbage Collector macht sich die sogenannte „Schwache Generationshypothese“ zunutze: Die meisten Objekte sterben kurz nach ihrer Erstellung, während langlebige Objekte typischerweise noch länger bestehen bleiben.
Um diese Eigenschaft effizient zu nutzen, unterteilt der Garbage Collector den Heap in zwei Bereiche – eine junge und eine alte Generation. Neue Objekte landen zunächst im Young Space. Nur wenn sie mehrere GC-Zyklen überleben, werden sie in den Old Space verschoben. Aufgrund der erwarteten Stabilität der alten Generation wird diese seltener gescannt – das reduziert die Anzahl unnötiger Scans und verkürzt im Idealfall die Pausenzeiten deutlich.
Diese Strategie ist nicht neu: Der G1 Garbage Collector – seit Java 7 im Einsatz – arbeitet schon immer generationenbasiert. Auch der ZGC verwendet seit Java 23 standardmäßig einen vergleichbaren Ansatz. Mit Java 24 zog Shenandoah nach, zunächst nur im experimentellen Modus. Die Implementierung erwies sich in der Praxis als stabil und leistungsfähig: NutzerInnen berichteten von positiven Ergebnissen bei latenzsensitiven Anwendungen.
In Java 25 wird der Generational Mode nun durch JDK Enhancement Proposal 521 zu einem produktiven Feature erklärt. Du kannst ihn ab sofort wie folgt aktivieren:
-XX:+UseShenandoahGC -XX:ShenandoahGCMode=generational
Die zusätzliche Option -XX:+UnlockExperimentalVMOptions ist nicht mehr erforderlich.
Ahead-of-Time Command-Line Ergonomics – JEP 514
Beim Start einer Java-Anwendung kann es mitunter Sekunden bis Minuten dauern, bis alle Java-Klassen gelesen, geparst, geladen und gelinkt sind. Durch das in Java 24 eingeführte, auf Application Class Data Sharing (AppCDS) basierende, Ahead-of-Time Class Loading and Linking können diese Schritte vor dem Start der Anwendung ausgeführt werden und dadurch der Start der Anwendung signifikant beschleunigt werden.
Der Vorgang bestand bisher aus drei Schritten:
Schritt 1: Im „Record Mode“ analysiert die JVM die Anwendung in einem Trainingslauf und speichert Informationen über die geladenen und gelinkten Klassen in der AOT-Konfiguration (im Beispiel AotTest.conf):
java -XX:AOTMode=record -XX:AOTConfiguration=AotTest.conf \
-cp AotTest.jar eu.happycoders.AotTestCode-Sprache: Klartext (plaintext)Schritt 2: Im „Create Mode“ erzeugt die JVM aus der AOT-Konfiguration den AOT-Cache (AotTest.aot):
java -XX:AOTMode=create -XX:AOTConfiguration=AotTest.conf -XX:AOTCache=AotTest.aot \
-cp AotTest.jarCode-Sprache: Klartext (plaintext)Schritt 3: Bei jedem weiteren Start der Anwendung lädt die JVM die Klassen in geladener und gelinkter Form direkt aus diesem Cache und startet dementsprechend schneller:
java -XX:AOTCache=AotTest.aot -cp AotTest.jar eu.happycoders.AotTestCode-Sprache: MIPS Assembly (mipsasm)(Im oben verlinkten Artikel wirst du Schritt für Schritt durch diesen Prozess geführt.)
JDK Enhancement Proposal 514 führt die neue Kommandozeilen-Option -XX:AOTCacheOutput ein, mit der die ersten beiden Schritte durch ein einziges Kommando ausgeführt werden können:
java -XX:AOTCacheOutput=AotTest.aot -cp AotTest.jar eu.happycoders.AotTestCode-Sprache: Klartext (plaintext)Über die neue Umgebungsvariable JDK_AOT_VM_OPTIONS können VM-Optionen angegeben werden, die nur für den zweiten Teilschritt („Create Mode“) gelten sollen – ohne den ersten Teilschritt, den Trainingslauf („Record Mode“), zu beeinflussen.
Der neue kombinierte Modus ersetzt die zwei alten Modi nicht, da es Use Cases gibt, in denen es sinnvoll sein kann, die Schritte nach wie vor separat auszuführen. Zum Beispiel, wenn Schritt 1 (der Trainingslauf) auf einer kleinen Cloud-Instanz ausgeführt werden soll – Schritt 2 (die Cache-Erzeugung, die durch neue Optimierungen in Zukunft deutlich länger dauern kann) hingegen auf einer leistungsfähigeren Maschine.
Ahead-of-Time Method Profiling – JEP 515
Wenn eine Java-Anwendung läuft, sammelt die JVM kontinuierlich Daten über die aufgerufenen Methoden, insbesondere darüber, welche Methoden die meiste CPU-Zeit benötigen. Diese Methoden werden dann dynamisch optimiert und in Assembler-Code für die Zielplattform übersetzt. Da dieser Vorgang eine Weile dauert, ist eine Java-Anwendung zu Beginn – in der sogenannten Aufwärmphase („warm-up phase“) – langsamer und erreicht ihre volle Leistungsfähigkeit erst nach einigen Sekunden.
Durch Ahead-of-Time Class Loading and Linking wird – wie im vorherigen Abschnitt beschrieben – durch einen Trainingslauf ein AOT-Cache erzeugt, der die von einer Anwendung benötigten Klassen in geladener und gelinkter Form enthält und so den Start einer Anwendung beschleunigt.
JDK Enhancement Proposal 515 erweitert Trainingslauf und AOT-Cache dahingehend, dass zusätzlich zu den binären Klassendaten auch die o. g. Daten über die CPU-Nutzung von Methoden (die sogenannten „Methoden-Profile“) im AOT-Cache gespeichert werden.
Somit können beim Programmstart direkt die am häufigsten aufgerufenen Methoden (die sogenannten „Hotspots“) in Maschinencode übersetzt werden. Dadurch wurden Verbesserungen der Startzeit um bis zu 19 % gemessen, während die Größe des AOT-Caches lediglich um 2,5 % zugenommen hat.
Die Änderungen durch JEP 515 haben keinen Einfluss auf die kontinuierliche Analyse von Methodenaufrufen und die weitere Optimierung zur Laufzeit, sodass die Anwendung auch bei Änderungen ihres Verhaltens im Produktionsbetrieb weiterhin kontinuierlich durch die JVM optimiert wird.
Verbesserungen am Java Flight Recorder (JFR)
Der Java Flight Recorder (JFR) ist ein seit Java 11 in die JVM eingebautes Tool zur Diagnose von Java-Anwendungen. Mit dem JFR lassen sich die Anwendung profilen und bestimmte Ereignisse erfassen, ohne dabei die Leistung der Anwendung wesentlich zu beeinträchtigen.
Java 25 enthält drei Verbesserungen am Java Flight Recorder – davon eine noch im Experimental-Status.
JFR Cooperative Sampling – JEP 518
Eine Funktion des Java Flight Recorders ist das „Profiling“. Dabei geht es nicht um einzelne Events, sondern um Statistiken z. B. darüber, welche Methoden wie viel Zeit in Anspruch nehmen.
Das erfolgt nicht durch exakte Messung, sondern durch sogenanntes „Sampling“: Dabei werden in festen Intervallen die Aufrufstacks aller Threads ausgelesen und gespeichert. Aus den gespeicherten Call Stacks wird dann durch statistische Methoden die ungefähre Aufrufdauer aller Methoden abgeleitet.
Das Auslesen eines genauen Stack Traces ist allerdings nur an sogenannten „Safepoints“ möglich – das sind festgelegte Stellen im Code der JVM, an denen bestimmte, dafür erforderliche Metadaten verfügbar sind. Das Auslesen ausschließlich an diesen Safepoints führt allerdings zum sogenannten „Safepoint Bias“: Wenn oft aufgerufener Code überdurchschnittlich häufig fernab eines Safepoints ausgeführt wird, wird er ungenau gemessen.
Aus diesem Grund wurde das Sampling bisher eben nicht nur an diesen „Safepoints“ durchgeführt. Ohne die an den Safepoints verfügbaren Metadaten mussten allerdings Heuristiken eingesetzt werden, um den Aufrufstack zu generieren. Diese Heuristiken sind jedoch äußerst ineffizient und können im Worst Case die JVM zum Absturz bringen.
Daher wurde durch JDK Enhancement Proposal 518 der Sampling-Mechanismus wie folgt modifiziert:
- An den regelmäßigen Sampling-Intervallen wird nur noch der Program Counter und der Stack Pointer der CPU ausgelesen.
- Stack Traces werden an den darauf folgenden Safepoints ausgelesen.
- Anhand des aufgezeichneten Program Counters und Stack Pointers wird der Aufrufstack zum Sampling-Zeitpunkt rekonstruiert.
Dieser Ansatz ist zum einen performanter, zum anderen unkomplizierter in der Implementierung und dadurch stabiler.
JFR Method Timing & Tracing – JEP 520
Im vorherigen Abschnitt habe ich beschrieben, wie das Profiling des Java Flight Recorders (JFR) funktioniert: Zu bestimmten Zeitpunkten werden Aufrufstacks aller Threads ausgelesen und daraus durch statistische Berechnungen die ungefähren Aufrufhäufigkeiten und -dauern aller Methoden abgeleitet. Dieses Verfahren ist allerdings ungenau und wird nie die exakte Aufrufzahl und -dauer ermitteln können.
Drittanbieter wie JProfiler, YourKit oder DataDog stellen seit jeher Tools zur Verfügung, die sich als sogenannter Java Agent mit der JVM verbinden und in die zu messenden Methoden Code einschleusen, der die Aufrufhäufigkeit und -dauer exakt misst. Das hat natürlich einen gewissen Overhead zur Folge.
Durch JDK Enhancement Proposal 520 wird nun innerhalb der JVM die Möglichkeit geschaffen, Methodenaufrufe und deren Dauer exakt zu messen. Dabei können über Filter bestimmte Klassen, bestimmte Methoden oder Methoden mit bestimmten Annotationen ausgewählt werden. Die Vorteile: höhere Genaugkeit gegenüber Sampling und weniger Overhead gegenüber dem Einsatz von Drittanbieter-Agents.
Mit folgenden Optionen kannst du beispielsweise den StackTrace aller Interaktionen mit HashMaps protokollieren:
java -XX:StartFlightRecording:jdk.MethodTrace#filter=java.util.HashMap,filename=recording.jfr Demo.javaCode-Sprache: Klartext (plaintext)So gibst du dann die StackTraces aus:
jfr print --events jdk.MethodTrace --stack-depth 20 recording.jfrCode-Sprache: Klartext (plaintext)Die Aufrufzeiten hingegen kannst du wie folgt protokollieren und ausgeben:
java -XX:StartFlightRecording:jdk.MethodTiming#filter=java.util.HashMap,filename=recording.jfr Demo.java
jfr print --events jdk.MethodTiming recording.jfrCode-Sprache: Klartext (plaintext)JFR CPU-Time Profiling (Experimental) – JEP 509
Im Abschnitt JFR Cooperative Sampling habe ich beschrieben, wie durch das Auslesen von Stack Traces in festen Intervallen die Aufrufhäufigkeit und -dauer von Methoden abgeleitet werden kann.
Bei den dabei ermittelten Zeiten handelt es sich um die sogenannte Ausführungszeit, also diejenige Zeit, die vom Eintritt in die Methode bis zum Austritt vergangen ist. Diese Zeit ist unabhängig davon, wie die Methode die CPU eingesetzt hat. Eine Methode, die eine Sekunde lang einen Sortieralgorithmus ausführt, und dabei zu 100 % die CPU auslastet, hat die gleiche Ausführungszeit wie eine Methode, die eine Anfrage an die Datenbank schickt und eine Sekunde lang auf die Antwort wartet – was hingegen nur minimale CPU-Ressourcen in Anspruch nimmt.
Diejenige Zeit, während der die Methode die CPU nutzt, wird CPU-Zeit genannt.
Wenn wir wissen, welche Methoden die meiste CPU-Zeit nutzen, können wir diese Methoden optimieren, z. B. indem wir einen Suchalgorithmus gegen einen effizienteren austauschen – und dadurch die CPU-Last der Anwendung reduzieren.
Bisher bat der Java Flight Recorder keine Möglichkeit die CPU-Zeit zu analysieren. Das ändert sich durch JDK Enhancement Proposal 509 – zunächst allerdings nur für Linux.
Durch die neue Option jdk.CPUTimeSample#enabled=true lässt sich das CPU-Zeit-Sampling aktivieren. Mit dem folgenden Kommando beispielsweise startest du eine Java-Anwendung mit aktiviertem CPU-Zeit-Sampling und mit der Ausgabe der gemessenen Daten in die Datei profile.jfr:
java -XX:StartFlightRecording=jdk.CPUTimeSample#enabled=true,filename=profile.jfr ...Code-Sprache: Klartext (plaintext)Die neue Option ist unabhängig von der Option jdk.ExecutionSample#enabled=true, mit der das Ausführungszeit-Sampling aktiviert wird – du kannst also auch beide Sampling-Methoden gleichzeitig aktivieren und damit Ausführungszeiten und CPU-Zeiten messen.
CPU-Time Profiling ist aktuell nur für Linux verfügbar und noch im Experimental-Stadium. Da es sich dabei nicht um eine reguläre VM-Option handelt, sondern um eine JFR-Option, brauchst du zur Aktivierung nicht die VM-Option -XX:+UnlockExperimentalVMOptions angeben.
Neue Preview-Features in Java 25
Auch wenn Java 25 ein Long-Term-Support-Release ist, ist das kein Grund für die JDK-EntwicklerInnen keine neuen Preview-Features zu veröffentlichen. Ein besonders interessantes Preview-Feature sind Stable Values – Werte, die beim ersten Zugriff darauf einmalig initialisiert werden und danach konstant sind, so dass der Zugriff darauf durch die JVM optimiert werden kann.
Preview-Features sind nicht für den produktiven Einsatz gedacht, sondern zum ersten Experimentieren und müssen mit folgender VM-Optionen aktiviert werden:
--enable-preview --source 25
Stable Values (Preview) – JEP 502
Stable Values lösen ein altes Problem – die saubere, performante und threadsichere Initialisierung von Werten, die nicht beim Programmstart gesetzt werden sollen (oder können), sondern erst beim ersten Zugriff darauf.
Warum brauchen wir Stable Values?
Unveränderliche Werte (Immutability) machen Code einfacher, sicherer und ermöglichen der JVM weitreichende Performance-Optimierungen wie z. B. Constant Folding. Bisher war dies nur durch die Markierung eines Feldes als final möglich. Finale Felder werden allerdings sofort beim Laden einer Klasse (finale statische Felder) oder beim Erzeugen eines Objekts (finale Instanzfelder) initialisiert.
Wenn die Initialisierung aber aufwändig oder kontextabhängig ist – etwa weil ein Dienst erst später verfügbar ist –, müssen wir uns mit verschiedenen Varianten der Lazy-Initialisierungen begnügen. Triviale Implementierungen sind oft nicht threadsicher, und threadsichere Varianten, wie z. B. das Double-Checked Locking Idiom sind schwer korrekt zu implementieren und damit fehleranfällig. Im Endeffekt sind alle verfügbaren Lösungen Workarounds und schließen JVM-Optimierungen aus.
Hier ein Beispiel für eine triviale, nicht threadsichere Implementierung, um Programm-Einstellungen beim ersten Zugriff darauf aus einer Datenbank zu laden:
private Settings settings;
private Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}
public Locale getLocale() {
return getSettings().getLocale();
}Code-Sprache: Java (java)Mit synchronized könnten wir die getSettings()-Methode threadsicher machen, das wäre allerdings nicht sehr performant. Eine threadsichere und performante – gleichzeitig aber deutlich komplexere – Variante findest du im Abschnitt Optimiertes Double-Checked Locking in Java im Artikel über das Double-Checked Locking.
Die Lösung: Stable Values
Stable Values schließen die Lücke zwischen final und veränderlich:
- Sie lassen sich genau einmal initialisieren – zu beliebigem Zeitpunkt und threadsicher.
- Danach gelten sie als unveränderlich, sodass die JVM sie wie
final-Felder optimieren kann. - Sie eliminieren typische Fehlerquellen in selbstgebauten Lazy-Initialisierungen.
Hier das Beispiel von oben mit einem Stable Value:
private final Supplier<Settings> settings =
StableValue.supplier(this::loadSettingsFromDatabase);
public Locale getLocale() {
return settings.get().getLocale(); // ⟵ Here we access the stable value
}Code-Sprache: Java (java)Beim ersten Aufruf von settings.get(...) wird loadSettingsFromDatabase() aufgerufen und die Einstellungen innerhalb von settings gespeichert. Alle weiteren Zugriffe liefern dann den gespeicherten Wert. Das ganze läuft threadsicher ab, d. h. wenn get(...) gleichzeitig aus mehreren Threads heraus aufgerufen wird, wird nur in einem der Threads loadSettingsFromDatabase() aufgerufen. Die anderen Threads warten, bis der Wert zur Verfügung steht.
Auch als Liste nutzbar
Mit StableValue.list() lässt sich eine Liste definieren, deren Elemente bei Zugriff initialisiert und danach eingefroren werden. Beispiel:
List<Double> squareRoots = StableValue.list(100, Math::sqrt);Code-Sprache: Java (java)Erst beim ersten Zugriff auf ein Listenelement – sei es mit first(), get(int index), last() oder bei einer Iteration – wird dieses berechnet. Danach bleibt es konstant, und weitere Zugriffe darauf können von der JVM – genau wie Zugriffe auf Konstanten – optimiert werden.
Neben Stable Lists gibt es auch Stable Maps, Stable Functions und Stable IntFunctions.
Die vollständige Stable Value API sowie eine ausführliche Erklärung zur internen Funktionsweise findest du im Hauptartikel über Stable Values (bzw. Lazy Constants, wie sie seit Java 26 heißen). Dort gehe ich auch näher auf die bisherigen Workarounds und deren Nachteile ein.
Stable Values werden durch JDK Enhancement Proposal 502 in Java 25 als Preview-Feature veröffentlicht.
PEM Encodings of Cryptographic Objects (Preview) – JEP 470
PEM (Privacy-Enhanced Mail) ist ein weit verbreitetes Format zur Speicherung von kryptografischen Schlüsseln und Zertifikaten. Ein Zertifikat im PEM-Format sieht z. B. so aus:
-----BEGIN CERTIFICATE-----
MIIDtzCCAz2gAwIBAgISBUCeYELtjMmr4FAIqHapebbFMAoGCCqGSM49BAMDMDIx
CzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQDEwJF
. . .
DBeMde1YpWNXpF9+B/OMKgn7RgXRj5b2QpBCnFsP92T4cK/Nn+xFIjYCMCCx4E79
toSQBlYnNHv0eXnWkI8TmXsU/A6rU4Gxdr9GbGixgRJvkw0C6zjL/lH2Vg==
-----END CERTIFICATE-----Code-Sprache: Klartext (plaintext)Wer schon einmal versucht hat, Schlüssel oder Zertifikate im PEM-Format in eine Java-Anwendung zu importieren oder aus dieser zu exportieren, wird nach mühevoller Stack-Overflow-Recherche festgestellt haben: Java bietet hierfür keine direkte Möglichkeit.
Für das Dekodieren eines verschlüsselten Private Keys im PEM-Format beispielsweise sind über ein Dutzend Code-Zeilen nötig:
String encryptedPrivateKeyPemEncoded = . . .
String passphrase = . . .
String encryptedPrivateKeyBase64Encoded = encryptedPrivateKeyPemEncoded
.replace("-----BEGIN ENCRYPTED PRIVATE KEY-----", "")
.replace("-----END ENCRYPTED PRIVATE KEY-----", "")
.replaceAll("[\\r\\n]", "");
Base64.Decoder decoder = Base64.getDecoder();
byte[] encryptedPrivateKeyBytes = decoder.decode(encryptedPrivateKeyBase64Encoded);
EncryptedPrivateKeyInfo encryptedPrivateKeyInfo =
new EncryptedPrivateKeyInfo(encryptedPrivateKeyBytes);
String algorithmName = encryptedPrivateKeyInfo.getAlgName();
SecretKeyFactory secretKeyFactory = SecretKeyFactory.getInstance(algorithmName);
PBEKeySpec pbeKeySpec = new PBEKeySpec(passphrase.toCharArray());
Key pbeKey = secretKeyFactory.generateSecret(pbeKeySpec);
Cipher cipher = Cipher.getInstance(algorithmName);
AlgorithmParameters algParams = encryptedPrivateKeyInfo.getAlgParameters();
cipher.init(Cipher.DECRYPT_MODE, pbeKey, algParams);
KeyFactory rsaKeyFactory = KeyFactory.getInstance("RSA");
KeySpec keySpec = encryptedPrivateKeyInfo.getKeySpec(cipher);
PrivateKey privateKey = rsaKeyFactory.generatePrivate(keySpec);Code-Sprache: Java (java)Das in Java 25 als Preview vorgestellte Feature PEM Encodings of Cryptographic Objects soll das signifikant vereinfachen. Das Code-Monstrum oben lässt sich in Java 25 mit aktivierten Preview-Features wie folgt vereinfachen:
PrivateKey privateKey = PEMDecoder.of()
.withDecryption(passphrase.toCharArray())
.decode(encryptedPrivateKeyPemEncoded, PrivateKey.class);Code-Sprache: Java (java)Aus 18 Zeilen Code sind drei Zeilen geworden!
Genauso einfach lässt sich ein Private Key verschlüsseln und ins PEM-Format umwandeln:
String encryptedPrivateKeyPemEncoded = PEMEncoder.of()
.withEncryption(passphrase.toCharArray())
.encodeToString(privateKey);Code-Sprache: Java (java)Im Zentrum des neuen Features stehen die Klassen PEMEncoder und PEMDecoder sowie das Interface DEREncodable:
- Alle Klassen, die kryptografische Schlüssel und Zertifikate repräsentieren (wie
PrivateKeyim Beispiel oben), implementieren das neue InterfaceDEREncodable. - Ein
PEMEncoderwird – wie oben gezeigt – mit der statischen MethodePEMEncoder.of()erzeugt. Mit den Instanzmethodenencode(...)undencodeToString(...)lassen sich dann kryptografische Objekte ins PEM-Format umwandeln (binär oder als String). - Ein
PEMDecoderwird mit der statischen MethodePEMDecoder.of()erzeugt. PEM-Dateien lassen sich dann mit derdecode()-Methode in ein kryptografisches Objekt umwandeln. - Die
PEMDecoder.decode()-Methode gibt es auch ohne den zweiten Parameter, der im Beispiel oben den erwarteten RückgabetypPrivateKey.classangibt. Diese Variante gibt einDEREncodablezurück, welches dann z. B. mit Pattern Matching for switch ausgewertet werden kann. - Um einen Private Key zu verschlüsseln, muss der
PEMEncoder– wie im Beispiel oben – mitPEMEncoder.of().withEncryption(passphrase)erzeugt werden. Um ihn wieder zu entschlüsseln muss derPEMDecoderanalog dazu mitPEMDecoder.of().withDecryption(passphrase)erzeugt werden. PEMEncoder- undPEMDecoder-Instanzen sind statuslos und threadsicher – somit kann eine einzige Instanz von mehreren Threads gemeinsam genutzt und wiederverwendet werden.- Sollte die
decode()-Methode die PEM-Daten nicht dekodieren können, wird keine Exception geworfen, sondern ein generischesPEMRecord-Objekt zurückgeliefert, dass die Binärdaten der PEM-Datei enthält.
PEM Encodings of Cryptographic Objects ist in JDK Enhancement Proposal 470 spezifiziert.
Wiedervorgelegte Preview- und Incubator-Features
Drei Features haben es nicht geschafft, in Java 25 finalisiert zu werden und gehen in eine neue Preview- bzw. Incubator-Runde: Structured Concurrency, Primitive Type Patterns und – wenig überraschend – die Vector API.
Structured Concurrency (Fifth Preview) – JEP 505
Wenn eine Aufgabe in mehrere Teilaufgaben zerlegt werden kann, die unabhängig voneinander und parallel ausgeführt werden, kannst du mit Structured Concurrency diese Teilaufgaben klar gegliedert, nachvollziehbar und effizient koordinieren.
Statt komplexer und fehleranfälliger Logik mit z. B. ExecutorService oder parallelen Streams erhalten wir eine API, die Start, Abschluss und Fehlerbehandlung aller Subtasks in einem klar abgegrenzten Codeblock zusammenfasst.
Structured-Concurrency-Scopes lassen sich beliebig verschachteln. So kannst du komplexe Aufgabenstrukturen klar modellieren und behälst dabei jederzeit den Überblick und die Kontrolle über den Lebenszyklus sämtlicher Subtasks:

Mit Java 25 geht Structured Concurrency bereits in die fünfte Preview-Runde – erstmals seit der ersten Preview-Version in Java 21 jedoch mit wesentlichen Änderungen an der API. Die Neuerungen werden in JDK Enhancement Proposal 505 spezifiziert und basieren auf umfangreichem Feedback aus der Community.
Falls du dich noch nicht mit Structured Concurrency beschäftigt hast und daher nicht an den Änderungen interessiert bist, spring gerne direkt zum Abschnitt Beispiel: Die schnellste Antwort gewinnt.
Was ist neu in Java 25?
Die Art und Weise, wie ein StructuredTaskScope geöffnet wird, wurde grundlegend überarbeitet:
- Statt über
newund den Konstruktor wird einStructuredTaskScopenun über die statische Factory-MethodeStructuredTaskScope.open()geöffnet. - Wird
open()ohne Parameter aufgerufen, wird einStructuredTaskScopeerzeugt, der darauf wartet, dass alle Subtasks erfolgreich abgeschlossen sind ... oder ein Subtask fehlschlägt – so wie zuvor die spezialisierte ImplementierungShutdownOnFailure. Ausnew StructuredTaskScope.ShutdownOnFailure()wird somitStructuredTaskScope.open(). - Andere Strategien werden nicht mehr durch Ableiten von
StructuredTaskScopeerzeugt, sondern durch einen sogenannten Joiner, der als Parameter an dieopen()-Methode übergeben wird. - Das
Joiner-Interface definiert statische Factory-Methoden, um Joiner für häufig benötigte Strategien zu erzeugen. Joiner.anySuccessfulResultOrThrow()erzeugt einen Joiner, der ein Ergebnis zurückliefert, sobald der erste Subtask erfolgreich ist – so wie bisher die spezialisierteStructuredTaskScope-ImplementierungShutdownOnSuccess. Aus newStructuredTaskScope.ShutdownOnSuccess()wird somitStructuredTaskScope.open(Joiner.anySuccessfulResultOrThrow()).- Eigene Join-Strategien können durch Implementierung des
Joiner-Interfaces implementiert werden anstatt durch Erweiterung vonStructuredTaskScope.
Zudem wurde der Abschluss der Verarbeitung vereinfacht:
- Die Methode
StructuredTaskScope.result()wurde entfernt – nun liefertStructuredTaskScope.join()das Ergebnis zurück. Aus beispielsweisescope.join(); return scope.result();wird somitreturn scope.join(); - Ebenso wurde die Methode
StructuredTaskScope.throwIfFailed()entfernt – im Falle einer Exception wird diese nun ebenfalls vonStructuredTaskScope.join()geworfen. Das macht die Fehlerbehandlung robuster. StructuredTaskScope.join()wirft im Falle eines Fehlers nicht mehr eine generischeExecutionException, sondern eine Structured-Concurrency-spezifischeFailedExceptionoder eineTimeoutException.
Hier siehst du die Änderung noch mal am Beispiel der race()-Methode, die ich in einigen vorherigen Artikeln gezeigt habe:
Alte Implementierung bis Java 24:
public static <R> R race(Callable<R> task1, Callable<R> task2)
throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<R>()) {
scope.fork(task1);
scope.fork(task2);
scope.join();
return scope.result();
}
}Code-Sprache: Java (java)Neue Implementierung ab Java 25:
public static <R> R race(Callable<R> task1, Callable<R> task2)
throws InterruptedException {
Joiner<R, R> joiner = Joiner.anySuccessfulResultOrThrow();
try (var scope = StructuredTaskScope.open(joiner)) {
scope.fork(task1);
scope.fork(task2);
return scope.join();
}
}Code-Sprache: Java (java)Durch diese Änderungen werden StructuredTaskScope und Join-Strategie entkoppelt, was zu flexiblerem und besser wartbarem Code führt (Stichwort: Composition over inheritance).
Beispiel: Die schnellste Antwort gewinnt
Ein häufiges Szenario ist die parallele Abfrage mehrerer Dienste, bei der die erste gültige Antwort verwendet werden soll – im folgenden Beispiel beim Einholen von Wetterdaten:
WeatherResponse getWeatherFast(Location location) throws InterruptedException {
Joiner<WeatherResponse, WeatherResponse> joiner = Joiner.anySuccessfulResultOrThrow();
try (var scope = StructuredTaskScope.open(joiner)) {
scope.fork(() -> weatherService.readFromStation1(location));
scope.fork(() -> weatherService.readFromStation2(location));
scope.fork(() -> weatherService.readFromStation3(location));
return scope.join();
}
}Code-Sprache: Java (java)Sobald eine der Aufgaben erfolgreich ist, werden die anderen automatisch abgebrochen. Die Methode scope.join() gibt das Ergebnis der ersten erfolgreichen Aufgabe zurück oder wirft eine FailedException, falls keine Aufgabe erfolgreich abgeschlossen wurde.
Ohne Structured Concurrency müsstest du dieselbe Aufgabe mit deutlich mehr Code, manuellem Thread-Handling und eigener Fehlerlogik umsetzen – was nicht nur zeitaufwendiger, sondern auch wesentlich anfälliger für Bugs wäre.
Fazit
Mit JEP 505 macht Structured Concurrency einen großen Schritt Richtung Finalisierung. Die überarbeitete API ist klarer strukturiert, besser verständlich und robuster in der Fehlerbehandlung.
Es zeigt sich einmal mehr, wie wertvoll das Feedback der Java-Community in der Preview-Phase eines Features ist: Nur durch Rückmeldungen aus der Praxis konnten die Schwächen der bisherigen API erkannt und gezielt verbessert werden.
Eine ausführlichere Beschreibung und zahlreiche weitere Beispiele findest du im Hauptartikel über Structured Concurrency.
Primitive Types in Patterns, instanceof, and switch (Third Preview) – JEP 507
Pattern Matching gehört zu den spannendsten Weiterentwicklungen der letzten Jahre. Was mit Pattern Matching for instanceof in Java 16 begann und mit Pattern Matching for switch in Java 21 ausgeweitet wurde, wird nun erweitert – und zwar auf primitive Datentypen wie int, double oder boolean.
Bisher war Pattern Matching auf Referenztypen beschränkt. Also etwa so:
switch (obj) {
case String s when s.length() >= 5 -> System.out.println(s.toUpperCase());
case Integer i -> System.out.println(i * i);
case null, default -> System.out.println(obj);
}Code-Sprache: Java (java)Mit primitiven Werten ging das nicht. Zwar konnte man schon lange primitive Werte wie z. B. int im klassischen switch mit Konstanten vergleichen …
int code = ...
switch (code) {
case 200 -> System.out.println("OK");
case 404 -> System.out.println("Not Found");
}Code-Sprache: Java (java)… aber das funktionierte nur mit byte, short, char und int – nicht jedoch mit long, float, double oder boolean. Und instanceof funktionierte mit primitiven Typen gar nicht.
Durch Primitive Types in Patterns, instanceof, and switch wird sich das ändern:
- Alle primitiven Typen (
int,long,float,double,char,byte,short,boolean) lassen sich nun inswitch-Anweisungen und -Ausdrücken verwenden – sowohl mit Konstanten als auch mit Pattern Matching.
- Pattern Matching mit primitiven Typen ist nun auch mit
instanceofmöglich.
Was bedeutet Pattern Matching mit primitiven Typen genau?
Beim Pattern Matching mit Referenztypen fragt man: „Ist dieses Objekt Instanz von Typ XY oder einer seiner Unterklassen?“ Bei primitiven Typen funktioniert das anders, denn hier gibt es keine Vererbung. Stattdessen wird geprüft: Lässt sich der aktuelle Wert ohne Präzisionsverlust in einem bestimmten Zieltyp darstellen?
Ein Beispiel:
int i = ...
if (i instanceof byte b) {
System.out.println("b = " + b);
}Code-Sprache: Java (java)Hier matcht i auf das Pattern byte b, wenn der Wert auch in einem byte Platz findet. Für i = 100 wäre das der Fall, für i = 500 nicht.
Oder bei Gleitkommazahlen:
double d = ...
if (d instanceof float f) {
System.out.println("f = " + f);
}Code-Sprache: Java (java)Hier gilt: Nur wenn d ohne Präzisionsverlust in einen float passt, matcht das Pattern. Für d = 1.5 klappt das, für d = Math.PI oder d = 16.777.217 hingegen nicht. Beide Zahlen sind zu präzise, um in einer 32-Bit-float-Variablen gespeichert zu werden.
Du kannst – wie bei Referenztypen – zusätzliche Bedingungen anhängen:
int a = ...
if (a instanceof byte b && b > 0) {
System.out.println("b = " + b);
}Code-Sprache: Java (java)In diesem Fall matcht das Pattern nur, wenn a sich verlustfrei als byte darstellen lässt und der Wert zusätzlich größer als 0 ist.
Pattern Matching mit switch und primitiven Typen
Das Ganze funktioniert nicht nur mit instanceof, sondern auch mit switch. Hier ein vollständiges Beispiel:
double value = ...
switch (value) {
case byte b -> System.out.println(value + " instanceof byte: " + b);
case short s -> System.out.println(value + " instanceof short: " + s);
case char c -> System.out.println(value + " instanceof char: " + c);
case int i -> System.out.println(value + " instanceof int: " + i);
case long l -> System.out.println(value + " instanceof long: " + l);
case float f -> System.out.println(value + " instanceof float: " + f);
case double d -> System.out.println(value + " instanceof double: " + d);
}Code-Sprache: Java (java)Abhängig vom konkreten Wert wird jeweils der erste passende Fall ausgeführt:
- Für
value = 42beispielsweise matcht das Patternbyte b, weil sich der Wert ohne Informationsverlust alsbytespeichern lässt. - Für
value = 200passtbytenicht mehr, abershortsehr wohl – also wird dershort s-Zweig ausgeführt. - Für
value = 65000greiftshortebenfalls nicht mehr, aberchar c, dacharWerte von 0 bis 65.535 abbilden kann. - Für
value = 500000sindbyte,shortundcharzu klein – hier passtint i. - Für
value = 3.14ist keine Ganzzahl-Darstellung möglich, aber der Wert passt ohne Genauigkeitsverlust in einenfloat, also wird der Branch hinterfloat fausgeführt. - Für
value = Math.PIbleibt nur nochdouble d, daMath.PIfürfloatzu präzise ist.
Wie bei Objekttypen gilt auch hier: Du musst alle Fälle abdecken oder einen default-Branch angeben, um eine vollständige (exhaustive) Prüfung sicherzustellen.
Feinheiten: Dominanz und Vollständigkeit
Auch bei primitiven Typen spielt das Prinzip der Dominanz eine wichtige Rolle: Ein int-Wert passt grundsätzlich auch in einen long, daher würde ein Pattern long l alle int-Werte ebenfalls abfangen – und darf daher nicht vor einem Pattern int i im Code stehen.
Zusätzlich gilt – wie bei allen modernen switch-Features – die Regel der Vollständigkeit: Der switch-Block muss alle theoretisch möglichen Fälle abdecken. Falls das nicht möglich oder nicht sinnvoll ist, musst du einen default-Zweig definieren, um Compiler-Fehler zu vermeiden.
Mehr zu den genauen Regeln für Dominanz und Exhaustiveness sowie weitere Beispiele und Besonderheiten findest du im Hauptartikel Primitive Typen in Patterns, instanceof und switch.
Rückblick
Primitive Types in Patterns, instanceof, and switch wurde erstmals in Java 23 durch JEP 455 eingeführt und in Java 24 durch JEP 488 ohne Änderungen als Preview wiedervorgestellt. In Java 25 geht es nun, spezifiziert durch JDK Enhanacement Proposal 507, in die dritte Preview-Runde – erneut ohne Änderungen, um weiteres Feedback der Java-Community einzuholen.
Vector API (Tenth Incubator) – JEP 508
Die Vector API wird mit Java 25 bereits zum zehnten Mal im Incubator-Stadium vorgestellt – spezifiziert durch JDK Enhancement Proposal 508.
Die API ermöglicht es, mathematische Vektoroperationen wie die folgende besonders effizient auszuführen:
Die JVM kann diese Operationen so abbilden, dass sie – je nach Vektorgröße – direkt auf die Vektor-Instruktionssätze moderner CPUs zugreifen. In vielen Fällen lässt sich eine solche Berechnung dadurch in einem einzigen CPU-Zyklus ausführen.
Die Vector API bleibt ein Incubator-Feature bis die von ihr benötigten Bausteine aus Project Valhalla das Preview-Stadium erreicht haben. Sobald die Vector API in einer ersten Preview-Version vorliegt, werde ich sie ausführlich und mit Praxisbeispielen beschreiben.
Sonstige Änderungen in Java 25
In diesem Abschnitt findest du Änderungen, die sich nicht in die anderen Kapitel einsortieren ließen. Es handelt sich dabei um weniger prominente JEPs, um Entfernungen und um einige (von mir aus den Release Notes ausgewählte) kleinere Änderungen, die ohne JEP umgesetzt wurden.
Key Derivation Function API – JEP 510
Mit einer Key Derivation Function (KDF) lassen sich aus einem geheimen Eingabewert – etwa einem Passwort, einer Passphrase oder einem bestehenden Schlüssel – weitere kryptographische Schlüssel ableiten.
Damit KDFs konsistent genutzt und von Sicherheitsanbietern implementiert werden können, bedarf es einer standardisierten Schnittstelle. Genau das liefert JDK Enhancement Proposal 510 mit der Key Derivation Function API und der Klasse javax.crypto.KDF.
Über diese API kannst du verschiedene KDF-Algorithmen laden und verwenden. Im folgenden Beispiel nutzen wir „HKDF-SHA256“, um aus einem Passwort und einem Salt einen AES-Schlüssel abzuleiten:
void main() throws InvalidAlgorithmParameterException, NoSuchAlgorithmException {
KDF hkdf = KDF.getInstance("HKDF-SHA256");
AlgorithmParameterSpec params =
HKDFParameterSpec.ofExtract()
.addIKM("the super secret passphrase".getBytes(StandardCharsets.UTF_8))
.addSalt("the salt".getBytes(StandardCharsets.UTF_8))
.thenExpand("my derived key".getBytes(StandardCharsets.UTF_8), 32);
SecretKey key = hkdf.deriveKey("AES", params);
System.out.println("key = " + HexFormat.of().formatHex(key.getEncoded()));
}Code-Sprache: Java (java)Falls du dich über die kompakte main()-Methode wunderst: Diese ist Teil der Neuerungen, die im Abschnitt Compact Source Files and Instance Main Methods behandelt werden.
Erklärungen zu den im Code vorkommenden Abkürzungen findest du in den folgenden Wikipedia-Artikeln:
- HKDF steht für „HMAC-based Key Derivation Function“.
- HMAC bedeutet „Hash-based Message Authentication Code“.
- IKM bezeichnet das „input key material“, also z. B. das Passwort.
- AES ist der „Advanced Encryption Standard“, ein verbreiteter Verschlüsselungsalgorithmus.
Wenn du das Beispiel ausführst, solltest du folgende Ausgabe erhalten:
key = 7ee15549ddce956194ca1d6df5aa34c1a1334d15c875e67ea67fb5850ee48b0cCode-Sprache: Klartext (plaintext)Der so erzeugte Schlüssel lässt sich beispielsweise als Session Key für eine sichere Datenübertragung einsetzen.
Die Key Derivation Function API wurde in Java 24 erstmals als Preview-Feature eingeführt und ist ab Java 25 nun fester Bestandteil des JDK, ohne Änderungen gegenüber der Preview-Version.
Remove the 32-bit x86 Port – JEP 503
Nachdem in Java 24 der 32-Bit-Port für Windows entfernt wurde, wird in Java 25 durch JDK Enhancement Proposal 503 auch die letzte verbleibende 32-Bit-Variante – die für Linux – vollständig entfernt.
So wird der Extraaufwand für das Entwickeln und Testen der 32-Bit-Portierungen eliminiert, und die JDK-Developer können sich voll und ganz auf neue Features fokussieren.
Relax String Creation Requirements in StringBuilder and StringBuffer
Die Spezifikationen der substring()-, subSequence()- und toString()-Methoden der Klassen StringBuilder und StringBuffer erforderten bisher, dass immer ein neu erstelltes String-Objekt zurückgegeben wird. Diese Anforderung wurde aus der Spezifikation entfernt, so dass diese Methoden nun z. B. für einen leeren String eine ""-Konstante zurückgeben können, was schneller ist, als einen neuen leeren String zu erzeugen.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8138614 aufgeführt.
New Methods on BodyHandlers and BodySubscribers To Limit The Number of Response Body Bytes Accepted By The HttpClient
Die Klassem java.net.http.HttpResponse.BodyHandlers und java.net.http.HttpResponse.BodySubsribers wurden um je eine limiting()-Methode erweitert, mit der die Größe einer Antwort auf eine HTTP-Anfrage begrenzt werden kann.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8328919 aufgeführt.
The UseCompressedClassPointers Option is Deprecated
Standardmäßig arbeitet die JVM mit Compressed Class Pointers – das sind auf 32 Bit komprimierte Pointer im Objekt-Header, die auf die zum Objekt gehörige Klassendatenstruktur zeigen.
Bevor Compressed Class Pointers eingeführt wurden, waren diese Pointer auf 64-Bit-Systemen 64 Bit lang. Dieser Modus lässt sich aktuell noch durch -XX:-UseCompressedClassPointers reaktivieren. Das ist allerdings faktisch irrelevant, denn 32-Bit-Pointer reichen aus, um 4 GB und damit ca. 6 Millionen Klassen zu addressieren. Selbst große Java-Anwendungen zählen selten mehr als 100.000 Klassen.
Durch die in Java 25 produktiv geschalteten Compact Object Headers werden Class Pointer weiter komprimiert auf nur 22 Bit, womit sich ca. 4 Millionen – also immer noch ausreichend – Klassen adressieren lassen.
Der Support für unkomprimierte Klassenpointer soll in einer zukünftigen Java-Version entfernt werden. Entsprechend wurde die Option UseCompressedClassPointers in Java 25 als deprecated markiert.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8350753 aufgeführt.
Various Permission Classes Deprecated for Removal
In Java 17 wurde der Security Manager deprecated for removal gekennzeichnet. Seit Java 24 kann der Security Manager nicht mehr aktiviert werden.
In Java 25 wurden nun zahlreiche ...Permission-Klassen, die nur im Zusammenhang mit dem Security Manager verwendbar waren, ebenfalls als deprecated for removal markiert.
Welche Klassen das im Detail sind, kannst du im Bug-Tracker unter JDK-8348967, JDK-8353641, JDK-8353642 und JDK-8353856 nachlesen.
Syntax Highlighting for Code Fragments
Das javadoc-Tool wurde um die Kommandozeilenoption --syntax-highlight erweitert. Wird diese beim Aufruf des javadoc-Kommandos angegeben, wird die Library Highlight.js in die generierte Dokumentation eingebunden und der Code in {@snippet} tags und HTML-Elementen entsprechend farblich gekennzeichnet.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8348282 aufgeführt.
Mit Java 25 generierte JavaDoc-Dokumentation lässt sich nun mit der Tastatur navigieren:
/fokussiert das Suchfeld oben rechts..fokussiert das Filterfeld in der Sidebar.Escentfernt den Fokus aus dem Such- oder Filterfeld.- Mit
Tabund den Pfeiltasten kannst du in der Sidebar und den Suchergebnissen navigieren.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8350638 aufgeführt.
Add Standard System Property stdin.encoding
Über die neue System Property stdin.encoding kann der Zeichensatz für das Lesen von System.in festgelegt werden. Wenn nicht explizit angegeben – z. B. durch -Dstdin.encoding=UTF-8 –, wird der Wert durch das Betriebssystem und die Benutzerumgebung ermittelt.
Beachte, dass diese Einstellung nicht automatisch verwendet wird, sondern explizit von einer Anwendung ausgelesen und angewendet werden muss, z. B. bei Verwendung von InputStreamReader oder Scanner.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8350703 aufgeführt.
The jwebserver Tool -d Command Line Option Now Accepts Directories Specified With a Relative Path
In Java 18 wurde der sogenannte Simple Web Server eingeführt – ein rudimentärer HTTP-Server, der schnell hochgefahren werden kann, um statische Webseiten auszuliefern.
Das folgende Kommando z. B. liefert das /tmp-Verzeichnis an IP-Adresse 127.0.0.100 und Port 4444 aus:
jwebserver -b 127.0.0.100 -p 4444 -d /tmpCode-Sprache: Klartext (plaintext)Dabei musste (über den Parameter -d) bisher immer ein absoluter Pfad angegeben werden – umständlich, wenn man innerhalb des aktuellen Projekts ein Verzeichnis per HTTP freigeben möchte. Ab Java 25 darf nun auch ein relativer Verzeichnisname angegeben werden.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8355360 aufgeführt.
java.io.File treats the empty pathname as the current user directory
Ein mit new File("") erzeugtes java.io.File-Objekt führte bisher zu undefiniertem und inkonsistentem Verhalten beim Aufruf von Methoden auf diesem Objekt. Ab Java 25 wird damit ein File-Objekt erzeugt, das das aktuelle Verzeichnis repräsentiert.
Damit wird das Verhalten von File an java.nio.Path angepasst – Path.of("") erzeugte schon immer eine Repräsentation des aktuellen Verzeichnisses.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8024695 aufgeführt.
java.io.File.delete no longer deletes read-only files on Windows
Bisher konnte man durch einen Aufruf von File.delete() unter Windows auch solche Dateien löschen, die als „Read-only“ markiert waren. Ab Java 25 werden solche Dateien nicht mehr gelöscht, und delete() gibt entsprechend false zurück.
Das bisherige Verhalten kann mit der System Property -Djdk.io.File.allowDeleteReadOnlyFiles=true wiederhergestellt werden.
Für diese Änderung gibt es keinen JEP; sie wird im Bug-Tracker unter JDK-8355954 aufgeführt.
Vollständige Liste aller Änderungen in Java 25
In diesem Artikel habe ich dir alle JDK Enhancement Proposals (JEPs) sowie eine Auswahl weiterer Änderungen ohne JEP vorgestellt, die in Java 25 umgesetzt wurden. Eine vollständige Auflistung aller Änderungen findest du in den Java 25 Release Notes.
Fazit
Java 25 ist wieder einmal ein rundum gelungenes LTS (Long-Term-Support) Release.
- Mit Scoped Values ist das zweite Feature aus Project Loom finalisiert worden. Schade, dass es Structured Concurrency nicht in dieses Release geschafft hat – aber dank des 6-monatigen Release-Zyklus bekommen wir lieber etwas später ein ausgereiftes Feature als zu früh ein unausgereiftes.
- Module Import Declarations machen den Import-Block übersichtlicher – es bleibt abzuwarten, inwieweit dies (außerhalb von JShell und kompakten Quelldateien) angenommen wird – kümmert sich doch heutzutage in erster Linie die IDE um die Verwaltung der Imports.
- Compact Source Files and Instance Main Methods lassen uns schneller kurze Test- und Demoprogramme schreiben. Sie sollen außerdem das Erlernen der Sprache für EinsteigerInnen vereinfachen.
- Flexible Constructor Bodies erlauben uns endlich, in Konstruktoren Code auch vor dem Aufruf von
super()oderthis()aufzurufen und machen damit unschöne Workarounds, z. B. zur Überprüfung von Parametern vor dem Aufruf des Super-Konstruktors hinfällig. - Compact Object Headers reduzieren den Objekt-Header von 12 auf 8 Byte und reduzieren damit den Memory-Footprint insbesondere von Anwendungen mit vielen kleinen Objekte.
- Generational Shenandoah beschleunigt Anwendungen, die den Shanandoah Garbage Collector einsetzen. Konkrete Zahlen werden allerdings in den JEPs nicht genannt.
- Ahead-of-Time Command-Line Ergonomics vereinfachen die Erstellung eines AOT-Caches, und durch Ahead-of-Time Method Profiling werden auch Informationen über Methodenaufrufe im AOT-Cache gespeichert, was zu deutlichen Verbesserungen der Startzeit führen kann, da so häufig aufgerufene Methoden sofort optimiert werden können.
Weitere kleinere Änderungen runden das LTS-Release wie immer ab. Du kannst Java 25 hier herunterladen.
Auf welches Java-25-Feature freust du dich am meisten? Schreib es in die Kommentare!